 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRainy screens: Collecting rainy datasets, indoors
Mar 10, 2020


Acquisition of data with adverse conditions in robotics is a cumbersome task due to the difficulty in guaranteeing proper ground truth and synchronising with desired weather conditions. In this paper, we present a simple method - recording a high resolution screen - for generating diverse rainy images from existing clear ground-truth images that is domain- and source-agnostic, simple and scales up. This setup allows us to leverage the diversity of existing datasets with auxiliary task ground-truth data, such as semantic segmentation, object positions etc. We generate rainy images with real adherent droplets and rain streaks based on Cityscapes and BDD, and train a de-raining model. We present quantitative results for image reconstruction and semantic segmentation, and qualitative results for an out-of-sample domain, showing that models trained with our data generalize well.
Don't Worry About the Weather: Unsupervised Condition-Dependent Domain Adaptation
Jul 25, 2019
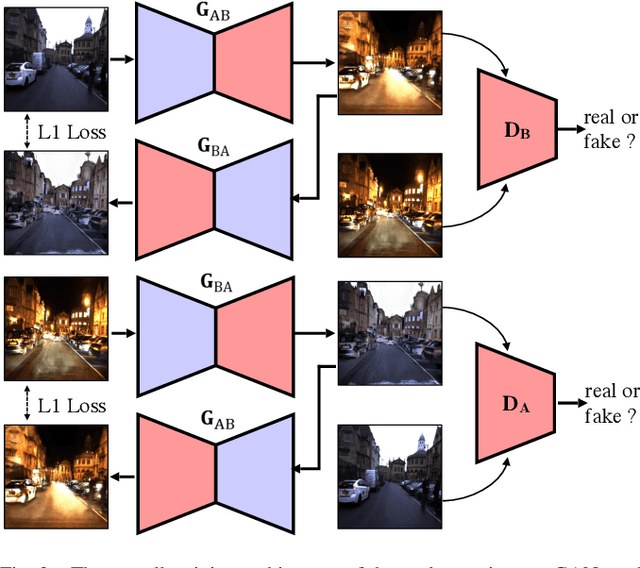

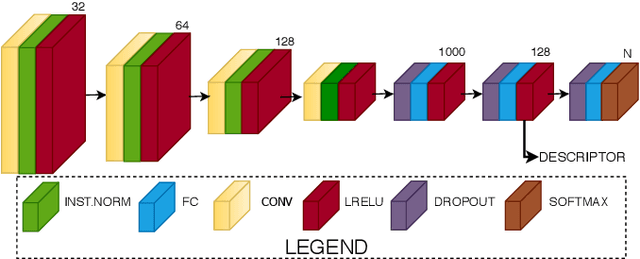
Modern models that perform system-critical tasks such as segmentation and localization exhibit good performance and robustness under ideal conditions (i.e. daytime, overcast) but performance degrades quickly and often catastrophically when input conditions change. In this work, we present a domain adaptation system that uses light-weight input adapters to pre-processes input images, irrespective of their appearance, in a way that makes them compatible with off-the-shelf computer vision tasks that are trained only on inputs with ideal conditions. No fine-tuning is performed on the off-the-shelf models, and the system is capable of incrementally training new input adapters in a self-supervised fashion, using the computer vision tasks as supervisors, when the input domain differs significantly from previously seen domains. We report large improvements in semantic segmentation and topological localization performance on two popular datasets, RobotCar and BDD.
Generating All the Roads to Rome: Road Layout Randomization for Improved Road Marking Segmentation
Jul 10, 2019
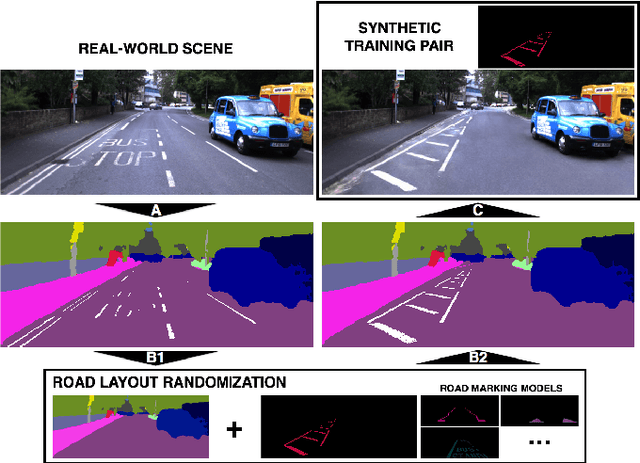
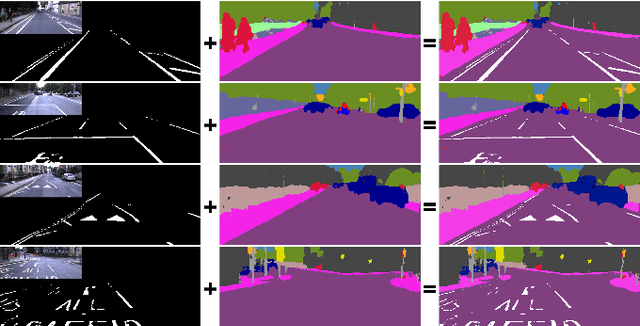

Road markings provide guidance to traffic participants and enforce safe driving behaviour, understanding their semantic meaning is therefore paramount in (automated) driving. However, producing the vast quantities of road marking labels required for training state-of-the-art deep networks is costly, time-consuming, and simply infeasible for every domain and condition. In addition, training data retrieved from virtual worlds often lack the richness and complexity of the real world and consequently cannot be used directly. In this paper, we provide an alternative approach in which new road marking training pairs are automatically generated. To this end, we apply principles of domain randomization to the road layout and synthesize new images from altered semantic labels. We demonstrate that training on these synthetic pairs improves mIoU of the segmentation of rare road marking classes during real-world deployment in complex urban environments by more than 12 percentage points, while performance for other classes is retained. This framework can easily be scaled to all domains and conditions to generate large-scale road marking datasets, while avoiding manual labelling effort.
I Can See Clearly Now : Image Restoration via De-Raining
Jan 03, 2019
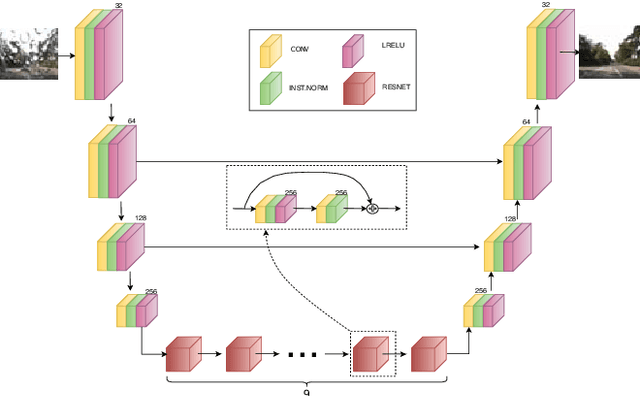


We present a method for improving segmentation tasks on images affected by adherent rain drops and streaks. We introduce a novel stereo dataset recorded using a system that allows one lens to be affected by real water droplets while keeping the other lens clear. We train a denoising generator using this dataset and show that it is effective at removing the effect of real water droplets, in the context of image reconstruction and road marking segmentation. To further test our de-noising approach, we describe a method of adding computer-generated adherent water droplets and streaks to any images, and use this technique as a proxy to demonstrate the effectiveness of our model in the context of general semantic segmentation. We benchmark our results using the CamVid road marking segmentation dataset, Cityscapes semantic segmentation datasets and our own real-rain dataset, and show significant improvement on all tasks.
The Right (Angled) Perspective: Improving the Understanding of Road Scenes using Boosted Inverse Perspective Mapping
Dec 03, 2018
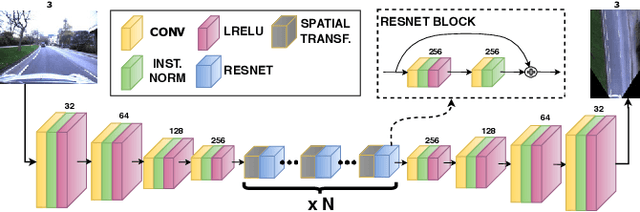


Many tasks performed by autonomous vehicles such as road marking detection, object tracking, and path planning are simpler in bird's-eye view. Hence, Inverse Perspective Mapping (IPM) is often applied to remove the perspective effect from a vehicle's front-facing camera and to remap its images into a 2D domain, resulting in a top-down view. Unfortunately, however, this leads to unnatural blurring and stretching of objects at further distance, due to the resolution of the camera, limiting applicability. In this paper, we present an adversarial learning approach for generating a significantly improved IPM from a single camera image in real time. The generated bird's-eye-view images contain sharper features (e.g. road markings) and a more homogeneous illumination, while (dynamic) objects are automatically removed from the scene, thus revealing the underlying road layout in an improved fashion. We demonstrate our framework using real-world data from the Oxford RobotCar Dataset and show that scene understanding tasks directly benefit from our boosted IPM approach.