 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual embeddings and self-consistency for self-supervised learning
Jun 15, 2022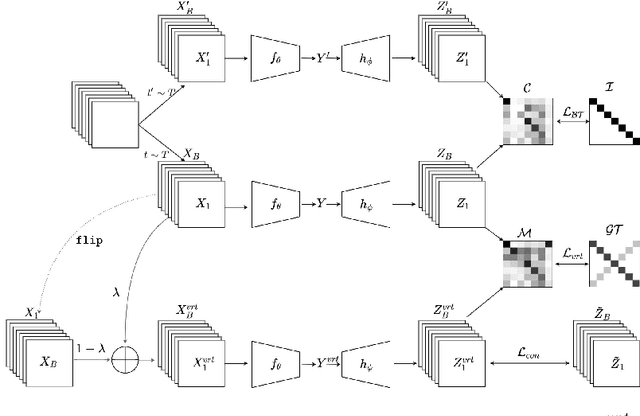



Self-supervised Learning (SSL) has recently gained much attention due to the high cost and data limitation in the training of supervised learning models. The current paradigm in the SSL is to utilize data augmentation at the input space to create different views of the same images and train a model to maximize the representations between similar images and minimize them for different ones. While this approach achieves state-of-the-art (SOTA) results in various downstream tasks, it still lakes the opportunity to investigate the latent space augmentation. This paper proposes TriMix, a novel concept for SSL that generates virtual embeddings through linear interpolation of the data, thus providing the model with novel representations. Our strategy focuses on training the model to extract the original embeddings from virtual ones, hence, better representation learning. Additionally, we propose a self-consistency term that improves the consistency between the virtual and actual embeddings. We validate TriMix on eight benchmark datasets consisting of natural and medical images with an improvement of 2.71% and 0.41% better than the second-best models for both data types. Further, our approach outperformed the current methods in semi-supervised learning, particularly in low data regimes. Besides, our pre-trained models showed better transfer to other datasets.
Peer Learning for Skin Lesion Classification
Mar 08, 2021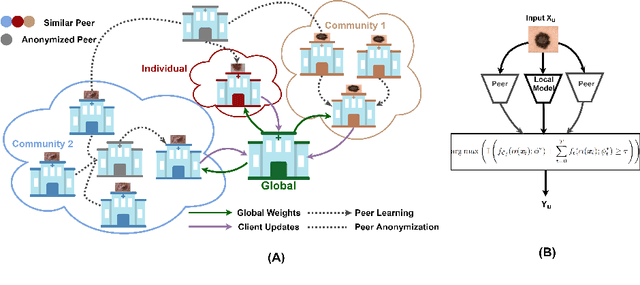
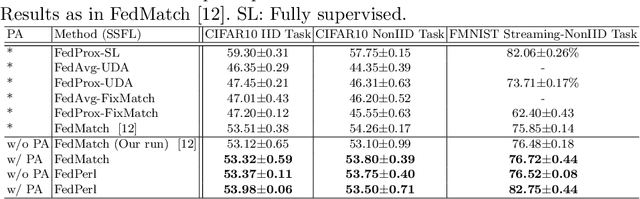
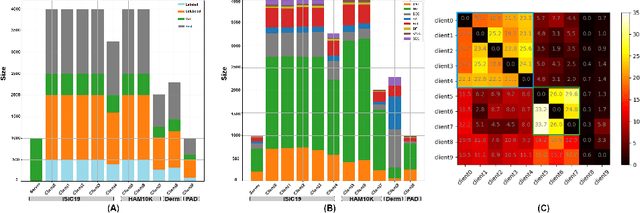
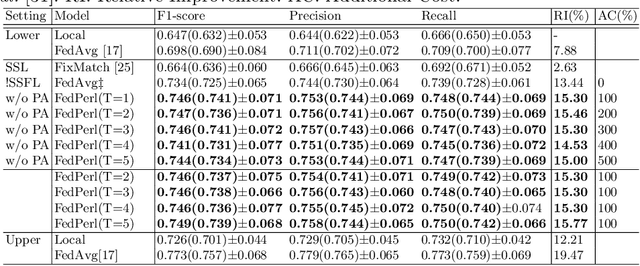
Skin cancer is one of the most deadly cancers worldwide. Yet, it can be reduced by early detection. Recent deep-learning methods have shown a dermatologist-level performance in skin cancer classification. Yet, this success demands a large amount of centralized data, which is oftentimes not available. Federated learning has been recently introduced to train machine learning models in a privacy-preserved distributed fashion demanding annotated data at the clients, which is usually expensive and not available, especially in the medical field. To this end, we propose FedPerl, a semi-supervised federated learning method that utilizes peer learning from social sciences and ensemble averaging from committee machines to build communities and encourage its members to learn from each other such that they produce more accurate pseudo labels. We also propose the peer anonymization (PA) technique as a core component of FedPerl. PA preserves privacy and reduces the communication cost while maintaining the performance without additional complexity. We validated our method on 38,000 skin lesion images collected from 4 publicly available datasets. FedPerl achieves superior performance over the baselines and state-of-the-art SSFL by 15.8%, and 1.8% respectively. Further, FedPerl shows less sensitivity to noisy clients.
ROAM: Random Layer Mixup for Semi-Supervised Learning in Medical Imaging
Mar 20, 2020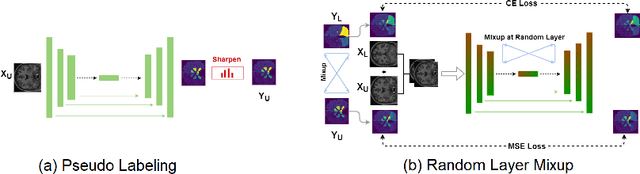


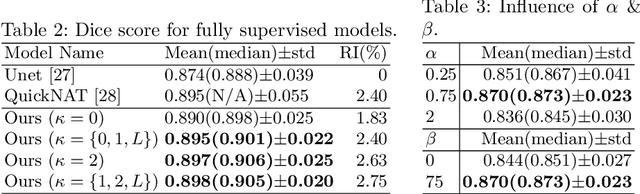
Medical image segmentation is one of the major challenges addressed by machine learning methods. Yet, deep learning methods profoundly depend on a huge amount of annotated data which is time-consuming and costly. Though semi-supervised learning methods approach this problem by leveraging an abundant amount of unlabeled data along with a small amount of labeled data in the training process. Recently, MixUp regularizer [32] has been successfully introduced to semi-supervised learning methods showing superior performance [3]. MixUp augments the model with new data points through linear interpolation of the data at the input space. In this paper, we argue that this option is limited, instead, we propose ROAM, a random layer mixup, which encourages the network to be less confident for interpolated data points at randomly selected space. Hence, avoids over-fitting and enhances the generalization ability. We validate our method on publicly available datasets on whole-brain image segmentation (MALC) achieving state-of-the-art results in fully supervised (89.8%) and semi-supervised (87.2%) settings with relative improvement up to 2.75% and 16.73%, respectively.