 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Neural Network based on Phase Space for BCI decoding
Mar 08, 2024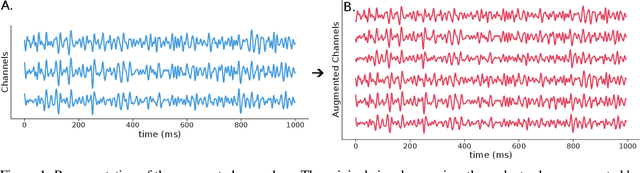

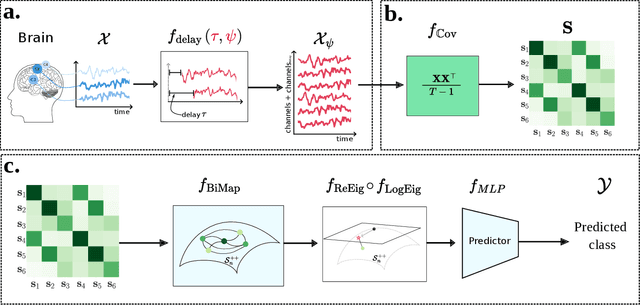
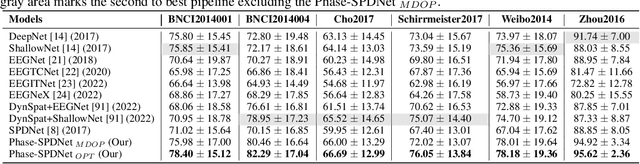
The integration of Deep Learning (DL) algorithms on brain signal analysis is still in its nascent stages compared to their success in fields like Computer Vision, especially in Brain-Computer Interface (BCI), where the brain activity is decoded to control external devices without requiring muscle control. Electroencephalography (EEG) is a widely adopted choice for designing BCI systems due to its non-invasive and cost-effective nature and excellent temporal resolution. Still, it comes at the expense of limited training data, poor signal-to-noise, and a large variability across and within-subject recordings. Finally, setting up a BCI system with many electrodes takes a long time, hindering the widespread adoption of reliable DL architectures in BCIs outside research laboratories. To improve adoption, we need to improve user comfort using, for instance, reliable algorithms that operate with few electrodes. \textbf{Approach:} Our research aims to develop a DL algorithm that delivers effective results with a limited number of electrodes. Taking advantage of the Augmented Covariance Method with SPDNet, we propose the SPDNet$_{\psi}$ architecture and analyze its performance and computational impact, as well as the interpretability of the results. The evaluation is conducted on 5-fold cross-validation, using only three electrodes positioned above the Motor Cortex. The methodology was tested on nearly 100 subjects from several open-source datasets using the Mother Of All BCI Benchmark (MOABB) framework. \textbf{Main results:} The results of our SPDNet$_{\psi}$ demonstrate that the augmented approach combined with the SPDNet significantly outperforms all the current state-of-the-art DL architecture in MI decoding. \textbf{Significance:} This new architecture is explainable, with a low number of trainable parameters and a reduced carbon footprint.
Pseudo-online framework for BCI evaluation: A MOABB perspective
Aug 21, 2023Objective: BCI (Brain-Computer Interface) technology operates in three modes: online, offline, and pseudo-online. In the online mode, real-time EEG data is constantly analyzed. In offline mode, the signal is acquired and processed afterwards. The pseudo-online mode processes collected data as if they were received in real-time. The main difference is that the offline mode often analyzes the whole data, while the online and pseudo-online modes only analyze data in short time windows. Offline analysis is usually done with asynchronous BCIs, which restricts analysis to predefined time windows. Asynchronous BCI, compatible with online and pseudo-online modes, allows flexible mental activity duration. Offline processing tends to be more accurate, while online analysis is better for therapeutic applications. Pseudo-online implementation approximates online processing without real-time constraints. Many BCI studies being offline introduce biases compared to real-life scenarios, impacting classification algorithm performance. Approach: The objective of this research paper is therefore to extend the current MOABB framework, operating in offline mode, so as to allow a comparison of different algorithms in a pseudo-online setting with the use of a technology based on overlapping sliding windows. To do this will require the introduction of a idle state event in the dataset that takes into account all different possibilities that are not task thinking. To validate the performance of the algorithms we will use the normalized Matthews Correlation Coefficient (nMCC) and the Information Transfer Rate (ITR). Main results: We analyzed the state-of-the-art algorithms of the last 15 years over several Motor Imagery (MI) datasets composed by several subjects, showing the differences between the two approaches from a statistical point of view. Significance: The ability to analyze the performance of different algorithms in offline and pseudo-online modes will allow the BCI community to obtain more accurate and comprehensive reports regarding the performance of classification algorithms.
Classification of BCI-EEG based on augmented covariance matrix
Feb 09, 2023



Objective: Electroencephalography signals are recorded as a multidimensional dataset. We propose a new framework based on the augmented covariance extracted from an autoregressive model to improve motor imagery classification. Methods: From the autoregressive model can be derived the Yule-Walker equations, which show the emergence of a symmetric positive definite matrix: the augmented covariance matrix. The state-of the art for classifying covariance matrices is based on Riemannian Geometry. A fairly natural idea is therefore to extend the standard approach using these augmented covariance matrices. The methodology for creating the augmented covariance matrix shows a natural connection with the delay embedding theorem proposed by Takens for dynamical systems. Such an embedding method is based on the knowledge of two parameters: the delay and the embedding dimension, respectively related to the lag and the order of the autoregressive model. This approach provides new methods to compute the hyper-parameters in addition to standard grid search. Results: The augmented covariance matrix performed noticeably better than any state-of-the-art methods. We will test our approach on several datasets and several subjects using the MOABB framework, using both within-session and cross-session evaluation. Conclusion: The improvement in results is due to the fact that the augmented covariance matrix incorporates not only spatial but also temporal information, incorporating nonlinear components of the signal through an embedding procedure, which allows the leveraging of dynamical systems algorithms. Significance: These results extend the concepts and the results of the Riemannian distance based classification algorithm.
Data-driven cortical clustering to provide a family of plausible solutions to M/EEG inverse problem
Dec 07, 2018
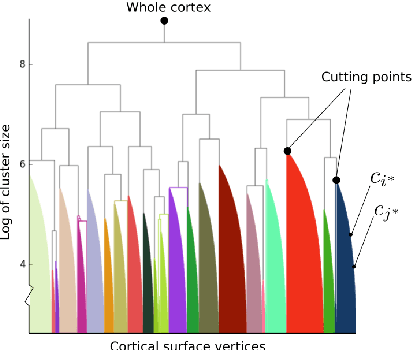
The M/EEG inverse problem is ill-posed. Thus additional hypotheses are needed to constrain the solution space. In this work, we consider that brain activity which generates an M/EEG signal is a connected cortical region. We study the case when only one region is active at once. We show that even in this simple case several configurations can explain the data. As opposed to methods based on convex optimization which are forced to select one possible solution, we propose an approach which is able to find several "good" candidates - regions which are different in term of their sizes and/or positions but fit the data with similar accuracy.
Jitter-Adaptive Dictionary Learning - Application to Multi-Trial Neuroelectric Signals
Jun 24, 2013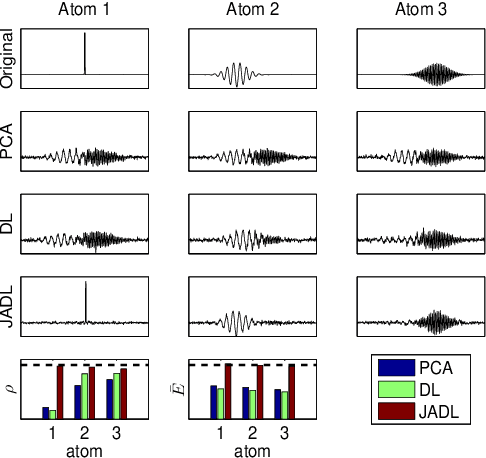

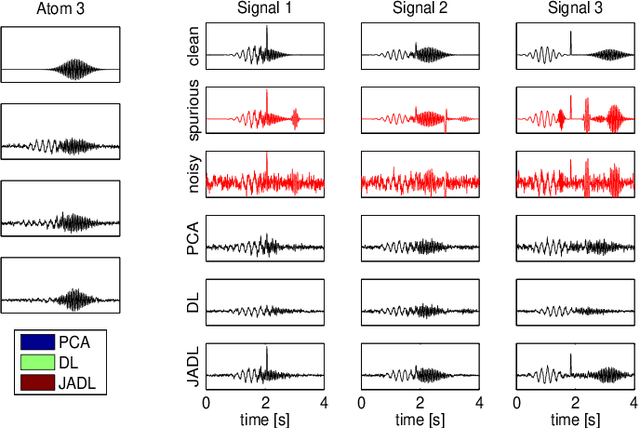
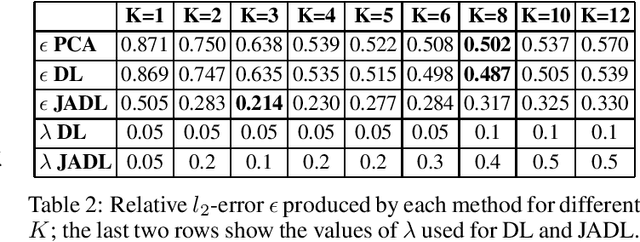
Dictionary Learning has proven to be a powerful tool for many image processing tasks, where atoms are typically defined on small image patches. As a drawback, the dictionary only encodes basic structures. In addition, this approach treats patches of different locations in one single set, which means a loss of information when features are well-aligned across signals. This is the case, for instance, in multi-trial magneto- or electroencephalography (M/EEG). Learning the dictionary on the entire signals could make use of the alignement and reveal higher-level features. In this case, however, small missalignements or phase variations of features would not be compensated for. In this paper, we propose an extension to the common dictionary learning framework to overcome these limitations by allowing atoms to adapt their position across signals. The method is validated on simulated and real neuroelectric data.