 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWear Classification of Abrasive Flap Wheels using a Hierarchical Deep Learning Approach
Mar 13, 2026Abrasive flap wheels are common for finishing complex free-form surfaces due to their flexibility. However, this flexibility results in complex wear patterns such as concave/convex flap profiles or flap tears, which influence the grinding result. This paper proposes a novel, vision-based hierarchical classification framework to automate the wear condition monitoring of flap wheels. Unlike monolithic classification approaches, we decompose the problem into three logical levels: (1) state detection (new vs. worn), (2) wear type identification (rectangular, concave, convex) and flap tear detection, and (3) severity assessment (partial vs. complete deformation). A custom-built dataset of real flap wheel images was generated and a transfer learning approach with EfficientNetV2 architecture was used. The results demonstrate high robustness with classification accuracies ranging from 93.8% (flap tears) to 99.3% (concave severity). Furthermore, Gradient-weighted Class Activation Mapping (Grad-CAM) is utilized to validate that the models learn physically relevant features and examine false classifications. The proposed hierarchical method provides a basis for adaptive process control and wear consideration in automated flap wheel grinding.
Open-vocabulary 3D scene perception in industrial environments
Feb 23, 2026Autonomous vision applications in production, intralogistics, or manufacturing environments require perception capabilities beyond a small, fixed set of classes. Recent open-vocabulary methods, leveraging 2D Vision-Language Foundation Models (VLFMs), target this task but often rely on class-agnostic segmentation models pre-trained on non-industrial datasets (e.g., household scenes). In this work, we first demonstrate that such models fail to generalize, performing poorly on common industrial objects. Therefore, we propose a training-free, open-vocabulary 3D perception pipeline that overcomes this limitation. Instead of using a pre-trained model to generate instance proposals, our method simply generates masks by merging pre-computed superpoints based on their semantic features. Following, we evaluate the domain-adapted VLFM "IndustrialCLIP" on a representative 3D industrial workshop scene for open-vocabulary querying. Our qualitative results demonstrate successful segmentation of industrial objects.
CUROCKET: Optimizing ROCKET for GPU
Jan 23, 2026ROCKET (RandOm Convolutional KErnel Transform) is a feature extraction algorithm created for Time Series Classification (TSC), published in 2019. It applies convolution with randomly generated kernels on a time series, producing features that can be used to train a linear classifier or regressor like Ridge. At the time of publication, ROCKET was on par with the best state-of-the-art algorithms for TSC in terms of accuracy while being significantly less computationally expensive, making ROCKET a compelling algorithm for TSC. This also led to several subsequent versions, further improving accuracy and computational efficiency. The currently available ROCKET implementations are mostly bound to execution on CPU. However, convolution is a task that can be highly parallelized and is therefore suited to be executed on GPU, which speeds up the computation significantly. A key difficulty arises from the inhomogeneous kernels ROCKET uses, making standard methods for applying convolution on GPU inefficient. In this work, we propose an algorithm that is able to efficiently perform ROCKET on GPU and achieves up to 11 times higher computational efficiency per watt than ROCKET on CPU. The code for CUROCKET is available in this repository https://github.com/oleeven/CUROCKET on github.
Industrial Language-Image Dataset (ILID): Adapting Vision Foundation Models for Industrial Settings
Jun 14, 2024

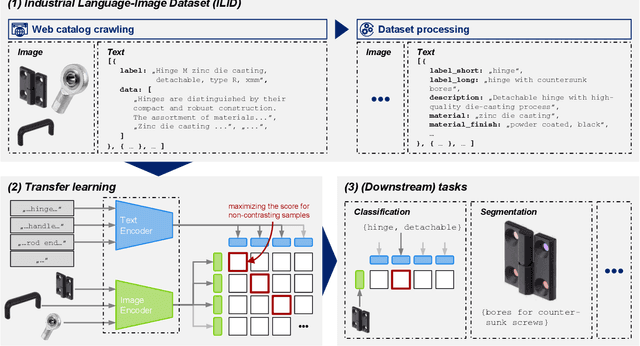

In recent years, the upstream of Large Language Models (LLM) has also encouraged the computer vision community to work on substantial multimodal datasets and train models on a scale in a self-/semi-supervised manner, resulting in Vision Foundation Models (VFM), as, e.g., Contrastive Language-Image Pre-training (CLIP). The models generalize well and perform outstandingly on everyday objects or scenes, even on downstream tasks, tasks the model has not been trained on, while the application in specialized domains, as in an industrial context, is still an open research question. Here, fine-tuning the models or transfer learning on domain-specific data is unavoidable when objecting to adequate performance. In this work, we, on the one hand, introduce a pipeline to generate the Industrial Language-Image Dataset (ILID) based on web-crawled data; on the other hand, we demonstrate effective self-supervised transfer learning and discussing downstream tasks after training on the cheaply acquired ILID, which does not necessitate human labeling or intervention. With the proposed approach, we contribute by transferring approaches from state-of-the-art research around foundation models, transfer learning strategies, and applications to the industrial domain.
Industrial Segment Anything -- a Case Study in Aircraft Manufacturing, Intralogistics, Maintenance, Repair, and Overhaul
Jul 24, 2023Deploying deep learning-based applications in specialized domains like the aircraft production industry typically suffers from the training data availability problem. Only a few datasets represent non-everyday objects, situations, and tasks. Recent advantages in research around Vision Foundation Models (VFM) opened a new area of tasks and models with high generalization capabilities in non-semantic and semantic predictions. As recently demonstrated by the Segment Anything Project, exploiting VFM's zero-shot capabilities is a promising direction in tackling the boundaries spanned by data, context, and sensor variety. Although, investigating its application within specific domains is subject to ongoing research. This paper contributes here by surveying applications of the SAM in aircraft production-specific use cases. We include manufacturing, intralogistics, as well as maintenance, repair, and overhaul processes, also representing a variety of other neighboring industrial domains. Besides presenting the various use cases, we further discuss the injection of domain knowledge.
Semantically enriched spatial modelling of industrial indoor environments enabling location-based services
Dec 22, 2021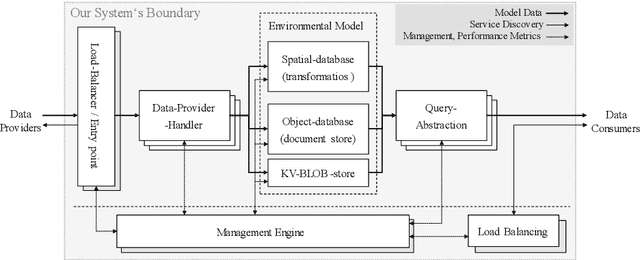
This paper presents a concept for a software system called RAIL representing industrial indoor environments in a dynamic spatial model, aimed at easing development and provision of location-based services. RAIL integrates data from different sensor modalities and additional contextual information through a unified interface. Approaches to environmental modelling from other domains are reviewed and analyzed for their suitability regarding the requirements for our target domains; intralogistics and production. Subsequently a novel way of modelling data representing indoor space, and an architecture for the software system are proposed.
* 3. Kongresses Montage Handhabung Industrieroboter MHI