 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoising Diffusion via Image-Based Rendering
Feb 05, 2024



Generating 3D scenes is a challenging open problem, which requires synthesizing plausible content that is fully consistent in 3D space. While recent methods such as neural radiance fields excel at view synthesis and 3D reconstruction, they cannot synthesize plausible details in unobserved regions since they lack a generative capability. Conversely, existing generative methods are typically not capable of reconstructing detailed, large-scale scenes in the wild, as they use limited-capacity 3D scene representations, require aligned camera poses, or rely on additional regularizers. In this work, we introduce the first diffusion model able to perform fast, detailed reconstruction and generation of real-world 3D scenes. To achieve this, we make three contributions. First, we introduce a new neural scene representation, IB-planes, that can efficiently and accurately represent large 3D scenes, dynamically allocating more capacity as needed to capture details visible in each image. Second, we propose a denoising-diffusion framework to learn a prior over this novel 3D scene representation, using only 2D images without the need for any additional supervision signal such as masks or depths. This supports 3D reconstruction and generation in a unified architecture. Third, we develop a principled approach to avoid trivial 3D solutions when integrating the image-based rendering with the diffusion model, by dropping out representations of some images. We evaluate the model on several challenging datasets of real and synthetic images, and demonstrate superior results on generation, novel view synthesis and 3D reconstruction.
Object-Centric Image Generation with Factored Depths, Locations, and Appearances
Apr 01, 2020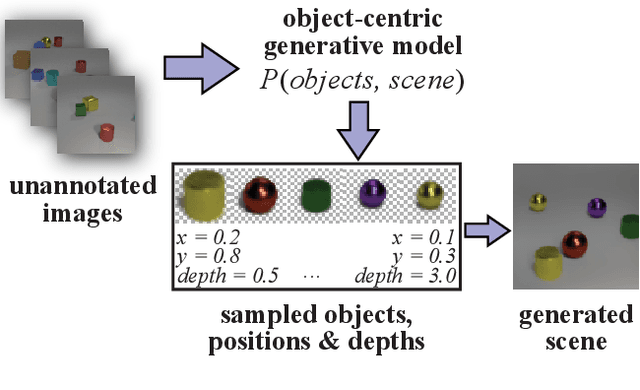
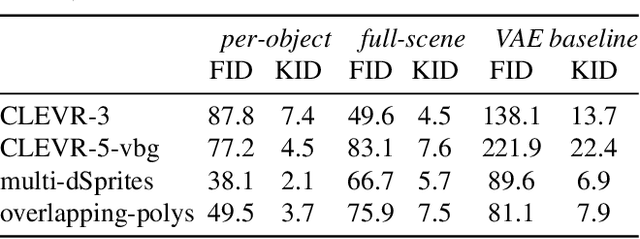
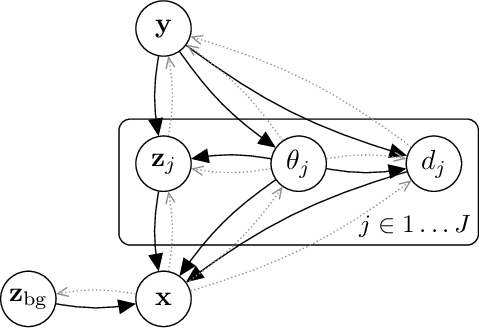
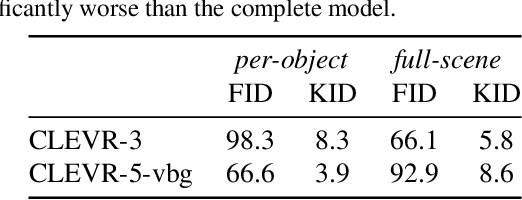
We present a generative model of images that explicitly reasons over the set of objects they show. Our model learns a structured latent representation that separates objects from each other and from the background; unlike prior works, it explicitly represents the 2D position and depth of each object, as well as an embedding of its segmentation mask and appearance. The model can be trained from images alone in a purely unsupervised fashion without the need for object masks or depth information. Moreover, it always generates complete objects, even though a significant fraction of training images contain occlusions. Finally, we show that our model can infer decompositions of novel images into their constituent objects, including accurate prediction of depth ordering and segmentation of occluded parts.