 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudiovisual Database with 360 Video and Higher-Order Ambisonics Audio for Perception, Cognition, Behavior, and QoE Evaluation Research
Dec 27, 2022Research into multi-modal perception, human cognition, behavior, and attention can benefit from high-fidelity content that may recreate real-life-like scenes when rendered on head-mounted displays. Moreover, aspects of audiovisual perception, cognitive processes, and behavior may complement questionnaire-based Quality of Experience (QoE) evaluation of interactive virtual environments. Currently, there is a lack of high-quality open-source audiovisual databases that can be used to evaluate such aspects or systems capable of reproducing high-quality content. With this paper, we provide a publicly available audiovisual database consisting of twelve scenes capturing real-life nature and urban environments with a video resolution of 7680x3840 at 60 frames-per-second and with 4th-order Ambisonics audio. These 360 video sequences, with an average duration of 60 seconds, represent real-life settings for systematically evaluating various dimensions of uni-/multi-modal perception, cognition, behavior, and QoE. The paper provides details of the scene requirements, recording approach, and scene descriptions. The database provides high-quality reference material with a balanced focus on auditory and visual sensory information. The database will be continuously updated with additional scenes and further metadata such as human ratings and saliency information.
Dialogue Enhancement and Listening Effort in Broadcast Audio: A Multimodal Evaluation
Aug 03, 2022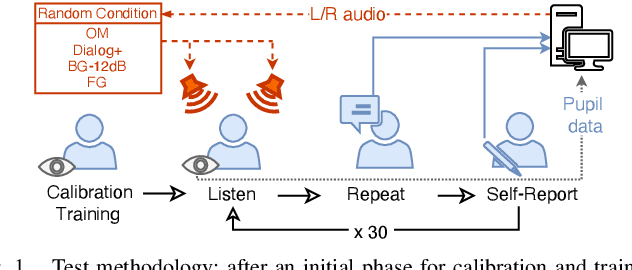
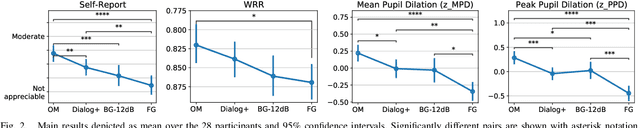
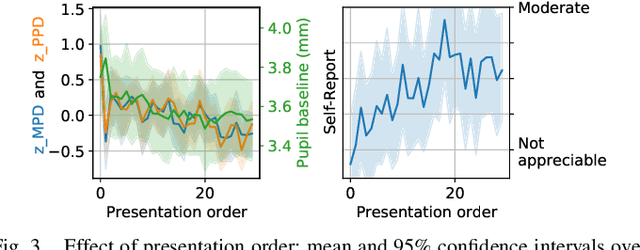
Dialogue enhancement (DE) plays a vital role in broadcasting, enabling the personalization of the relative level between foreground speech and background music and effects. DE has been shown to improve the quality of experience, intelligibility, and self-reported listening effort (LE). A physiological indicator of LE known from audiology studies is pupil size. The relation between pupil size and LE is typically studied using artificial sentences and background noises not encountered in broadcast content. This work evaluates the effect of DE on LE in a multimodal manner that includes pupil size (tracked by a VR headset) and real-world audio excerpts from TV. Under ideal listening conditions, 28 normal-hearing participants listened to 30 audio excerpts presented in random order and processed by conditions varying the relative level between foreground and background audio. One of these conditions employed a recently proposed source separation system to attenuate the background given the original mixture as the sole input. After listening to each excerpt, subjects were asked to repeat the heard sentence and self-report the LE. Mean pupil dilation and peak pupil dilation were analyzed and compared with the self-report and the word recall rate. The multimodal evaluation shows a consistent trend of decreasing LE along with decreasing background level. DE, also when enabled by source separation, significantly reduces the pupil size as well as the self-reported LE. This highlights the benefit of personalization functionalities at the user's end.