 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning For Survival, A Clinically Motivated Method For Critically Ill Patients
Jul 19, 2022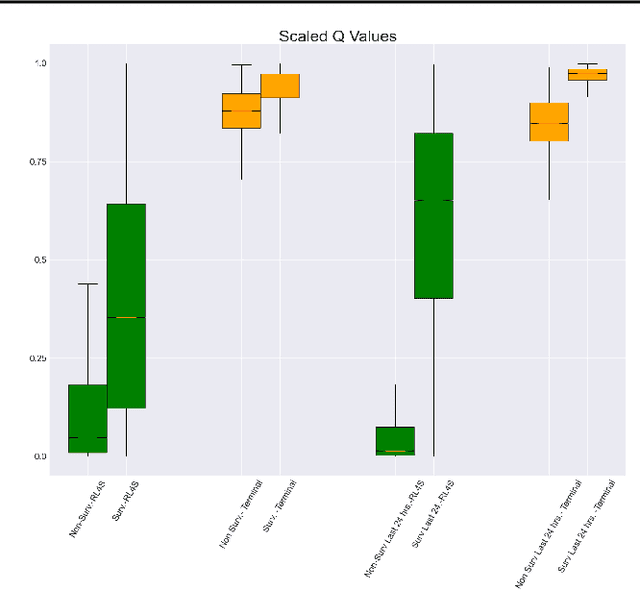
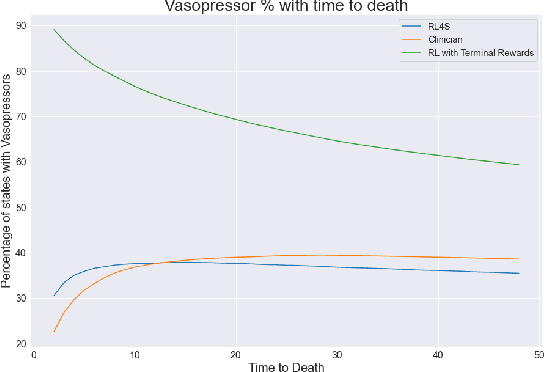
There has been considerable interest in leveraging RL and stochastic control methods to learn optimal treatment strategies for critically ill patients, directly from observational data. However, there is significant ambiguity on the control objective and on the best reward choice for the standard RL objective. In this work, we propose a clinically motivated control objective for critically ill patients, for which the value functions have a simple medical interpretation. Further, we present theoretical results and adapt our method to a practical Deep RL algorithm, which can be used alongside any value based Deep RL method. We experiment on a large sepsis cohort and show that our method produces results consistent with clinical knowledge.
Deep Normed Embeddings for Patient Representation
Apr 12, 2022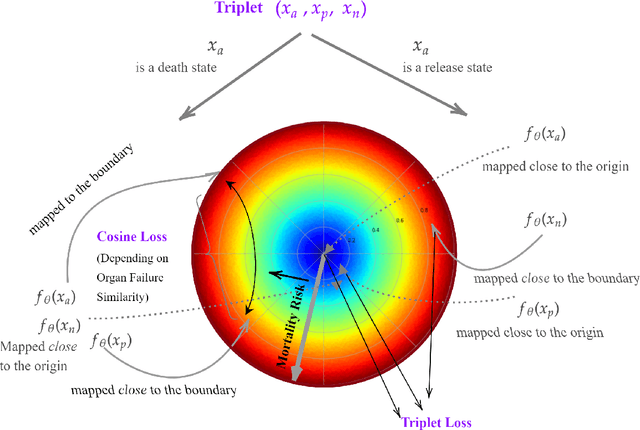

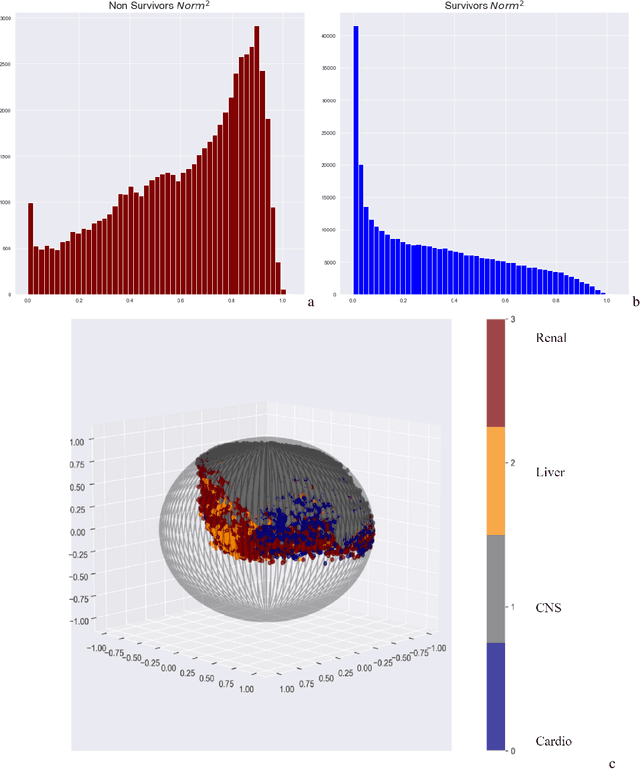

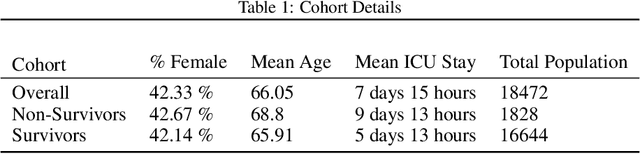
We introduce a novel contrastive representation learning objective and a training scheme for clinical time series. Specifically, we project high dimensional E.H.R. data to a closed unit ball of low dimension, encoding geometric priors so that the origin represents an idealized perfect health state and the euclidean norm is associated with the patient's mortality risk. Moreover, using septic patients as an example, we show how we could learn to associate the angle between two vectors with the different organ system failures, thereby, learning a compact representation which is indicative of both mortality risk and specific organ failure. We show how the learned embedding can be used for online patient monitoring, supplement clinicians and improve performance of downstream machine learning tasks. This work was partially motivated from the desire and the need to introduce a systematic way of defining intermediate rewards for Reinforcement Learning in critical care medicine. Hence, we also show how such a design in terms of the learned embedding can result in qualitatively different policies and value distributions, as compared with using only terminal rewards.
Unifying Cardiovascular Modelling with Deep Reinforcement Learning for Uncertainty Aware Control of Sepsis Treatment
Feb 02, 2021


Sepsis is the leading cause of mortality in the ICU, responsible for 6% of all hospitalizations and 35% of all in-hospital deaths in USA. However, there is no universally agreed upon strategy for vasopressor and fluid administration. It has also been observed that different patients respond differently to treatment, highlighting the need for individualized treatment. Vasopressors and fluids are administrated with specific effects to cardiovascular physiology in mind and medical research has suggested that physiologic, hemodynamically guided, approaches to treatment. Thus we propose a novel approach, exploiting and unifying complementary strengths of Mathematical Modelling, Deep Learning, Reinforcement Learning and Uncertainty Quantification, to learn individualized, safe, and uncertainty aware treatment strategies. We first infer patient-specific, dynamic cardiovascular states using a novel physiology-driven recurrent neural network trained in an unsupervised manner. This information, along with a learned low dimensional representation of the patient's lab history and observable data, is then used to derive value distributions using Batch Distributional Reinforcement Learning. Moreover in a safety critical domain it is essential to know what our agent does and does not know, for this we also quantify the model uncertainty associated with each patient state and action, and propose a general framework for uncertainty aware, interpretable treatment policies. This framework can be tweaked easily, to reflect a clinician's own confidence of the framework, and can be easily modified to factor in human expert opinion, whenever it's accessible. Using representative patients and a validation cohort, we show that our method has learned physiologically interpretable generalizable policies.