 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARIA: Adversarially Robust Image Attribution for Content Provenance
Feb 25, 2022
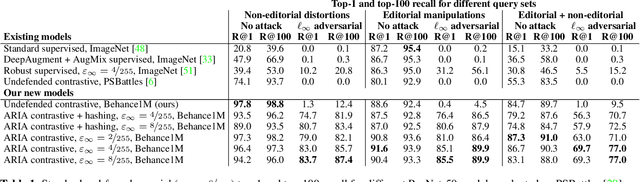

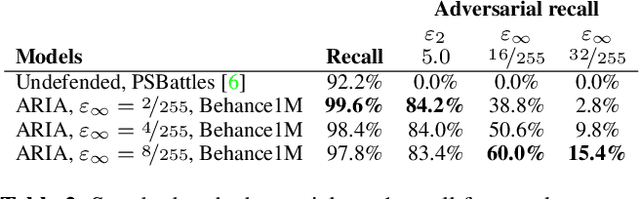
Image attribution -- matching an image back to a trusted source -- is an emerging tool in the fight against online misinformation. Deep visual fingerprinting models have recently been explored for this purpose. However, they are not robust to tiny input perturbations known as adversarial examples. First we illustrate how to generate valid adversarial images that can easily cause incorrect image attribution. Then we describe an approach to prevent imperceptible adversarial attacks on deep visual fingerprinting models, via robust contrastive learning. The proposed training procedure leverages training on $\ell_\infty$-bounded adversarial examples, it is conceptually simple and incurs only a small computational overhead. The resulting models are substantially more robust, are accurate even on unperturbed images, and perform well even over a database with millions of images. In particular, we achieve 91.6% standard and 85.1% adversarial recall under $\ell_\infty$-bounded perturbations on manipulated images compared to 80.1% and 0.0% from prior work. We also show that robustness generalizes to other types of imperceptible perturbations unseen during training. Finally, we show how to train an adversarially robust image comparator model for detecting editorial changes in matched images.
Robust Synthesis of Adversarial Visual Examples Using a Deep Image Prior
Jul 03, 2019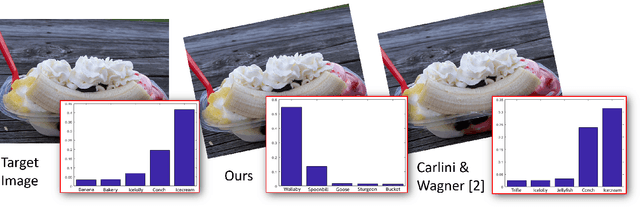
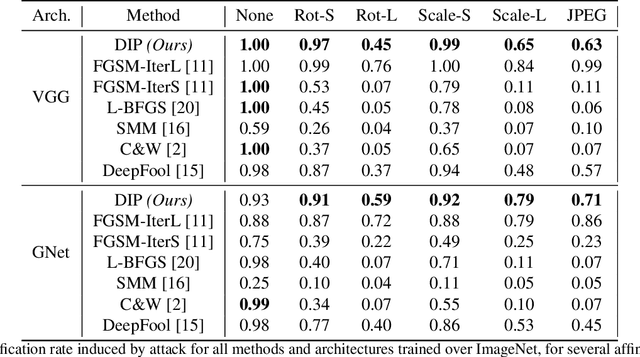
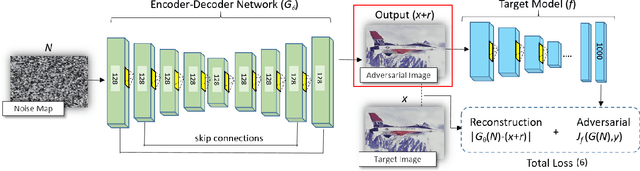
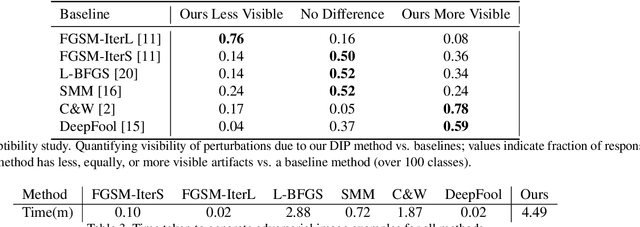
We present a novel method for generating robust adversarial image examples building upon the recent `deep image prior' (DIP) that exploits convolutional network architectures to enforce plausible texture in image synthesis. Adversarial images are commonly generated by perturbing images to introduce high frequency noise that induces image misclassification, but that is fragile to subsequent digital manipulation of the image. We show that using DIP to reconstruct an image under adversarial constraint induces perturbations that are more robust to affine deformation, whilst remaining visually imperceptible. Furthermore we show that our DIP approach can also be adapted to produce local adversarial patches (`adversarial stickers'). We demonstrate robust adversarial examples over a broad gamut of images and object classes drawn from the ImageNet dataset.