 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven emotional body language generation for social robotics
May 02, 2022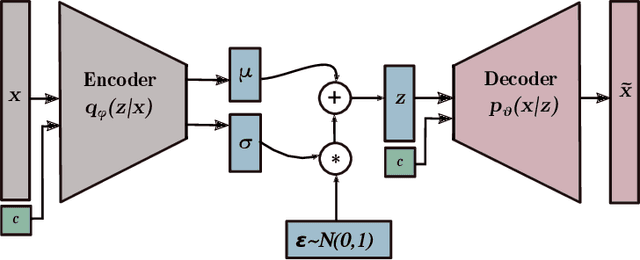
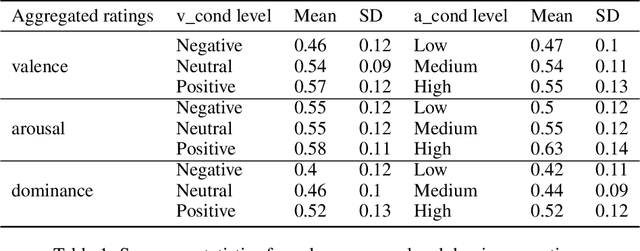
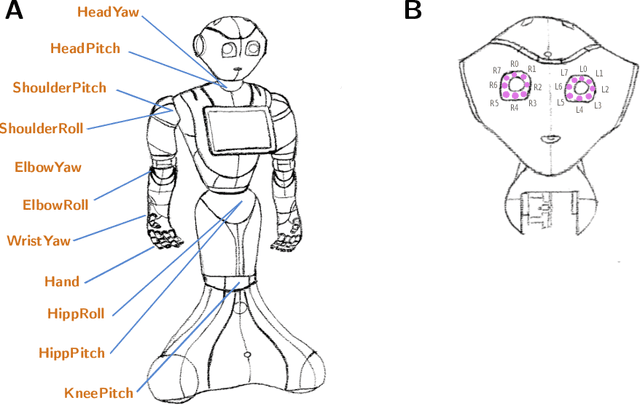
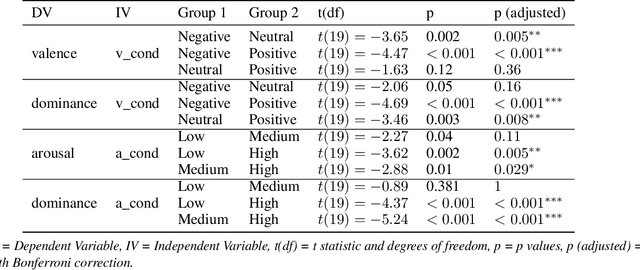
In social robotics, endowing humanoid robots with the ability to generate bodily expressions of affect can improve human-robot interaction and collaboration, since humans attribute, and perhaps subconsciously anticipate, such traces to perceive an agent as engaging, trustworthy, and socially present. Robotic emotional body language needs to be believable, nuanced and relevant to the context. We implemented a deep learning data-driven framework that learns from a few hand-designed robotic bodily expressions and can generate numerous new ones of similar believability and lifelikeness. The framework uses the Conditional Variational Autoencoder model and a sampling approach based on the geometric properties of the model's latent space to condition the generative process on targeted levels of valence and arousal. The evaluation study found that the anthropomorphism and animacy of the generated expressions are not perceived differently from the hand-designed ones, and the emotional conditioning was adequately differentiable between most levels except the pairs of neutral-positive valence and low-medium arousal. Furthermore, an exploratory analysis of the results reveals a possible impact of the conditioning on the perceived dominance of the robot, as well as on the participants' attention.
A natural approach to studying schema processing
May 12, 2017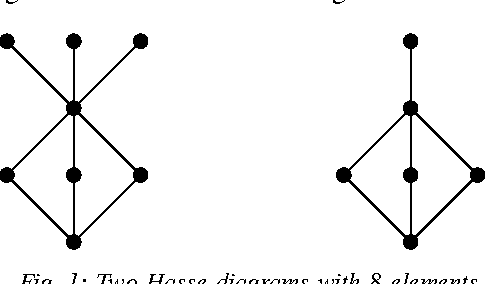
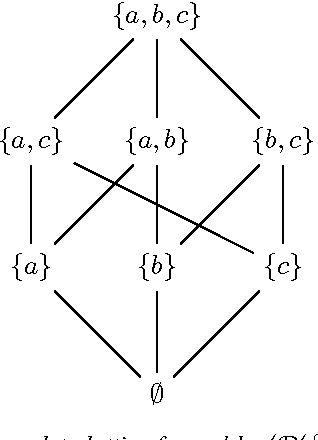
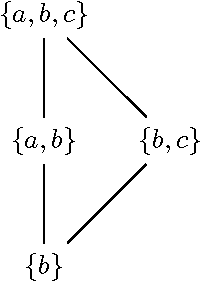
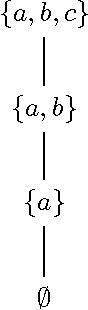
The Building Block Hypothesis (BBH) states that adaptive systems combine good partial solutions (so-called building blocks) to find increasingly better solutions. It is thought that Genetic Algorithms (GAs) implement the BBH. However, for GAs building blocks are semi-theoretical objects in that they are thought only to be implicitly exploited via the selection and crossover operations of a GA. In the current work, we discover a mathematical method to identify the complete set of schemata present in a given population of a GA; as such a natural way to study schema processing (and thus the BBH) is revealed. We demonstrate how this approach can be used both theoretically and experimentally. Theoretically, we show that the search space for good schemata is a complete lattice and that each generation samples a complete sub-lattice of this search space. In addition, we show that combining schemata can only explore a subset of the search space. Experimentally, we compare how well different crossover methods combine building blocks. We find that for most crossover methods approximately 25-35% of building blocks in a generation result from the combination of the previous generation's building blocks. We also find that an increase in the combination of building blocks does not lead to an increase in the efficiency of a GA. To complement this article, we introduce an open source Python package called schematax, which allows one to calculate the schemata present in a population using the methods described in this article.