 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards self-attention based visual navigation in the real world
Sep 19, 2022

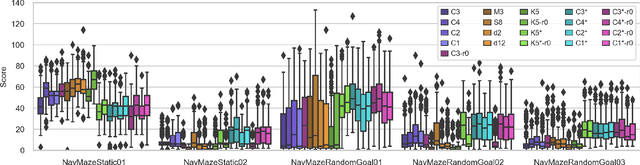
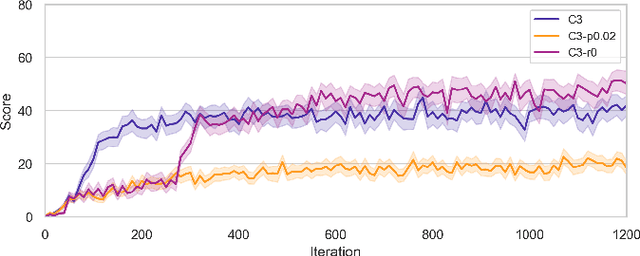
Vision guided navigation requires processing complex visual information to inform task-orientated decisions. Applications include autonomous robots, self-driving cars, and assistive vision for humans. A key element is the extraction and selection of relevant features in pixel space upon which to base action choices, for which Machine Learning techniques are well suited. However, Deep Reinforcement Learning agents trained in simulation often exhibit unsatisfactory results when deployed in the real-world due to perceptual differences known as the $\textit{reality gap}$. An approach that is yet to be explored to bridge this gap is self-attention. In this paper we (1) perform a systematic exploration of the hyperparameter space for self-attention based navigation of 3D environments and qualitatively appraise behaviour observed from different hyperparameter sets, including their ability to generalise; (2) present strategies to improve the agents' generalisation abilities and navigation behaviour; and (3) show how models trained in simulation are capable of processing real world images meaningfully in real time. To our knowledge, this is the first demonstration of a self-attention based agent successfully trained in navigating a 3D action space, using less than 4000 parameters.