 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Reuse of Previous Experiences to Improve Policies in Real Environment
May 10, 2014

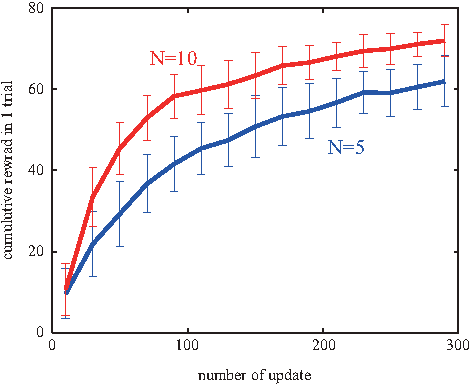

In this study, we show that a movement policy can be improved efficiently using the previous experiences of a real robot. Reinforcement Learning (RL) is becoming a popular approach to acquire a nonlinear optimal policy through trial and error. However, it is considered very difficult to apply RL to real robot control since it usually requires many learning trials. Such trials cannot be executed in real environments because unrealistic time is necessary and the real system's durability is limited. Therefore, in this study, instead of executing many learning trials, we propose to use a recently developed RL algorithm, importance-weighted PGPE, by which the robot can efficiently reuse previously sampled data to improve it's policy parameters. We apply importance-weighted PGPE to CB-i, our real humanoid robot, and show that it can learn a target reaching movement and a cart-pole swing up movement in a real environment without using any prior knowledge of the task or any carefully designed initial trajectory.