Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning For Survival, A Clinically Motivated Method For Critically Ill Patients
Paper and Code
Jul 19, 2022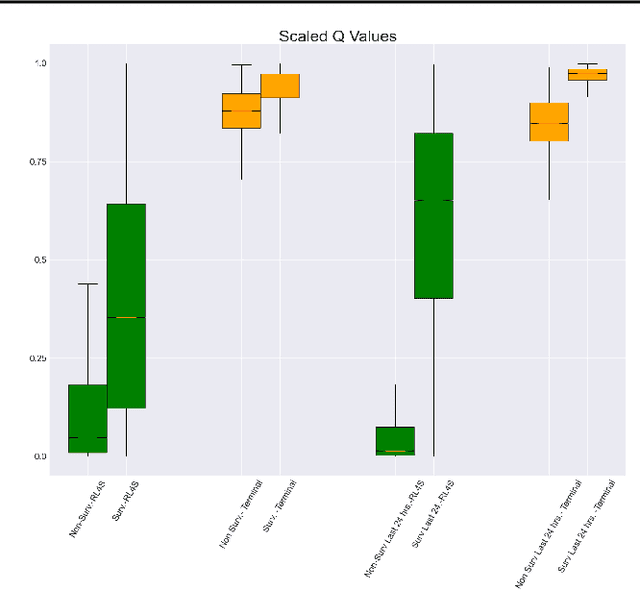
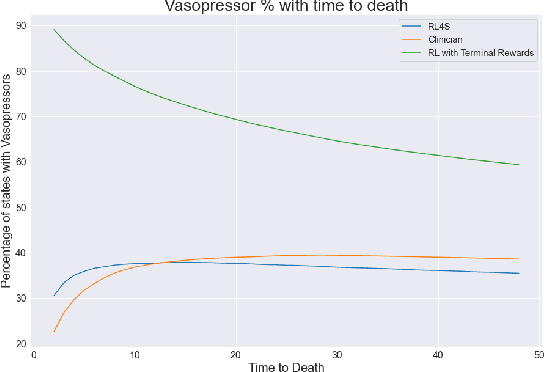
There has been considerable interest in leveraging RL and stochastic control methods to learn optimal treatment strategies for critically ill patients, directly from observational data. However, there is significant ambiguity on the control objective and on the best reward choice for the standard RL objective. In this work, we propose a clinically motivated control objective for critically ill patients, for which the value functions have a simple medical interpretation. Further, we present theoretical results and adapt our method to a practical Deep RL algorithm, which can be used alongside any value based Deep RL method. We experiment on a large sepsis cohort and show that our method produces results consistent with clinical knowledge.
View paper on