 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual embeddings and self-consistency for self-supervised learning
Jun 15, 2022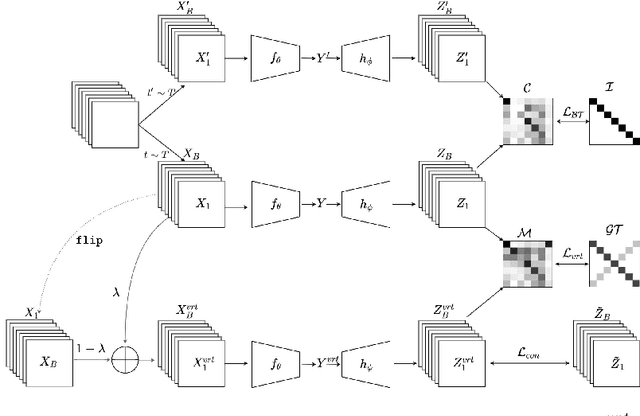



Self-supervised Learning (SSL) has recently gained much attention due to the high cost and data limitation in the training of supervised learning models. The current paradigm in the SSL is to utilize data augmentation at the input space to create different views of the same images and train a model to maximize the representations between similar images and minimize them for different ones. While this approach achieves state-of-the-art (SOTA) results in various downstream tasks, it still lakes the opportunity to investigate the latent space augmentation. This paper proposes TriMix, a novel concept for SSL that generates virtual embeddings through linear interpolation of the data, thus providing the model with novel representations. Our strategy focuses on training the model to extract the original embeddings from virtual ones, hence, better representation learning. Additionally, we propose a self-consistency term that improves the consistency between the virtual and actual embeddings. We validate TriMix on eight benchmark datasets consisting of natural and medical images with an improvement of 2.71% and 0.41% better than the second-best models for both data types. Further, our approach outperformed the current methods in semi-supervised learning, particularly in low data regimes. Besides, our pre-trained models showed better transfer to other datasets.