 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA High-Performance Implementation of Bayesian Matrix Factorization with Limited Communication
Apr 14, 2020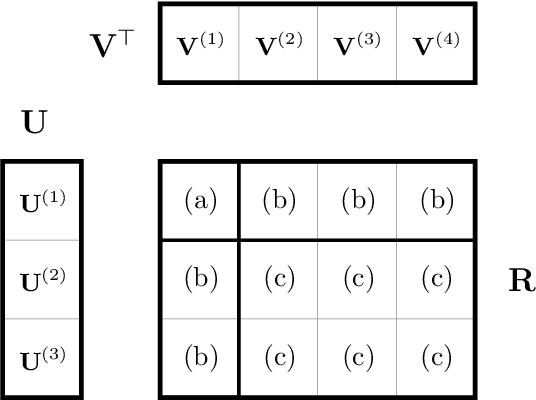
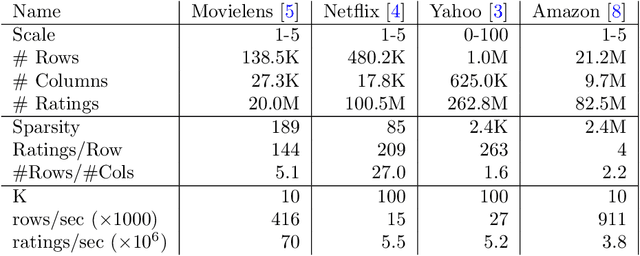
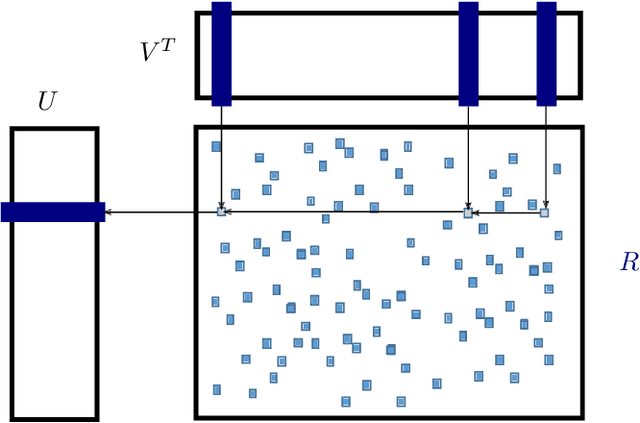
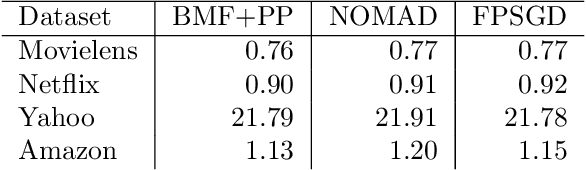
Matrix factorization is a very common machine learning technique in recommender systems. Bayesian Matrix Factorization (BMF) algorithms would be attractive because of their ability to quantify uncertainty in their predictions and avoid over-fitting, combined with high prediction accuracy. However, they have not been widely used on large-scale data because of their prohibitive computational cost. In recent work, efforts have been made to reduce the cost, both by improving the scalability of the BMF algorithm as well as its implementation, but so far mainly separately. In this paper we show that the state-of-the-art of both approaches to scalability can be combined. We combine the recent highly-scalable Posterior Propagation algorithm for BMF, which parallelizes computation of blocks of the matrix, with a distributed BMF implementation that users asynchronous communication within each block. We show that the combination of the two methods gives substantial improvements in the scalability of BMF on web-scale datasets, when the goal is to reduce the wall-clock time.
Guidelines for enhancing data locality in selected machine learning algorithms
Jan 09, 2020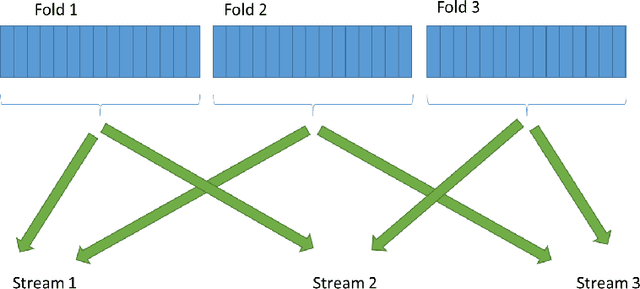

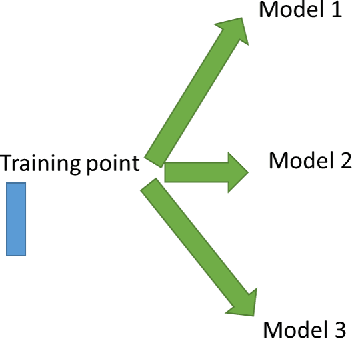
To deal with the complexity of the new bigger and more complex generation of data, machine learning (ML) techniques are probably the first and foremost used. For ML algorithms to produce results in a reasonable amount of time, they need to be implemented efficiently. In this paper, we analyze one of the means to increase the performances of machine learning algorithms which is exploiting data locality. Data locality and access patterns are often at the heart of performance issues in computing systems due to the use of certain hardware techniques to improve performance. Altering the access patterns to increase locality can dramatically increase performance of a given algorithm. Besides, repeated data access can be seen as redundancy in data movement. Similarly, there can also be redundancy in the repetition of calculations. This work also identifies some of the opportunities for avoiding these redundancies by directly reusing computation results. We start by motivating why and how a more efficient implementation can be achieved by exploiting reuse in the memory hierarchy of modern instruction set processors. Next we document the possibilities of such reuse in some selected machine learning algorithms.
* European Commission Project: EPEEC - European joint Effort toward a Highly Productive Programming Environment for Heterogeneous Exascale Computing (EC-H2020-80151) This an extended version of arXiv:1904.11203
Reviewing Data Access Patterns and Computational Redundancy for Machine Learning Algorithms
Apr 25, 2019

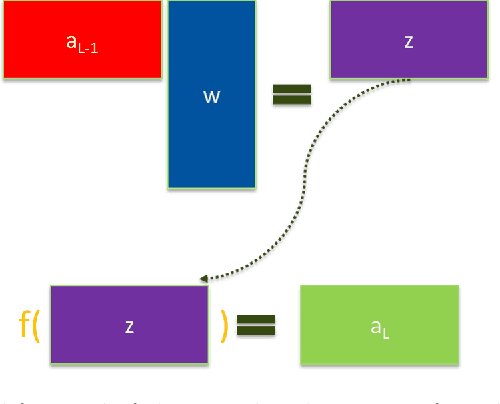
Machine learning (ML) is probably the first and foremost used technique to deal with the size and complexity of the new generation of data. In this paper, we analyze one of the means to increase the performances of ML algorithms which is exploiting data locality. Data locality and access patterns are often at the heart of performance issues in computing systems due to the use of certain hardware techniques to improve performance. Altering the access patterns to increase locality can dramatically increase performance of a given algorithm. Besides, repeated data access can be seen as redundancy in data movement. Similarly, there can also be redundancy in the repetition of calculations. This work also identifies some of the opportunities for avoiding these redundancies by directly reusing computation results. We document the possibilities of such reuse in some selected machine learning algorithms and give initial indicative results from our first experiments on data access improvement and algorithm redesign.
SMURFF: a High-Performance Framework for Matrix Factorization
Apr 04, 2019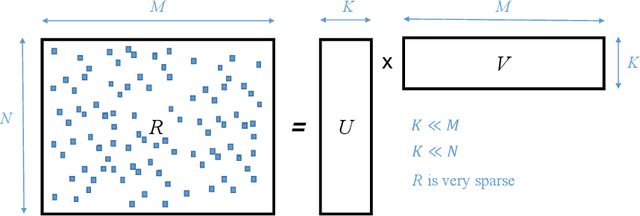
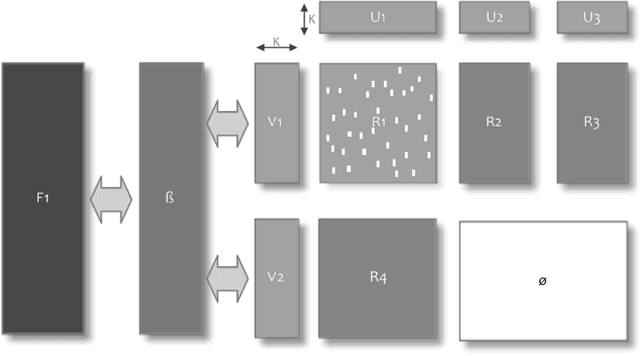
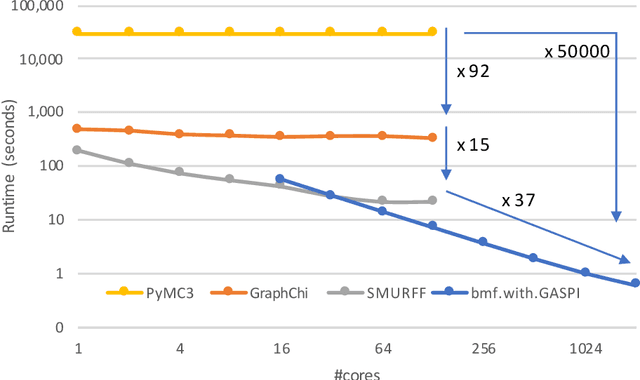
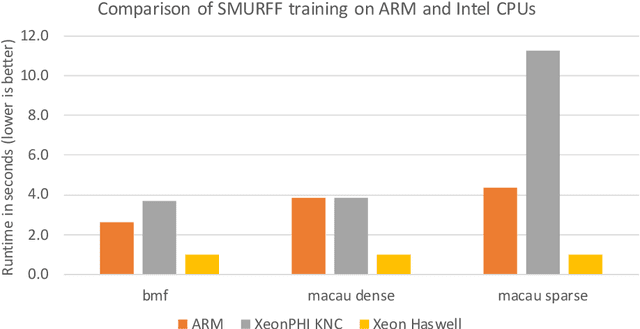
Bayesian Matrix Factorization (BMF) is a powerful technique for recommender systems because it produces good results and is relatively robust against overfitting. Yet BMF is more computationally intensive and thus more challenging to implement for large datasets. In this work we present SMURFF a high-performance feature-rich framework to compose and construct different Bayesian matrix-factorization methods. The framework has been successfully used in to do large scale runs of compound-activity prediction. SMURFF is available as open-source and can be used both on a supercomputer and on a desktop or laptop machine. Documentation and several examples are provided as Jupyter notebooks using SMURFF's high-level Python API.