 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmiles2Dock: an open large-scale multi-task dataset for ML-based molecular docking
Jun 09, 2024
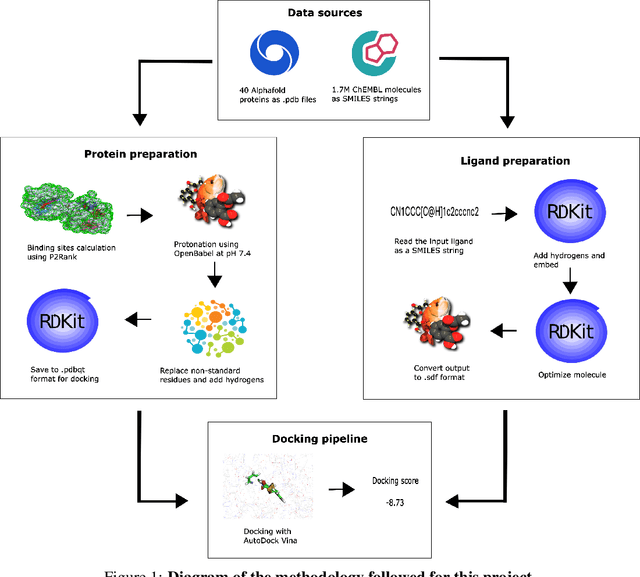
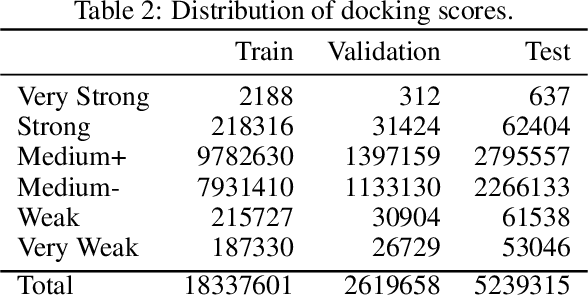
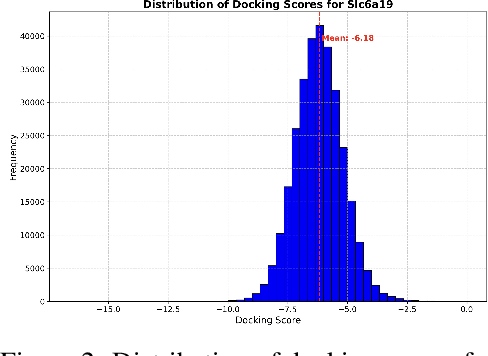
Docking is a crucial component in drug discovery aimed at predicting the binding conformation and affinity between small molecules and target proteins. ML-based docking has recently emerged as a prominent approach, outpacing traditional methods like DOCK and AutoDock Vina in handling the growing scale and complexity of molecular libraries. However, the availability of comprehensive and user-friendly datasets for training and benchmarking ML-based docking algorithms remains limited. We introduce Smiles2Dock, an open large-scale multi-task dataset for molecular docking. We created a framework combining P2Rank and AutoDock Vina to dock 1.7 million ligands from the ChEMBL database against 15 AlphaFold proteins, giving us more than 25 million protein-ligand binding scores. The dataset leverages a wide range of high-accuracy AlphaFold protein models, encompasses a diverse set of biologically relevant compounds and enables researchers to benchmark all major approaches for ML-based docking such as Graph, Transformer and CNN-based methods. We also introduce a novel Transformer-based architecture for docking scores prediction and set it as an initial benchmark for our dataset. Our dataset and code are publicly available to support the development of novel ML-based methods for molecular docking to advance scientific research in this field.
Using Pre-training and Interaction Modeling for ancestry-specific disease prediction in UK Biobank
Apr 26, 2024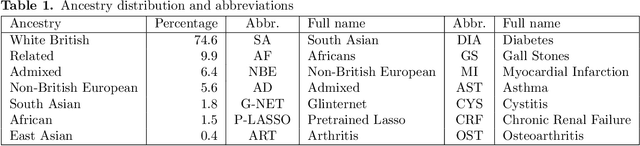
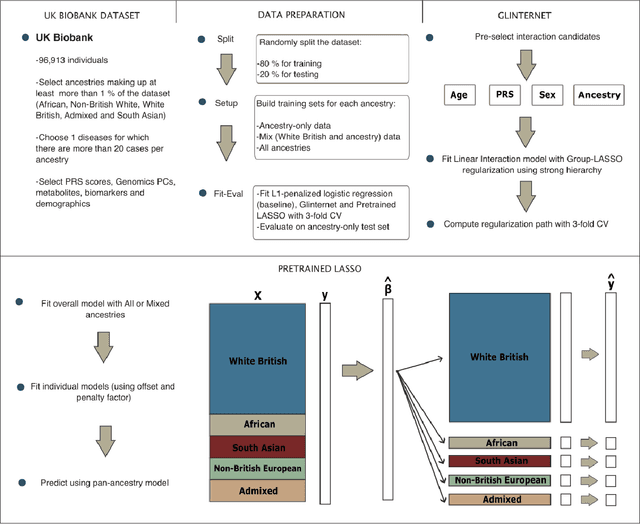
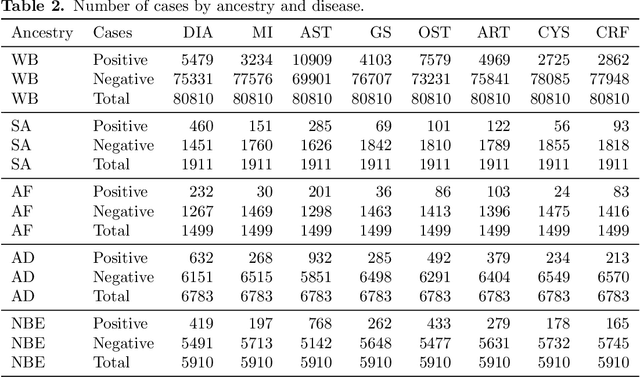
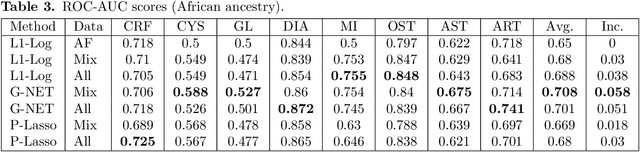
Recent genome-wide association studies (GWAS) have uncovered the genetic basis of complex traits, but show an under-representation of non-European descent individuals, underscoring a critical gap in genetic research. Here, we assess whether we can improve disease prediction across diverse ancestries using multiomic data. We evaluate the performance of Group-LASSO INTERaction-NET (glinternet) and pretrained lasso in disease prediction focusing on diverse ancestries in the UK Biobank. Models were trained on data from White British and other ancestries and validated across a cohort of over 96,000 individuals for 8 diseases. Out of 96 models trained, we report 16 with statistically significant incremental predictive performance in terms of ROC-AUC scores. These findings suggest that advanced statistical methods that borrow information across multiple ancestries may improve disease risk prediction, but with limited benefit.