 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabular Data Synthesis with Differential Privacy: A Survey
Nov 04, 2024
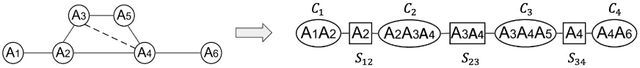

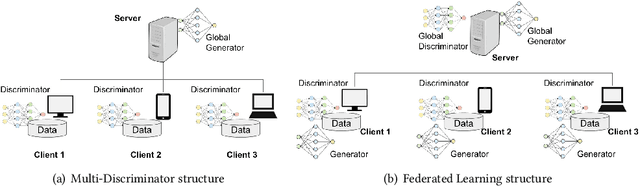
Data sharing is a prerequisite for collaborative innovation, enabling organizations to leverage diverse datasets for deeper insights. In real-world applications like FinTech and Smart Manufacturing, transactional data, often in tabular form, are generated and analyzed for insight generation. However, such datasets typically contain sensitive personal/business information, raising privacy concerns and regulatory risks. Data synthesis tackles this by generating artificial datasets that preserve the statistical characteristics of real data, removing direct links to individuals. However, attackers can still infer sensitive information using background knowledge. Differential privacy offers a solution by providing provable and quantifiable privacy protection. Consequently, differentially private data synthesis has emerged as a promising approach to privacy-aware data sharing. This paper provides a comprehensive overview of existing differentially private tabular data synthesis methods, highlighting the unique challenges of each generation model for generating tabular data under differential privacy constraints. We classify the methods into statistical and deep learning-based approaches based on their generation models, discussing them in both centralized and distributed environments. We evaluate and compare those methods within each category, highlighting their strengths and weaknesses in terms of utility, privacy, and computational complexity. Additionally, we present and discuss various evaluation methods for assessing the quality of the synthesized data, identify research gaps in the field and directions for future research.