 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinistral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
The Data-Quality Illusion: Rethinking Classifier-Based Quality Filtering for LLM Pretraining
Oct 02, 2025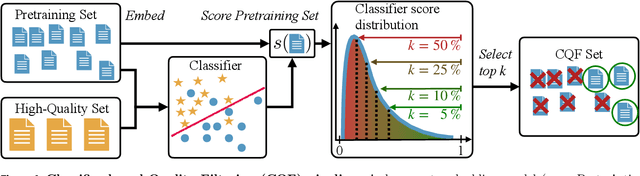
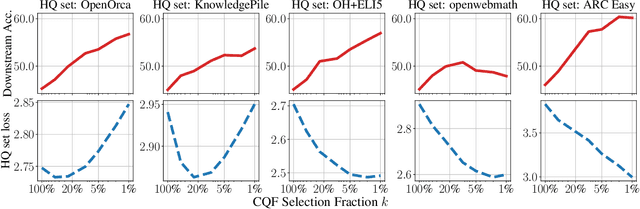
Large-scale models are pretrained on massive web-crawled datasets containing documents of mixed quality, making data filtering essential. A popular method is Classifier-based Quality Filtering (CQF), which trains a binary classifier to distinguish between pretraining data and a small, high-quality set. It assigns each pretraining document a quality score defined as the classifier's score and retains only the top-scoring ones. We provide an in-depth analysis of CQF. We show that while CQF improves downstream task performance, it does not necessarily enhance language modeling on the high-quality dataset. We explain this paradox by the fact that CQF implicitly filters the high-quality dataset as well. We further compare the behavior of models trained with CQF to those trained on synthetic data of increasing quality, obtained via random token permutations, and find starkly different trends. Our results challenge the view that CQF captures a meaningful notion of data quality.
Mind the Gap: a Spectral Analysis of Rank Collapse and Signal Propagation in Transformers
Oct 10, 2024Attention layers are the core component of transformers, the current state-of-the-art neural network architecture. However, \softmaxx-based attention puts transformers' trainability at risk. Even \textit{at initialisation}, the propagation of signals and gradients through the random network can be pathological, resulting in known issues such as (i) vanishing/exploding gradients and (ii) \textit{rank collapse}, i.e. when all tokens converge to a single representation \textit{with depth}. This paper examines signal propagation in \textit{attention-only} transformers from a random matrix perspective, illuminating the origin of such issues, as well as unveiling a new phenomenon -- (iii) rank collapse \textit{in width}. Modelling \softmaxx-based attention at initialisation with Random Markov matrices, our theoretical analysis reveals that a \textit{spectral gap} between the two largest singular values of the attention matrix causes (iii), which, in turn, exacerbates (i) and (ii). Building on this insight, we propose a novel, yet simple, practical solution to resolve rank collapse in width by removing the spectral gap. Moreover, we validate our findings and discuss the training benefits of the proposed fix through experiments that also motivate a revision of some of the default parameter scaling. Our attention model accurately describes the standard key-query attention in a single-layer transformer, making this work a significant first step towards a better understanding of the initialisation dynamics in the multi-layer case.
CARMIL: Context-Aware Regularization on Multiple Instance Learning models for Whole Slide Images
Aug 01, 2024



Multiple Instance Learning (MIL) models have proven effective for cancer prognosis from Whole Slide Images. However, the original MIL formulation incorrectly assumes the patches of the same image to be independent, leading to a loss of spatial context as information flows through the network. Incorporating contextual knowledge into predictions is particularly important given the inclination for cancerous cells to form clusters and the presence of spatial indicators for tumors. State-of-the-art methods often use attention mechanisms eventually combined with graphs to capture spatial knowledge. In this paper, we take a novel and transversal approach, addressing this issue through the lens of regularization. We propose Context-Aware Regularization for Multiple Instance Learning (CARMIL), a versatile regularization scheme designed to seamlessly integrate spatial knowledge into any MIL model. Additionally, we present a new and generic metric to quantify the Context-Awareness of any MIL model when applied to Whole Slide Images, resolving a previously unexplored gap in the field. The efficacy of our framework is evaluated for two survival analysis tasks on glioblastoma (TCGA GBM) and colon cancer data (TCGA COAD).
On the Initialisation of Wide Low-Rank Feedforward Neural Networks
Jan 31, 2023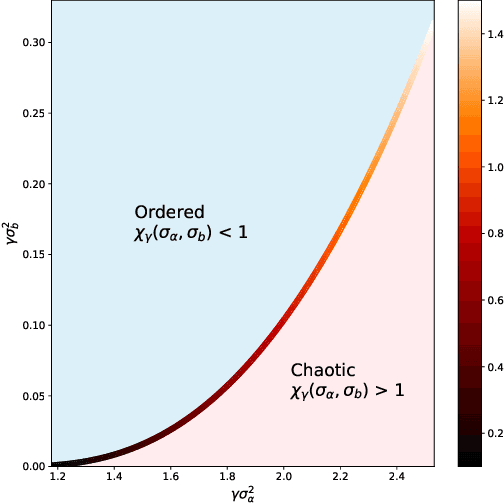
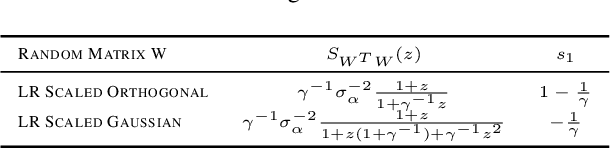
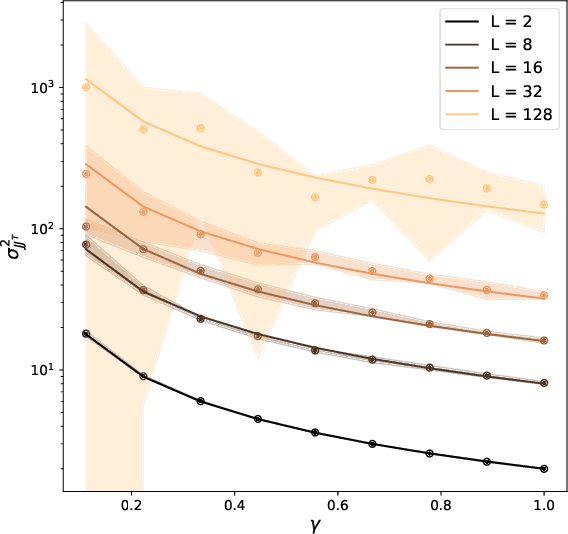
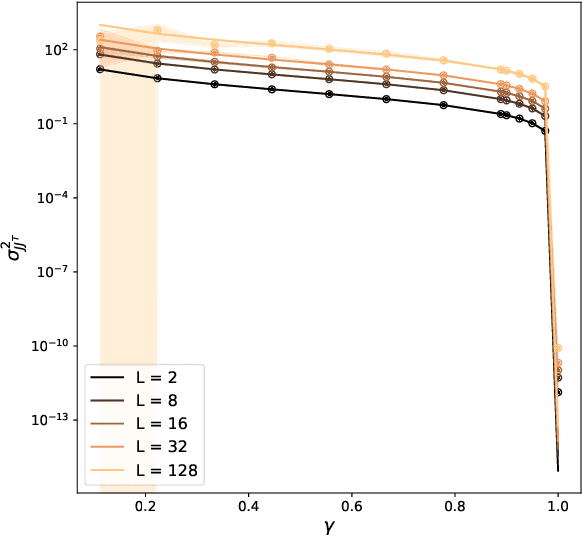
The edge-of-chaos dynamics of wide randomly initialized low-rank feedforward networks are analyzed. Formulae for the optimal weight and bias variances are extended from the full-rank to low-rank setting and are shown to follow from multiplicative scaling. The principle second order effect, the variance of the input-output Jacobian, is derived and shown to increase as the rank to width ratio decreases. These results inform practitioners how to randomly initialize feedforward networks with a reduced number of learnable parameters while in the same ambient dimension, allowing reductions in the computational cost and memory constraints of the associated network.