 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRectiNet-v2: A stacked network architecture for document image dewarping
Feb 01, 2021

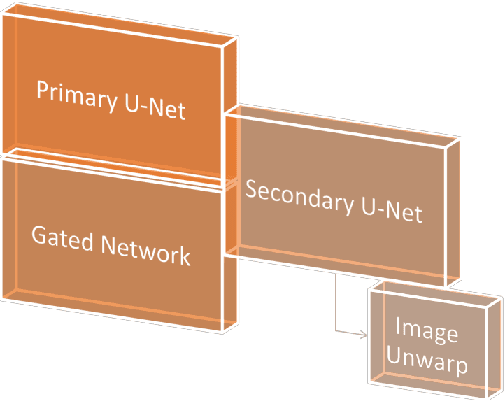
With the advent of mobile and hand-held cameras, document images have found their way into almost every domain. Dewarping of these images for the removal of perspective distortions and folds is essential so that they can be understood by document recognition algorithms. For this, we propose an end-to-end CNN architecture that can produce distortion free document images from warped documents it takes as input. We train this model on warped document images simulated synthetically to compensate for lack of enough natural data. Our method is novel in the use of a bifurcated decoder with shared weights to prevent intermingling of grid coordinates, in the use of residual networks in the U-Net skip connections to allow flow of data from different receptive fields in the model, and in the use of a gated network to help the model focus on structure and line level detail of the document image. We evaluate our method on the DocUNet dataset, a benchmark in this domain, and obtain results comparable to state-of-the-art methods.
A Gated and Bifurcated Stacked U-Net Module for Document Image Dewarping
Jul 20, 2020
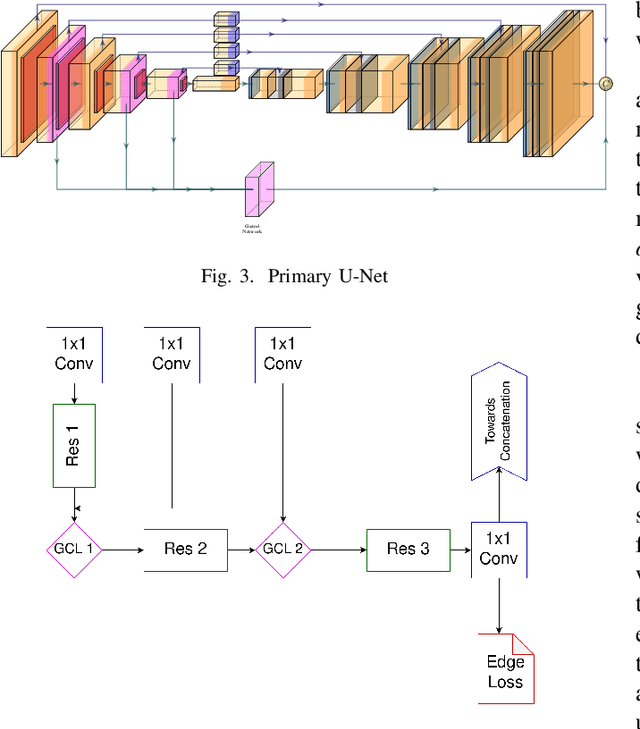
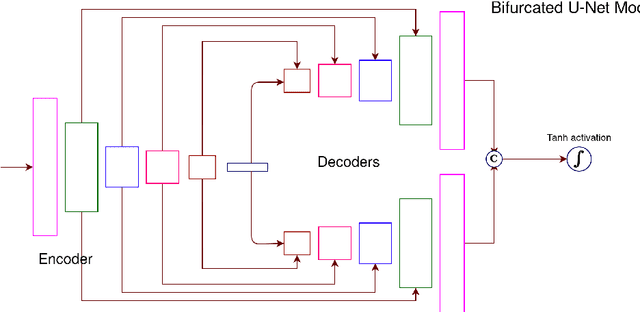
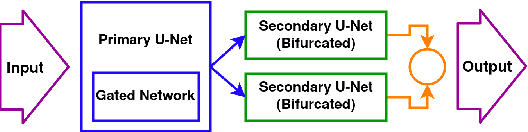
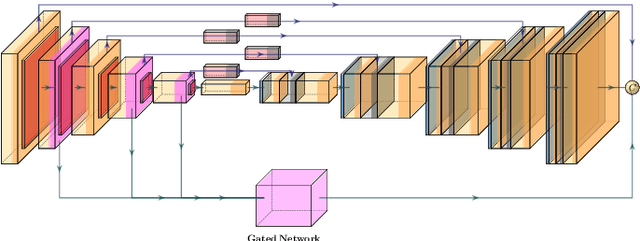
Capturing images of documents is one of the easiest and most used methods of recording them. These images however, being captured with the help of handheld devices, often lead to undesirable distortions that are hard to remove. We propose a supervised Gated and Bifurcated Stacked U-Net module to predict a dewarping grid and create a distortion free image from the input. While the network is trained on synthetically warped document images, results are calculated on the basis of real world images. The novelty in our methods exists not only in a bifurcation of the U-Net to help eliminate the intermingling of the grid coordinates, but also in the use of a gated network which adds boundary and other minute line level details to the model. The end-to-end pipeline proposed by us achieves state-of-the-art performance on the DocUNet dataset after being trained on just 8 percent of the data used in previous methods.
Multistage Curvilinear Coordinate Transform Based Document Image Dewarping using a Novel Quality Estimator
Mar 15, 2020

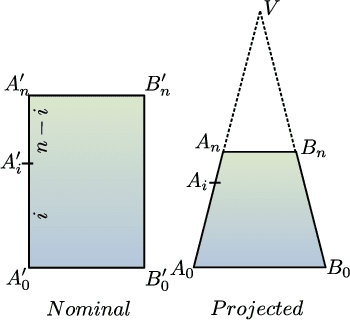

The present work demonstrates a fast and improved technique for dewarping nonlinearly warped document images. The images are first dewarped at the page-level by estimating optimum inverse projections using curvilinear homography. The quality of the process is then estimated by evaluating a set of metrics related to the characteristics of the text lines and rectilinear objects for measuring parallelism, orthogonality, etc. These are designed specifically to estimate the quality of the dewarping process without the need of any ground truth. If the quality is estimated to be unsatisfactory, the page-level dewarping process is repeated with finer approximations. This is followed by a line-level dewarping process that makes granular corrections to the warps in individual text-lines. The methodology has been tested on the CBDAR 2007 / IUPR 2011 document image dewarping dataset and is seen to yield the best OCR accuracy in the shortest amount of time, till date. The usefulness of the methodology has also been evaluated on the DocUNet 2018 dataset with some minor tweaks, and is seen to produce comparable results.