 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Explainable Depression Identification from Speech Using Vowel-Based Ensemble Learning Approaches
Oct 23, 2024This study investigates explainable machine learning algorithms for identifying depression from speech. Grounded in evidence from speech production that depression affects motor control and vowel generation, pre-trained vowel-based embeddings, that integrate semantically meaningful linguistic units, are used. Following that, an ensemble learning approach decomposes the problem into constituent parts characterized by specific depression symptoms and severity levels. Two methods are explored: a "bottom-up" approach with 8 models predicting individual Patient Health Questionnaire-8 (PHQ-8) item scores, and a "top-down" approach using a Mixture of Experts (MoE) with a router module for assessing depression severity. Both methods depict performance comparable to state-of-the-art baselines, demonstrating robustness and reduced susceptibility to dataset mean/median values. System explainability benefits are discussed highlighting their potential to assist clinicians in depression diagnosis and screening.
A knowledge-driven vowel-based approach of depression classification from speech using data augmentation
Oct 27, 2022We propose a novel explainable machine learning (ML) model that identifies depression from speech, by modeling the temporal dependencies across utterances and utilizing the spectrotemporal information at the vowel level. Our method first models the variable-length utterances at the local-level into a fixed-size vowel-based embedding using a convolutional neural network with a spatial pyramid pooling layer ("vowel CNN"). Following that, the depression is classified at the global-level from a group of vowel CNN embeddings that serve as the input of another 1D CNN ("depression CNN"). Different data augmentation methods are designed for both the training of vowel CNN and depression CNN. We investigate the performance of the proposed system at various temporal granularities when modeling short, medium, and long analysis windows, corresponding to 10, 21, and 42 utterances, respectively. The proposed method reaches comparable performance with previous state-of-the-art approaches and depicts explainable properties with respect to the depression outcome. The findings from this work may benefit clinicians by providing additional intuitions during joint human-ML decision-making tasks.
A few-shot learning approach with domain adaptation for personalized real-life stress detection in close relationships
Oct 27, 2022We design a metric learning approach that aims to address computational challenges that yield from modeling human outcomes from ambulatory real-life data. The proposed metric learning is based on a Siamese neural network (SNN) that learns the relative difference between pairs of samples from a target user and non-target users, thus being able to address the scarcity of labelled data from the target. The SNN further minimizes the Wasserstein distance of the learned embeddings between target and non-target users, thus mitigating the distribution mismatch between the two. Finally, given the fact that the base rate of focal behaviors is different per user, the proposed method approximates the focal base rate based on labelled samples that lay closest to the target, based on which further minimizes the Wasserstein distance. Our method is exemplified for the purpose of hourly stress classification using real-life multimodal data from 72 dating couples. Results in few-shot and one-shot learning experiments indicate that proposed formulation benefits stress classification and can help mitigate the aforementioned challenges.
Toward Knowledge-Driven Speech-Based Models of Depression: Leveraging Spectrotemporal Variations in Speech Vowels
Oct 05, 2022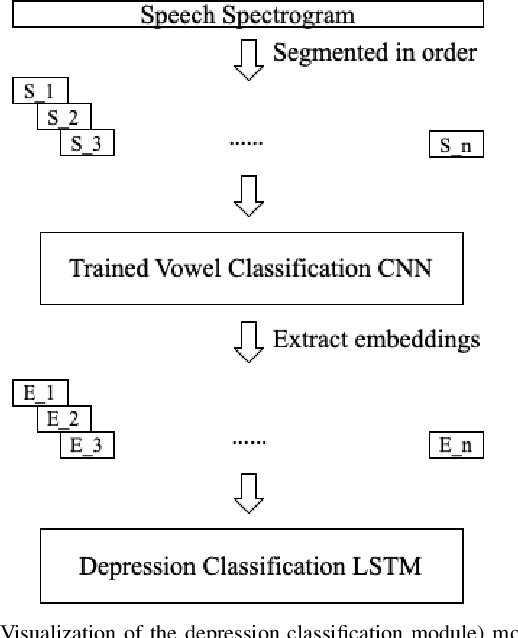
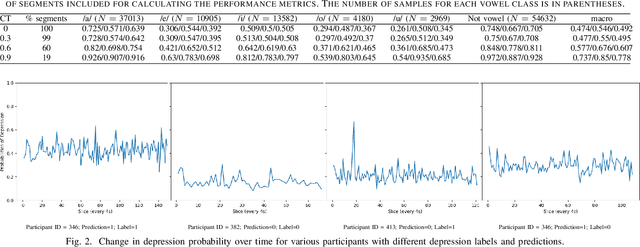


Psychomotor retardation associated with depression has been linked with tangible differences in vowel production. This paper investigates a knowledge-driven machine learning (ML) method that integrates spectrotemporal information of speech at the vowel-level to identify the depression. Low-level speech descriptors are learned by a convolutional neural network (CNN) that is trained for vowel classification. The temporal evolution of those low-level descriptors is modeled at the high-level within and across utterances via a long short-term memory (LSTM) model that takes the final depression decision. A modified version of the Local Interpretable Model-agnostic Explanations (LIME) is further used to identify the impact of the low-level spectrotemporal vowel variation on the decisions and observe the high-level temporal change of the depression likelihood. The proposed method outperforms baselines that model the spectrotemporal information in speech without integrating the vowel-based information, as well as ML models trained with conventional prosodic and spectrotemporal features. The conducted explainability analysis indicates that spectrotemporal information corresponding to non-vowel segments less important than the vowel-based information. Explainability of the high-level information capturing the segment-by-segment decisions is further inspected for participants with and without depression. The findings from this work can provide the foundation toward knowledge-driven interpretable decision-support systems that can assist clinicians to better understand fine-grain temporal changes in speech data, ultimately augmenting mental health diagnosis and care.
Predicting the meal macronutrient composition from continuous glucose monitors
Jun 23, 2022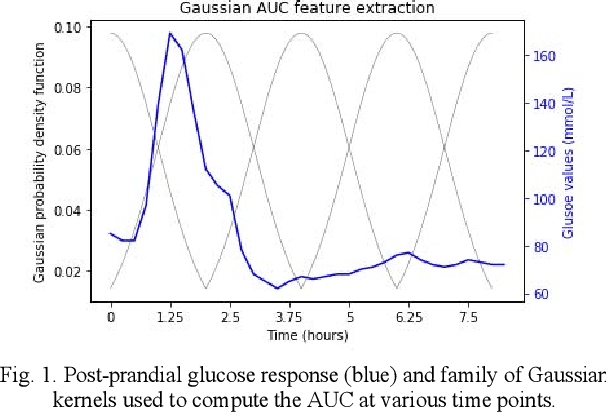
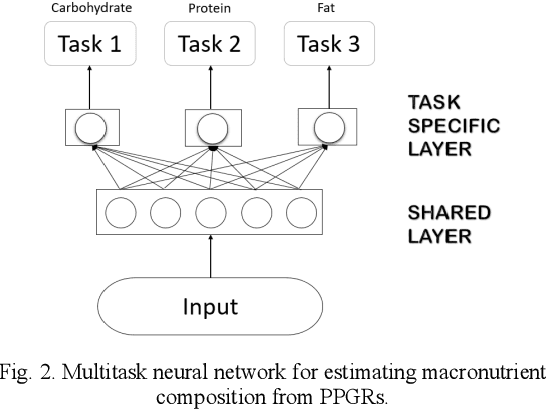
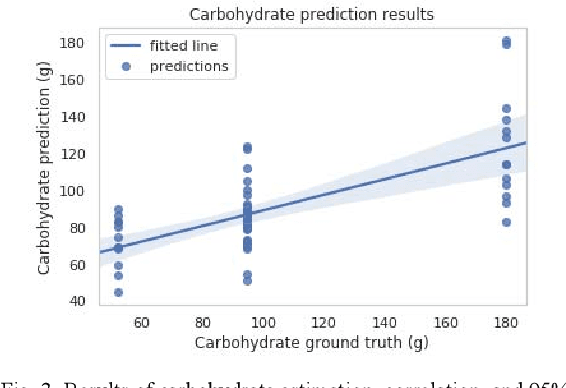
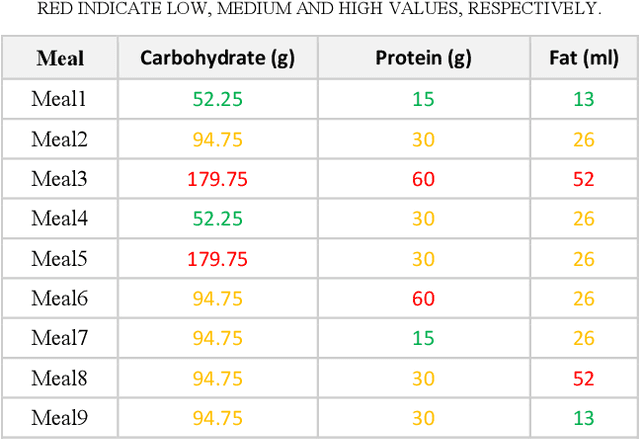
Sustained high levels of blood glucose in type 2 diabetes (T2DM) can have disastrous long-term health consequences. An essential component of clinical interventions for T2DM is monitoring dietary intake to keep plasma glucose levels within an acceptable range. Yet, current techniques to monitor food intake are time intensive and error prone. To address this issue, we are developing techniques to automatically monitor food intake and the composition of those foods using continuous glucose monitors (CGMs). This article presents the results of a clinical study in which participants consumed nine standardized meals with known macronutrients amounts (carbohydrate, protein, and fat) while wearing a CGM. We built a multitask neural network to estimate the macronutrient composition from the CGM signal, and compared it against a baseline linear regression. The best prediction result comes from our proposed neural network, trained with subject-dependent data, as measured by root mean squared relative error and correlation coefficient. These findings suggest that it is possible to estimate macronutrient composition from CGM signals, opening the possibility to develop automatic techniques to track food intake.
Few-shot Learning in Emotion Recognition of Spontaneous Speech Using a Siamese Neural Network with Adaptive Sample Pair Formation
Sep 07, 2021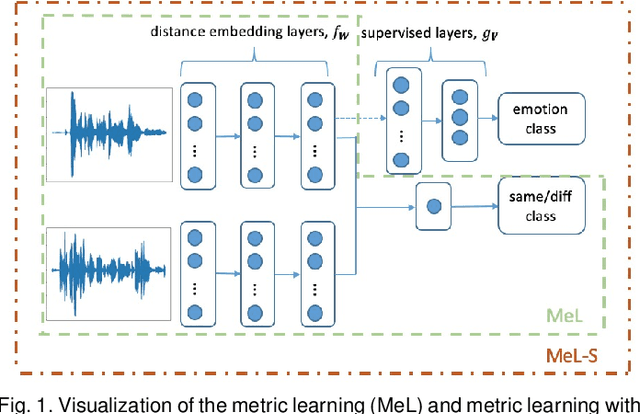

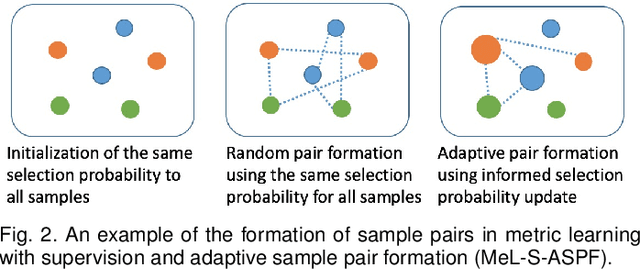
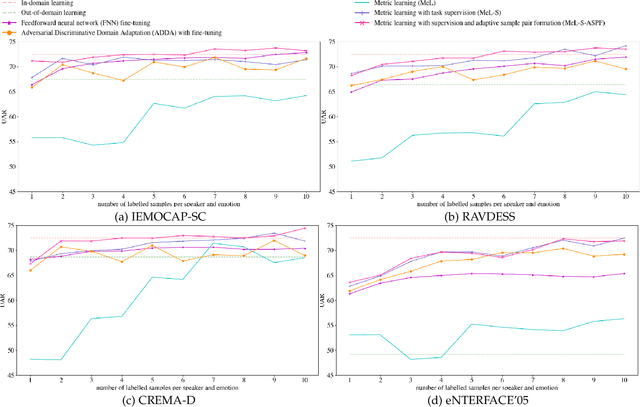
Speech-based machine learning (ML) has been heralded as a promising solution for tracking prosodic and spectrotemporal patterns in real-life that are indicative of emotional changes, providing a valuable window into one's cognitive and mental state. Yet, the scarcity of labelled data in ambulatory studies prevents the reliable training of ML models, which usually rely on "data-hungry" distribution-based learning. Leveraging the abundance of labelled speech data from acted emotions, this paper proposes a few-shot learning approach for automatically recognizing emotion in spontaneous speech from a small number of labelled samples. Few-shot learning is implemented via a metric learning approach through a siamese neural network, which models the relative distance between samples rather than relying on learning absolute patterns of the corresponding distributions of each emotion. Results indicate the feasibility of the proposed metric learning in recognizing emotions from spontaneous speech in four datasets, even with a small amount of labelled samples. They further demonstrate superior performance of the proposed metric learning compared to commonly used adaptation methods, including network fine-tuning and adversarial learning. Findings from this work provide a foundation for the ambulatory tracking of human emotion in spontaneous speech contributing to the real-life assessment of mental health degradation.
A Siamese Neural Network with Modified Distance Loss For Transfer Learning in Speech Emotion Recognition
Jun 04, 2020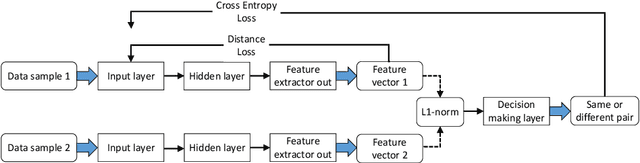

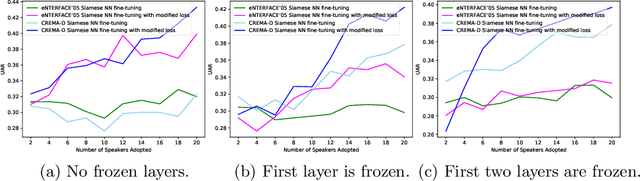
Automatic emotion recognition plays a significant role in the process of human computer interaction and the design of Internet of Things (IOT) technologies. Yet, a common problem in emotion recognition systems lies in the scarcity of reliable labels. By modeling pairwise differences between samples of interest, a Siamese network can help to mitigate this challenge since it requires fewer samples than traditional deep learning methods. In this paper, we propose a distance loss, which can be applied on the Siamese network fine-tuning, by optimizing the model based on the relevant distance between same and difference class pairs. Our system use samples from the source data to pre-train the weights of proposed Siamese neural network, which are fine-tuned based on the target data. We present an emotion recognition task that uses speech, since it is one of the most ubiquitous and frequently used bio-behavioral signals. Our target data comes from the RAVDESS dataset, while the CREMA-D and eNTERFACE'05 are used as source data, respectively. Our results indicate that the proposed distance loss is able to greatly benefit the fine-tuning process of Siamese network. Also, the selection of source data has more effect on the Siamese network performance compared to the number of frozen layers. These suggest the great potential of applying the Siamese network and modelling pairwise differences in the field of transfer learning for automatic emotion recognition.
An adversarial learning framework for preserving users' anonymity in face-based emotion recognition
Jan 16, 2020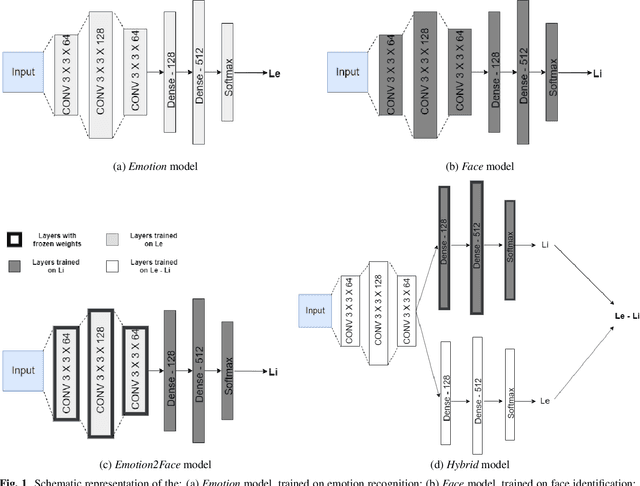

Image and video-capturing technologies have permeated our every-day life. Such technologies can continuously monitor individuals' expressions in real-life settings, affording us new insights into their emotional states and transitions, thus paving the way to novel well-being and healthcare applications. Yet, due to the strong privacy concerns, the use of such technologies is met with strong skepticism, since current face-based emotion recognition systems relying on deep learning techniques tend to preserve substantial information related to the identity of the user, apart from the emotion-specific information. This paper proposes an adversarial learning framework which relies on a convolutional neural network (CNN) architecture trained through an iterative procedure for minimizing identity-specific information and maximizing emotion-dependent information. The proposed approach is evaluated through emotion classification and face identification metrics, and is compared against two CNNs, one trained solely for emotion recognition and the other trained solely for face identification. Experiments are performed using the Yale Face Dataset and Japanese Female Facial Expression Database. Results indicate that the proposed approach can learn a convolutional transformation for preserving emotion recognition accuracy and degrading face identity recognition, providing a foundation toward privacy-aware emotion recognition technologies.