 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Learning-augmented Algorithms for k-means and k-medians Clustering
Oct 31, 2022



We consider the problem of clustering in the learning-augmented setting, where we are given a data set in $d$-dimensional Euclidean space, and a label for each data point given by an oracle indicating what subsets of points should be clustered together. This setting captures situations where we have access to some auxiliary information about the data set relevant for our clustering objective, for instance the labels output by a neural network. Following prior work, we assume that there are at most an $\alpha \in (0,c)$ for some $c<1$ fraction of false positives and false negatives in each predicted cluster, in the absence of which the labels would attain the optimal clustering cost $\mathrm{OPT}$. For a dataset of size $m$, we propose a deterministic $k$-means algorithm that produces centers with improved bound on clustering cost compared to the previous randomized algorithm while preserving the $O( d m \log m)$ runtime. Furthermore, our algorithm works even when the predictions are not very accurate, i.e. our bound holds for $\alpha$ up to $1/2$, an improvement over $\alpha$ being at most $1/7$ in the previous work. For the $k$-medians problem we improve upon prior work by achieving a biquadratic improvement in the dependence of the approximation factor on the accuracy parameter $\alpha$ to get a cost of $(1+O(\alpha))\mathrm{OPT}$, while requiring essentially just $O(md \log^3 m/\alpha)$ runtime.
Streaming Submodular Maximization with Differential Privacy
Oct 25, 2022In this work, we study the problem of privately maximizing a submodular function in the streaming setting. Extensive work has been done on privately maximizing submodular functions in the general case when the function depends upon the private data of individuals. However, when the size of the data stream drawn from the domain of the objective function is large or arrives very fast, one must privately optimize the objective within the constraints of the streaming setting. We establish fundamental differentially private baselines for this problem and then derive better trade-offs between privacy and utility for the special case of decomposable submodular functions. A submodular function is decomposable when it can be written as a sum of submodular functions; this structure arises naturally when each summand function models the utility of an individual and the goal is to study the total utility of the whole population as in the well-known Combinatorial Public Projects Problem. Finally, we complement our theoretical analysis with experimental corroboration.
An Efficient Algorithm for Fair Multi-Agent Multi-Armed Bandit with Low Regret
Sep 23, 2022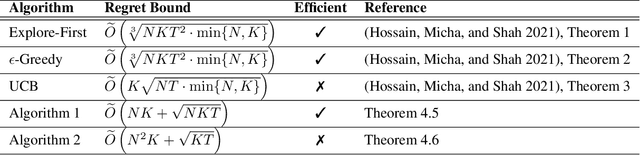
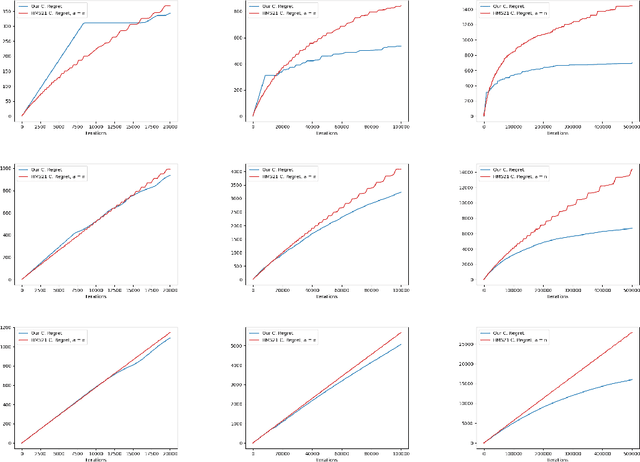

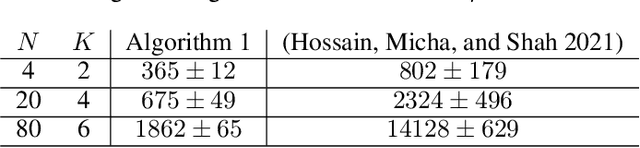
Recently a multi-agent variant of the classical multi-armed bandit was proposed to tackle fairness issues in online learning. Inspired by a long line of work in social choice and economics, the goal is to optimize the Nash social welfare instead of the total utility. Unfortunately previous algorithms either are not efficient or achieve sub-optimal regret in terms of the number of rounds $T$. We propose a new efficient algorithm with lower regret than even previous inefficient ones. For $N$ agents, $K$ arms, and $T$ rounds, our approach has a regret bound of $\tilde{O}(\sqrt{NKT} + NK)$. This is an improvement to the previous approach, which has regret bound of $\tilde{O}( \min(NK, \sqrt{N} K^{3/2})\sqrt{T})$. We also complement our efficient algorithm with an inefficient approach with $\tilde{O}(\sqrt{KT} + N^2K)$ regret. The experimental findings confirm the effectiveness of our efficient algorithm compared to the previous approaches.
Differentially Private Clustering via Maximum Coverage
Aug 27, 2020
This paper studies the problem of clustering in metric spaces while preserving the privacy of individual data. Specifically, we examine differentially private variants of the k-medians and Euclidean k-means problems. We present polynomial algorithms with constant multiplicative error and lower additive error than the previous state-of-the-art for each problem. Additionally, our algorithms use a clustering algorithm without differential privacy as a black-box. This allows practitioners to control the trade-off between runtime and approximation factor by choosing a suitable clustering algorithm to use.