 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChoice of training label matters: how to best use deep learning for quantitative MRI parameter estimation
May 11, 2022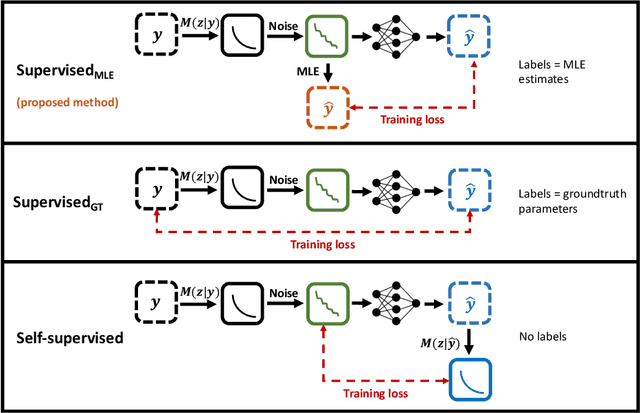
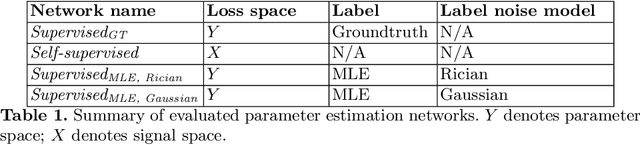

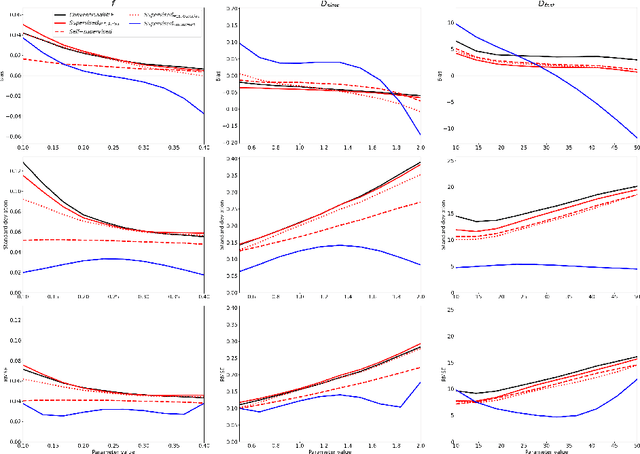
Deep learning (DL) is gaining popularity as a parameter estimation method for quantitative MRI. A range of competing implementations have been proposed, relying on either supervised or self-supervised learning. Self-supervised approaches, sometimes referred to as unsupervised, have been loosely based on auto-encoders, whereas supervised methods have, to date, been trained on groundtruth labels. These two learning paradigms have been shown to have distinct strengths. Notably, self-supervised approaches have offered lower-bias parameter estimates than their supervised alternatives. This result is counterintuitive - incorporating prior knowledge with supervised labels should, in theory, lead to improved accuracy. In this work, we show that this apparent limitation of supervised approaches stems from the naive choice of groundtruth training labels. By training on labels which are deliberately not groundtruth, we show that the low-bias parameter estimation previously associated with self-supervised methods can be replicated - and improved on - within a supervised learning framework. This approach sets the stage for a single, unifying, deep learning parameter estimation framework, based on supervised learning, where trade-offs between bias and variance are made by careful adjustment of training label.