 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference for Regression with Variables Generated from Unstructured Data
Feb 23, 2024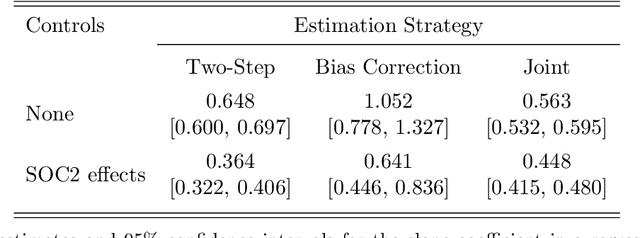
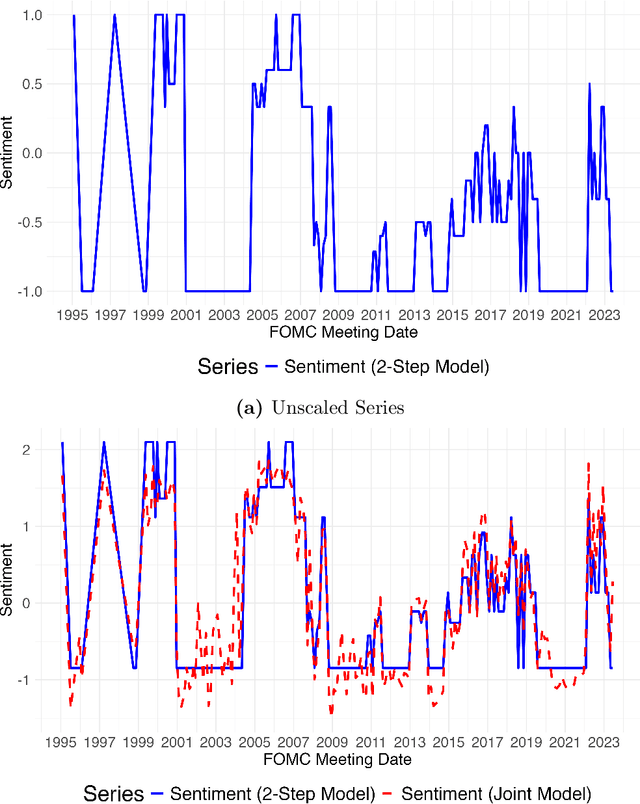
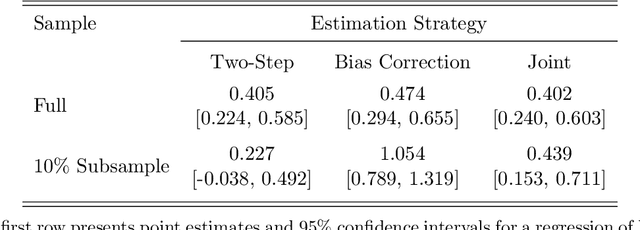
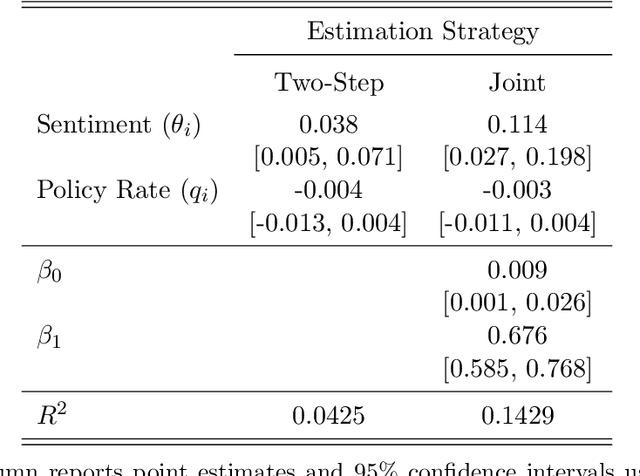
The leading strategy for analyzing unstructured data uses two steps. First, latent variables of economic interest are estimated with an upstream information retrieval model. Second, the estimates are treated as "data" in a downstream econometric model. We establish theoretical arguments for why this two-step strategy leads to biased inference in empirically plausible settings. More constructively, we propose a one-step strategy for valid inference that uses the upstream and downstream models jointly. The one-step strategy (i) substantially reduces bias in simulations; (ii) has quantitatively important effects in a leading application using CEO time-use data; and (iii) can be readily adapted by applied researchers.
Externally Valid Treatment Choice
May 11, 2022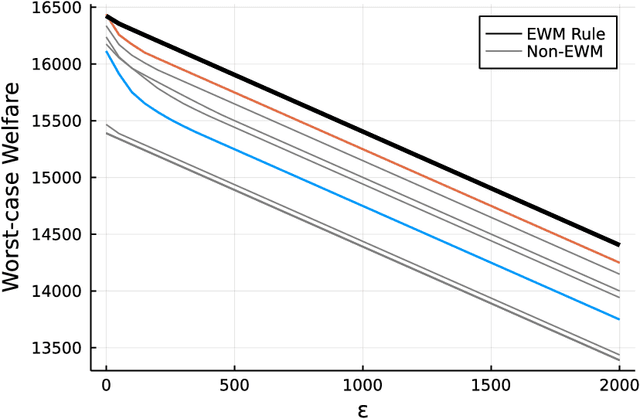
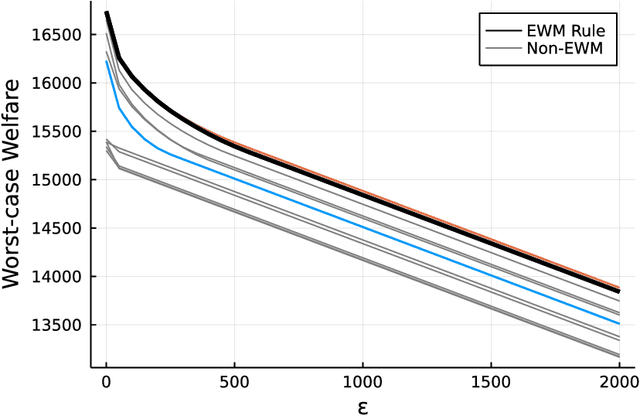
We consider the problem of learning treatment (or policy) rules that are externally valid in the sense that they have welfare guarantees in target populations that are similar to, but possibly different from, the experimental population. We allow for shifts in both the distribution of potential outcomes and covariates between the experimental and target populations. This paper makes two main contributions. First, we provide a formal sense in which policies that maximize social welfare in the experimental population remain optimal for the "worst-case" social welfare when the distribution of potential outcomes (but not covariates) shifts. Hence, policy learning methods that have good regret guarantees in the experimental population, such as empirical welfare maximization, are externally valid with respect to a class of shifts in potential outcomes. Second, we develop methods for policy learning that are robust to shifts in the joint distribution of potential outcomes and covariates. Our methods may be used with experimental or observational data.
Adaptive Estimation and Uniform Confidence Bands for Nonparametric IV
Jul 25, 2021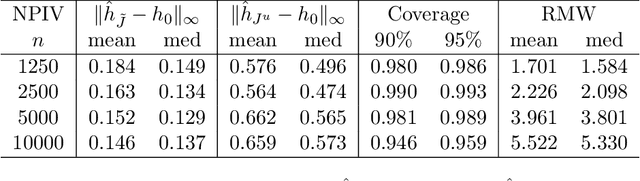

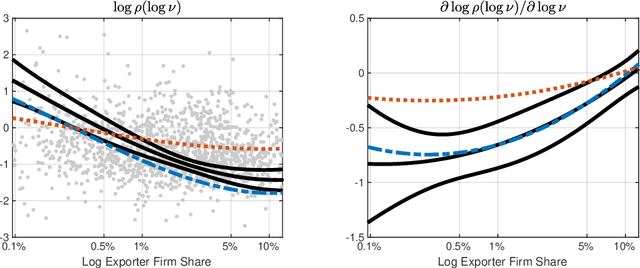

We introduce computationally simple, data-driven procedures for estimation and inference on a structural function $h_0$ and its derivatives in nonparametric models using instrumental variables. Our first procedure is a bootstrap-based, data-driven choice of sieve dimension for sieve nonparametric instrumental variables (NPIV) estimators. When implemented with this data-driven choice, sieve NPIV estimators of $h_0$ and its derivatives are adaptive: they converge at the best possible (i.e., minimax) sup-norm rate, without having to know the smoothness of $h_0$, degree of endogeneity of the regressors, or instrument strength. Our second procedure is a data-driven approach for constructing honest and adaptive uniform confidence bands (UCBs) for $h_0$ and its derivatives. Our data-driven UCBs guarantee coverage for $h_0$ and its derivatives uniformly over a generic class of data-generating processes (honesty) and contract at, or within a logarithmic factor of, the minimax sup-norm rate (adaptivity). As such, our data-driven UCBs deliver asymptotic efficiency gains relative to UCBs constructed via the usual approach of undersmoothing. In addition, both our procedures apply to nonparametric regression as a special case. We use our procedures to estimate and perform inference on a nonparametric gravity equation for the intensive margin of firm exports and find evidence against common parameterizations of the distribution of unobserved firm productivity.