 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Neural Network-guided PSO for Tracking a Global Optimal Position in Complex Dynamic Environment
Apr 15, 2026We propose novel particle swarm optimization (PSO) variants incorporated with deep neural networks (DNNs) for particles to pursue globally optimal positions in dynamic environments. PSO is a heuristic approach for solving complex optimization problems. However, canonical PSO and its variants struggle to adapt efficiently to dynamic environments, in which the global optimum moves over time, and to track them accurately. Many PSO algorithms improve convergence by increasing the swarm size beyond potential optima, which are global/local optima but are not identified until they are discovered. Additionally, in dynamic environments, several methods use multiple sub-population and re-diversification mechanisms to address outdated memory and local optima entrapment. To track the global optimum in dynamic environments with smaller swarm sizes, the DNNs in our methods determine particle movement by learning environmental characteristics and adapting dynamics to pursue moving optimal positions. This enables particles to adapt to environmental changes and predict the moving optima. We propose two variants: a swarm with a centralized network and distributed networks for all particles. Our experimental results show that both variants can track moving potential optima with lower cumulative tracking error than those of several recent PSO-based algorithms, with fewer particles than potential optima.
Robust and Efficient Communication in Multi-Agent Reinforcement Learning
Nov 14, 2025Multi-agent reinforcement learning (MARL) has made significant strides in enabling coordinated behaviors among autonomous agents. However, most existing approaches assume that communication is instantaneous, reliable, and has unlimited bandwidth; these conditions are rarely met in real-world deployments. This survey systematically reviews recent advances in robust and efficient communication strategies for MARL under realistic constraints, including message perturbations, transmission delays, and limited bandwidth. Furthermore, because the challenges of low-latency reliability, bandwidth-intensive data sharing, and communication-privacy trade-offs are central to practical MARL systems, we focus on three applications involving cooperative autonomous driving, distributed simultaneous localization and mapping, and federated learning. Finally, we identify key open challenges and future research directions, advocating a unified approach that co-designs communication, learning, and robustness to bridge the gap between theoretical MARL models and practical implementations.
Reducing Redundant Computation in Multi-Agent Coordination through Locally Centralized Execution
Apr 19, 2024



In multi-agent reinforcement learning, decentralized execution is a common approach, yet it suffers from the redundant computation problem. This occurs when multiple agents redundantly perform the same or similar computation due to overlapping observations. To address this issue, this study introduces a novel method referred to as locally centralized team transformer (LCTT). LCTT establishes a locally centralized execution framework where selected agents serve as leaders, issuing instructions, while the rest agents, designated as workers, act as these instructions without activating their policy networks. For LCTT, we proposed the team-transformer (T-Trans) architecture that allows leaders to provide specific instructions to each worker, and the leadership shift mechanism that allows agents autonomously decide their roles as leaders or workers. Our experimental results demonstrate that the proposed method effectively reduces redundant computation, does not decrease reward levels, and leads to faster learning convergence.
User's Position-Dependent Strategies in Consumer-Generated Media with Monetary Rewards
Oct 07, 2023

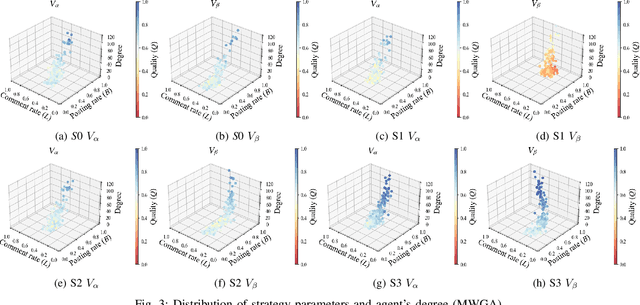

Numerous forms of consumer-generated media (CGM), such as social networking services (SNS), are widely used. Their success relies on users' voluntary participation, often driven by psychological rewards like recognition and connection from reactions by other users. Furthermore, a few CGM platforms offer monetary rewards to users, serving as incentives for sharing items such as articles, images, and videos. However, users have varying preferences for monetary and psychological rewards, and the impact of monetary rewards on user behaviors and the quality of the content they post remains unclear. Hence, we propose a model that integrates some monetary reward schemes into the SNS-norms game, which is an abstraction of CGM. Subsequently, we investigate the effect of each monetary reward scheme on individual agents (users), particularly in terms of their proactivity in posting items and their quality, depending on agents' positions in a CGM network. Our experimental results suggest that these factors distinctly affect the number of postings and their quality. We believe that our findings will help CGM platformers in designing better monetary reward schemes.
Effect of Monetary Reward on Users' Individual Strategies Using Co-Evolutionary Learning
Jun 01, 2023


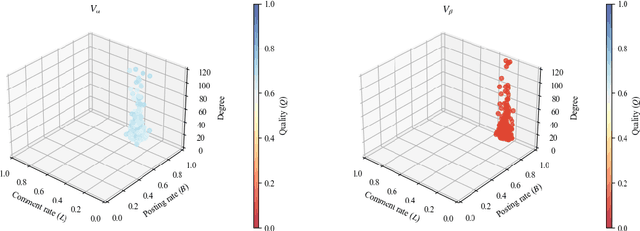
Consumer generated media (CGM), such as social networking services rely on the voluntary activity of users to prosper, garnering the psychological rewards of feeling connected with other people through comments and reviews received online. To attract more users, some CGM have introduced monetary rewards (MR) for posting activity and quality articles and comments. However, the impact of MR on the article posting strategies of users, especially frequency and quality, has not been fully analyzed by previous studies, because they ignored the difference in the standpoint in the CGM networks, such as how many friends/followers they have, although we think that their strategies vary with their standpoints. The purpose of this study is to investigate the impact of MR on individual users by considering the differences in dominant strategies regarding user standpoints. Using the game-theoretic model for CGM, we experimentally show that a variety of realistic dominant strategies are evolved depending on user standpoints in the CGM network, using multiple-world genetic algorithm.
Interpretability for Conditional Coordinated Behavior in Multi-Agent Reinforcement Learning
Apr 20, 2023



We propose a model-free reinforcement learning architecture, called distributed attentional actor architecture after conditional attention (DA6-X), to provide better interpretability of conditional coordinated behaviors. The underlying principle involves reusing the saliency vector, which represents the conditional states of the environment, such as the global position of agents. Hence, agents with DA6-X flexibility built into their policy exhibit superior performance by considering the additional information in the conditional states during the decision-making process. The effectiveness of the proposed method was experimentally evaluated by comparing it with conventional methods in an objects collection game. By visualizing the attention weights from DA6-X, we confirmed that agents successfully learn situation-dependent coordinated behaviors by correctly identifying various conditional states, leading to improved interpretability of agents along with superior performance.
Distributed Planning with Asynchronous Execution with Local Navigation for Multi-agent Pickup and Delivery Problem
Feb 18, 2023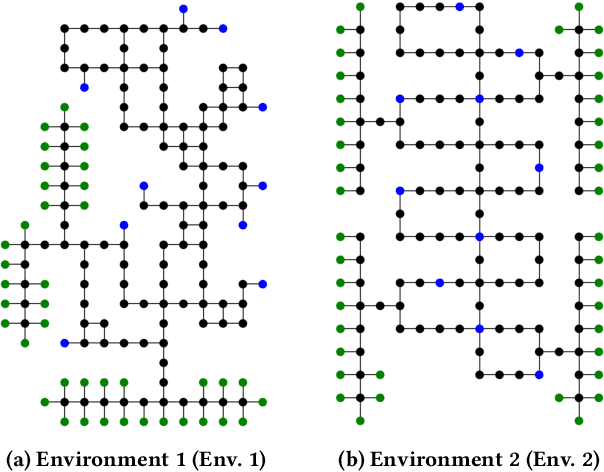



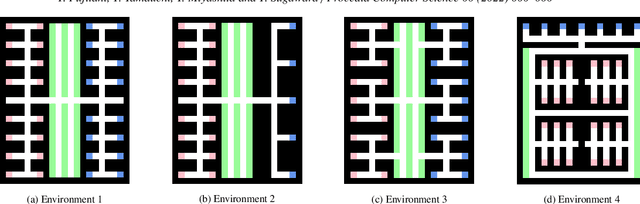
We propose a distributed planning method with asynchronous execution for multi-agent pickup and delivery (MAPD) problems for environments with occasional delays in agents' activities and flexible endpoints. MAPD is a crucial problem framework with many applications; however, most existing studies assume ideal agent behaviors and environments, such as a fixed speed of agents, synchronized movements, and a well-designed environment with many short detours for multiple agents to perform tasks easily. However, such an environment is often infeasible; for example, the moving speed of agents may be affected by weather and floor conditions and is often prone to delays. The proposed method can relax some infeasible conditions to apply MAPD in more realistic environments by allowing fluctuated speed in agents' actions and flexible working locations (endpoints). Our experiments showed that our method enables agents to perform MAPD in such an environment efficiently, compared to the baseline methods. We also analyzed the behaviors of agents using our method and discuss the limitations.
Deadlock-Free Method for Multi-Agent Pickup and Delivery Problem Using Priority Inheritance with Temporary Priority
May 25, 2022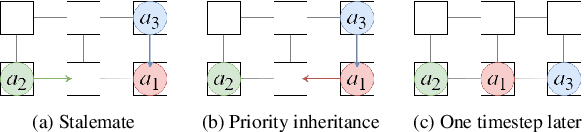

This paper proposes a control method for the multi-agent pickup and delivery problem (MAPD problem) by extending the priority inheritance with backtracking (PIBT) method to make it applicable to more general environments. PIBT is an effective algorithm that introduces a priority to each agent, and at each timestep, the agents, in descending order of priority, decide their next neighboring locations in the next timestep through communications only with the local agents. Unfortunately, PIBT is only applicable to environments that are modeled as a bi-connected area, and if it contains dead-ends, such as tree-shaped paths, PIBT may cause deadlocks. However, in the real-world environment, there are many dead-end paths to locations such as the shelves where materials are stored as well as loading/unloading locations to transportation trucks. Our proposed method enables MAPD tasks to be performed in environments with some tree-shaped paths without deadlock while preserving the PIBT feature; it does this by allowing the agents to have temporary priorities and restricting agents' movements in the trees. First, we demonstrate that agents can always reach their delivery without deadlock. Our experiments indicate that the proposed method is very efficient, even in environments where PIBT is not applicable, by comparing them with those obtained using the well-known token passing method as a baseline.
Distributed Multi-Agent Deep Reinforcement Learning for Robust Coordination against Noise
May 19, 2022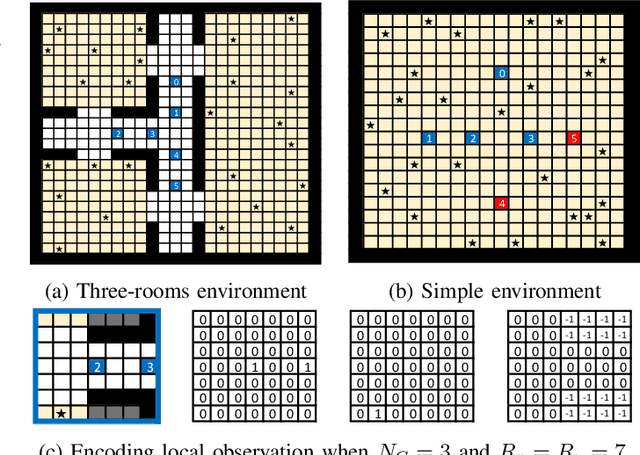
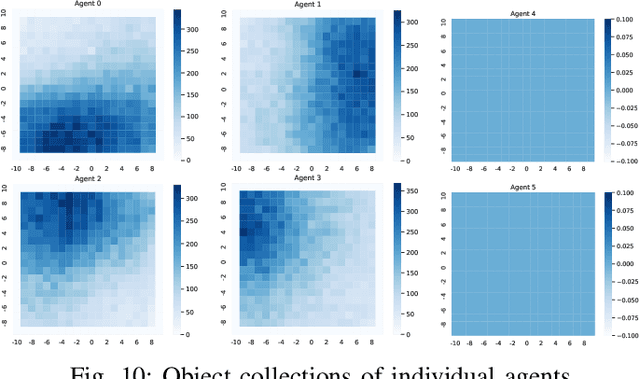
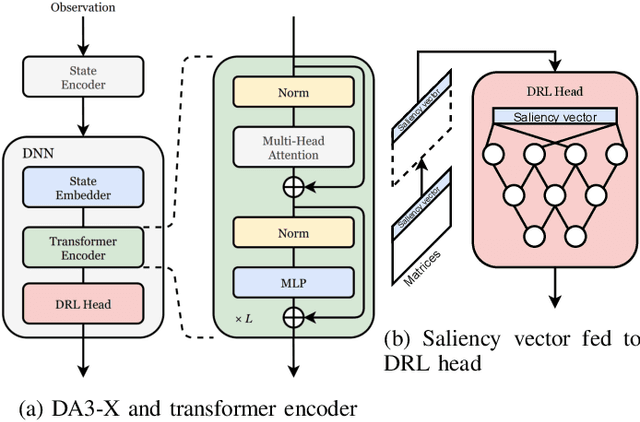
In multi-agent systems, noise reduction techniques are important for improving the overall system reliability as agents are required to rely on limited environmental information to develop cooperative and coordinated behaviors with the surrounding agents. However, previous studies have often applied centralized noise reduction methods to build robust and versatile coordination in noisy multi-agent environments, while distributed and decentralized autonomous agents are more plausible for real-world application. In this paper, we introduce a \emph{distributed attentional actor architecture model for a multi-agent system} (DA3-X), using which we demonstrate that agents with DA3-X can selectively learn the noisy environment and behave cooperatively. We experimentally evaluate the effectiveness of DA3-X by comparing learning methods with and without DA3-X and show that agents with DA3-X can achieve better performance than baseline agents. Furthermore, we visualize heatmaps of \emph{attentional weights} from the DA3-X to analyze how the decision-making process and coordinated behavior are influenced by noise.
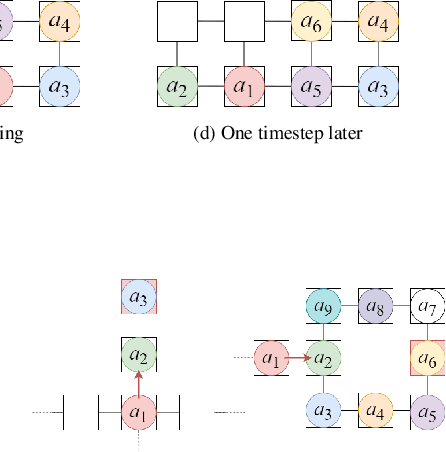
Standby-Based Deadlock Avoidance Method for Multi-Agent Pickup and Delivery Tasks
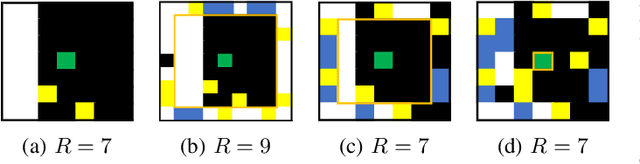
Jan 19, 2022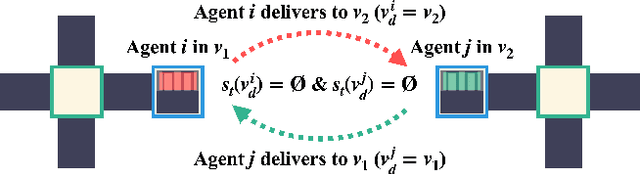
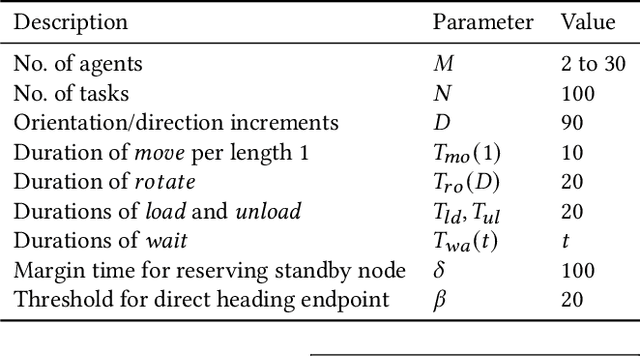

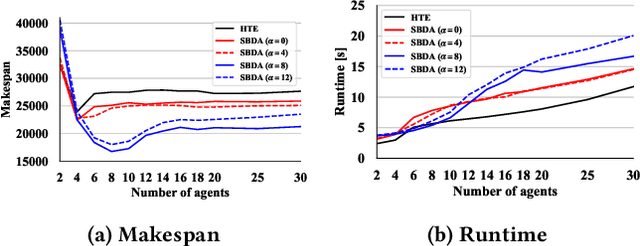
The multi-agent pickup and delivery (MAPD) problem, in which multiple agents iteratively carry materials without collisions, has received significant attention. However, many conventional MAPD algorithms assume a specifically designed grid-like environment, such as an automated warehouse. Therefore, they have many pickup and delivery locations where agents can stay for a lengthy period, as well as plentiful detours to avoid collisions owing to the freedom of movement in a grid. By contrast, because a maze-like environment such as a search-and-rescue or construction site has fewer pickup/delivery locations and their numbers may be unbalanced, many agents concentrate on such locations resulting in inefficient operations, often becoming stuck or deadlocked. Thus, to improve the transportation efficiency even in a maze-like restricted environment, we propose a deadlock avoidance method, called standby-based deadlock avoidance (SBDA). SBDA uses standby nodes determined in real-time using the articulation-point-finding algorithm, and the agent is guaranteed to stay there for a finite amount of time. We demonstrated that our proposed method outperforms a conventional approach. We also analyzed how the parameters used for selecting standby nodes affect the performance.