Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom News to Medical: Cross-domain Discourse Segmentation
Apr 14, 2019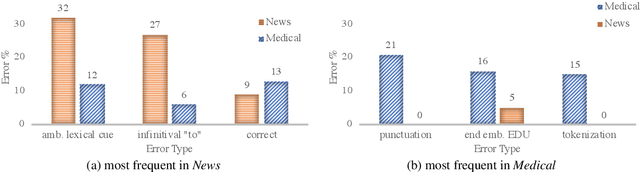

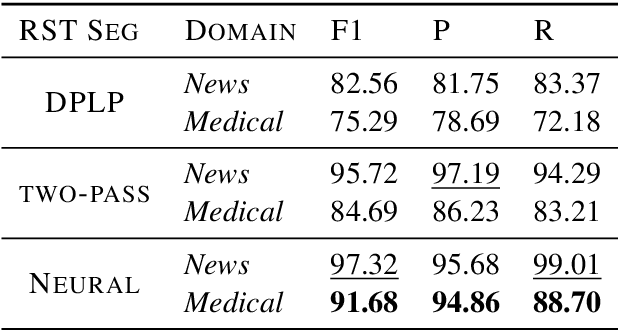
The first step in discourse analysis involves dividing a text into segments. We annotate the first high-quality small-scale medical corpus in English with discourse segments and analyze how well news-trained segmenters perform on this domain. While we expectedly find a drop in performance, the nature of the segmentation errors suggests some problems can be addressed earlier in the pipeline, while others would require expanding the corpus to a trainable size to learn the nuances of the medical domain.
* NAACL DISRPT Workshop 2019
Via