 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChoice of training label matters: how to best use deep learning for quantitative MRI parameter estimation
May 11, 2022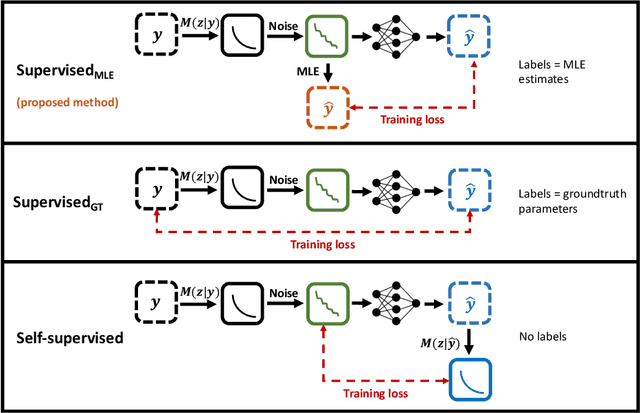
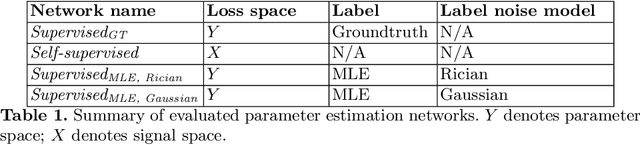

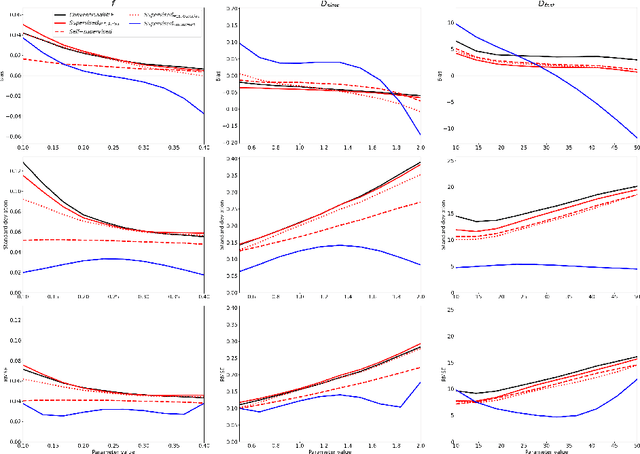
Deep learning (DL) is gaining popularity as a parameter estimation method for quantitative MRI. A range of competing implementations have been proposed, relying on either supervised or self-supervised learning. Self-supervised approaches, sometimes referred to as unsupervised, have been loosely based on auto-encoders, whereas supervised methods have, to date, been trained on groundtruth labels. These two learning paradigms have been shown to have distinct strengths. Notably, self-supervised approaches have offered lower-bias parameter estimates than their supervised alternatives. This result is counterintuitive - incorporating prior knowledge with supervised labels should, in theory, lead to improved accuracy. In this work, we show that this apparent limitation of supervised approaches stems from the naive choice of groundtruth training labels. By training on labels which are deliberately not groundtruth, we show that the low-bias parameter estimation previously associated with self-supervised methods can be replicated - and improved on - within a supervised learning framework. This approach sets the stage for a single, unifying, deep learning parameter estimation framework, based on supervised learning, where trade-offs between bias and variance are made by careful adjustment of training label.
Task-driven assessment of experimental designs in diffusion MRI: a computational framework
Mar 15, 2021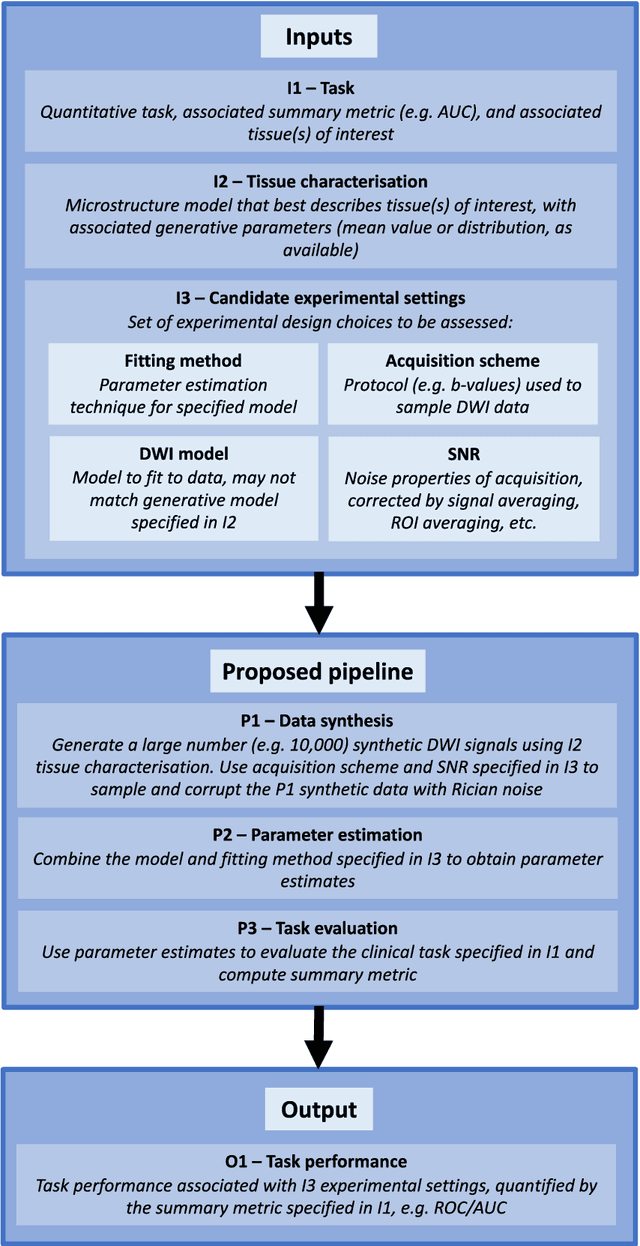
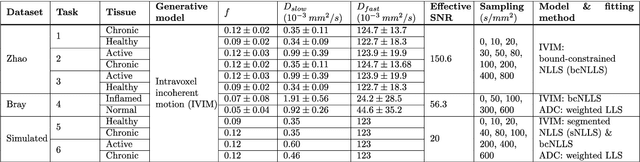
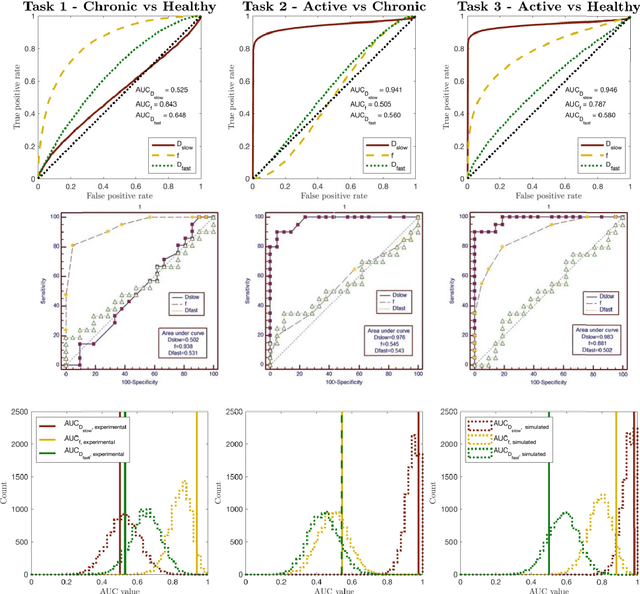
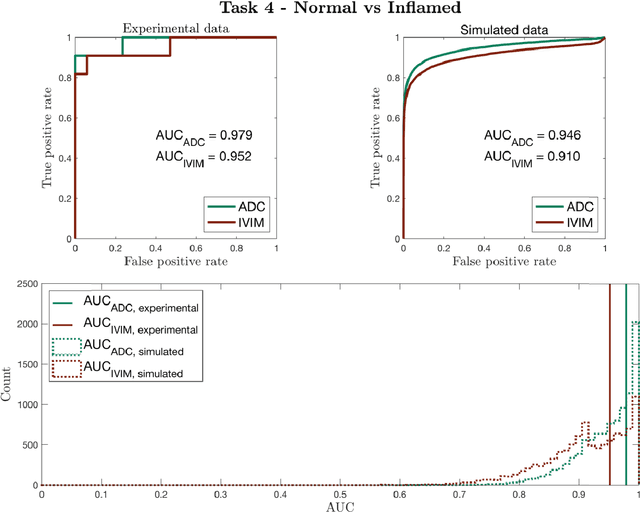
Purpose: To propose a task-driven computational framework for assessing diffusion MRI experimental designs which, rather than relying on parameter-estimation metrics, directly measures quantitative task performance. Theory: Traditional computational experimental design (CED) methods may be ill-suited to tasks, such as clinical classification, where outcome does not depend on parameter-estimation accuracy or precision alone. Current assessment metrics evaluate experiments' ability to faithfully recover microstructure parameters rather than their associated task performance. This work proposes a novel CED assessment method that addresses this shortcoming. For a given experimental design (protocol, parameter-estimation method, model, etc.), experiments are simulated start-to-finish and task performance is computed from receiver operating characteristic (ROC) curves and summary metrics such as area under the curve (AUC). Methods: Two experiments were performed: first a validation of the pipeline's task performance predictions in two clinical datasets, comparing in-silico predictions to real-world ROC/AUC; and second, a demonstration of the pipeline's advantages over traditional CED approaches, using two simulated clinical classification tasks. Results: Our computational method accurately predicts (a) the qualitative form of ROC curves, (b) the relative performance of different experimental designs, and (c) the absolute performance (AUC) of each experimental design. Furthermore, our method is shown to outperform traditional task-agnostic assessment methods. Conclusions: The proposed pipeline produces accurate, quantitative predictions of real-world task performance. Compared to current approaches, such task-driven assessment is more likely to identify experimental design that perform well in practice. It provides the foundation for developing future task-driven CED frameworks.