 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefining CART Models for Covariate Shift with Importance Weight
Oct 28, 2024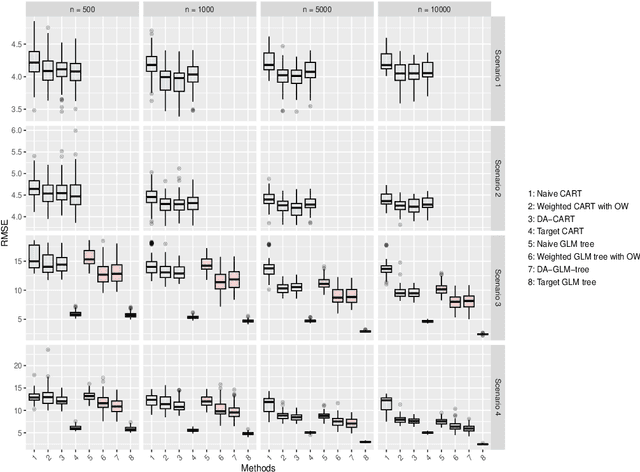



Machine learning models often face challenges in medical applications due to covariate shifts, where discrepancies between training and target data distributions can decrease predictive accuracy. This paper introduces an adaptation of Classification and Regression Trees (CART) that incorporates importance weighting to address these distributional differences effectively. By assigning greater weight to training samples that closely represent the target distribution, our approach modifies the CART model to improve performance in the presence of covariate shift. We evaluate the effectiveness of this method through simulation studies and apply it to real-world medical data, showing significant improvements in predictive accuracy. The results indicate that this weighted CART approach can be valuable in medical and other fields where covariate shift poses challenges, enabling more reliable predictions across diverse data distributions.
Co-data Learning for Bayesian Additive Regression Trees
Nov 16, 2023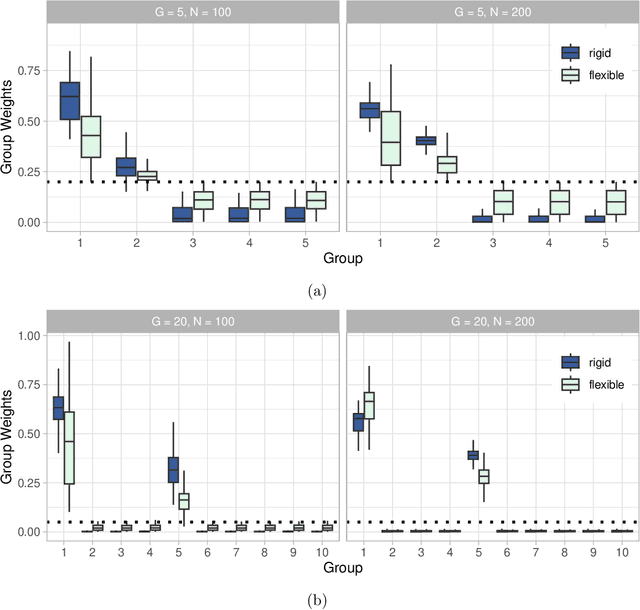
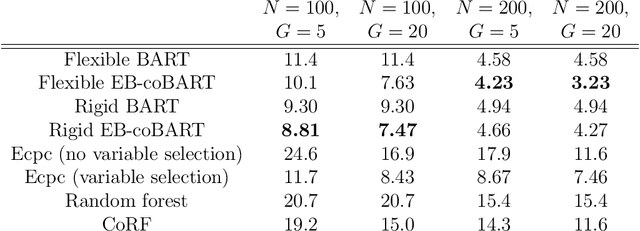
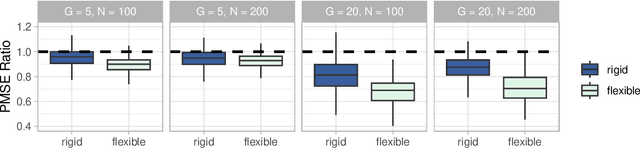
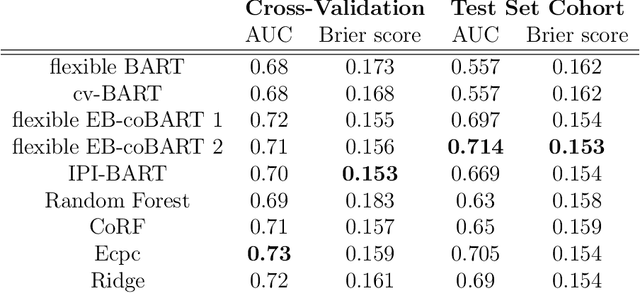
Medical prediction applications often need to deal with small sample sizes compared to the number of covariates. Such data pose problems for prediction and variable selection, especially when the covariate-response relationship is complicated. To address these challenges, we propose to incorporate co-data, i.e. external information on the covariates, into Bayesian additive regression trees (BART), a sum-of-trees prediction model that utilizes priors on the tree parameters to prevent overfitting. To incorporate co-data, an empirical Bayes (EB) framework is developed that estimates, assisted by a co-data model, prior covariate weights in the BART model. The proposed method can handle multiple types of co-data simultaneously. Furthermore, the proposed EB framework enables the estimation of the other hyperparameters of BART as well, rendering an appealing alternative to cross-validation. We show that the method finds relevant covariates and that it improves prediction compared to default BART in simulations. If the covariate-response relationship is nonlinear, the method benefits from the flexibility of BART to outperform regression-based co-data learners. Finally, the use of co-data enhances prediction in an application to diffuse large B-cell lymphoma prognosis based on clinical covariates, gene mutations, DNA translocations, and DNA copy number data. Keywords: Bayesian additive regression trees; Empirical Bayes; Co-data; High-dimensional data; Omics; Prediction
Estimation of Predictive Performance in High-Dimensional Data Settings using Learning Curves
Jun 08, 2022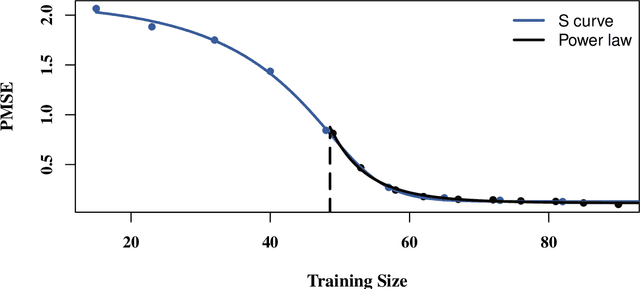

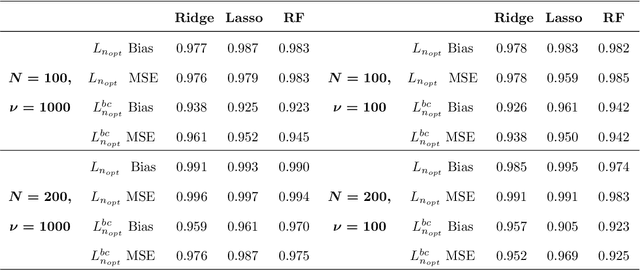

In high-dimensional prediction settings, it remains challenging to reliably estimate the test performance. To address this challenge, a novel performance estimation framework is presented. This framework, called Learn2Evaluate, is based on learning curves by fitting a smooth monotone curve depicting test performance as a function of the sample size. Learn2Evaluate has several advantages compared to commonly applied performance estimation methodologies. Firstly, a learning curve offers a graphical overview of a learner. This overview assists in assessing the potential benefit of adding training samples and it provides a more complete comparison between learners than performance estimates at a fixed subsample size. Secondly, a learning curve facilitates in estimating the performance at the total sample size rather than a subsample size. Thirdly, Learn2Evaluate allows the computation of a theoretically justified and useful lower confidence bound. Furthermore, this bound may be tightened by performing a bias correction. The benefits of Learn2Evaluate are illustrated by a simulation study and applications to omics data.
Estimating Bayesian Optimal Treatment Regimes for Dichotomous Outcomes using Observational Data
Sep 28, 2018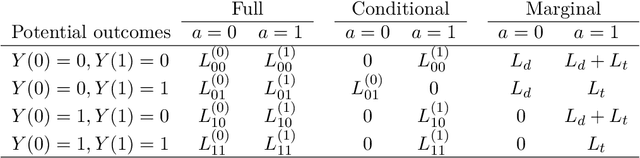
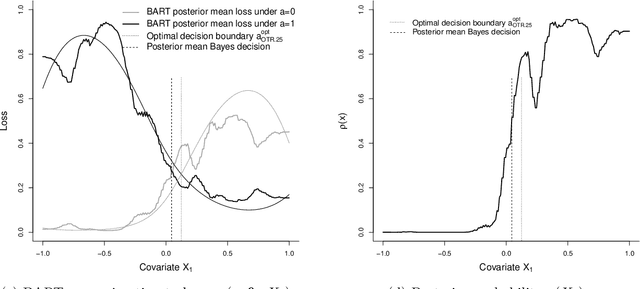


Optimal treatment regimes (OTR) are individualised treatment assignment strategies that identify a medical treatment as optimal given all background information available on the individual. We discuss Bayes optimal treatment regimes estimated using a loss function defined on the bivariate distribution of dichotomous potential outcomes. The proposed approach allows considering more general objectives for the OTR than maximization of an expected outcome (e.g., survival probability) by taking into account, for example, unnecessary treatment burden. As a motivating example we consider the case of oropharynx cancer treatment where unnecessary burden due to chemotherapy is to be avoided while maximizing survival chances. Assuming ignorable treatment assignment we describe Bayesian inference about the OTR including a sensitivity analysis on the unobserved partial association of the potential outcomes. We evaluate the methodology by simulations that apply Bayesian parametric and more flexible non-parametric outcome models. The proposed OTR for oropharynx cancer reduces the frequency of the more burdensome chemotherapy assignment by approximately 75% without reducing the average survival probability. This regime thus offers a strong increase in expected quality of life of patients.