 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNumerical Approximation Capacity of Neural Networks with Bounded Parameters: Do Limits Exist, and How Can They Be Measured?
Sep 25, 2024
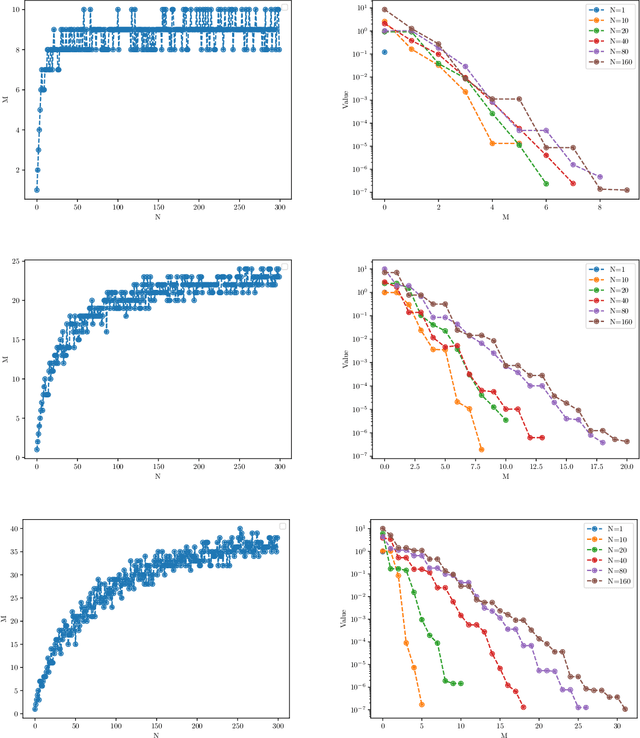
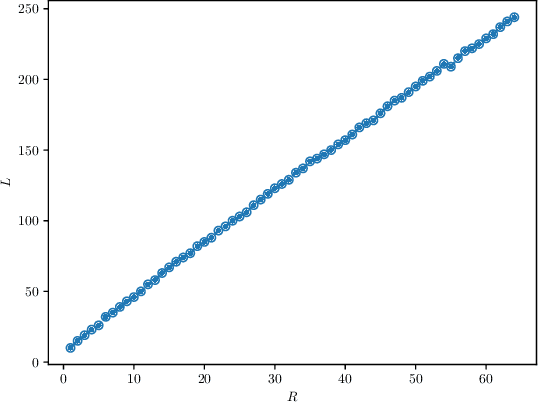
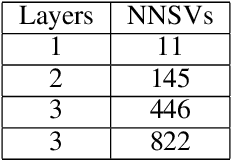
The Universal Approximation Theorem posits that neural networks can theoretically possess unlimited approximation capacity with a suitable activation function and a freely chosen or trained set of parameters. However, a more practical scenario arises when these neural parameters, especially the nonlinear weights and biases, are bounded. This leads us to question: \textbf{Does the approximation capacity of a neural network remain universal, or does it have a limit when the parameters are practically bounded? And if it has a limit, how can it be measured?} Our theoretical study indicates that while universal approximation is theoretically feasible, in practical numerical scenarios, Deep Neural Networks (DNNs) with any analytic activation functions (such as Tanh and Sigmoid) can only be approximated by a finite-dimensional vector space under a bounded nonlinear parameter space (NP space), whether in a continuous or discrete sense. Based on this study, we introduce the concepts of \textit{$\epsilon$ outer measure} and \textit{Numerical Span Dimension (NSdim)} to quantify the approximation capacity limit of a family of networks both theoretically and practically. Furthermore, drawing on our new theoretical study and adopting a fresh perspective, we strive to understand the relationship between back-propagation neural networks and random parameter networks (such as the Extreme Learning Machine (ELM)) with both finite and infinite width. We also aim to provide fresh insights into regularization, the trade-off between width and depth, parameter space, width redundancy, condensation, and other related important issues.
Bayesian optimization with local search
Nov 20, 2019


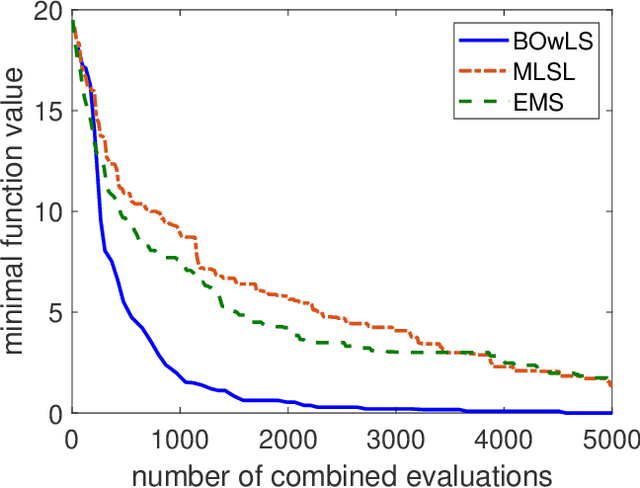
Global optimization finds applications in a wide range of real world problems. The multi-start methods are a popular class of global optimization techniques, which are based on the ideas of conducting local searches at multiple starting points, and then sequentially determine the starting points according to some prescribed rules. In this work we propose a new multi-start algorithm where the starting points are determined in a Bayesian optimization framework. Specifically, the method can be understood as to construct a new function by conducting local searches of the original objective function, where the new function attains the same global optima as the original one. Bayesian optimization is then applied to find the global optima of the new local search based function.