 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotic Test Tube Rearrangement Using Combined Reinforcement Learning and Motion Planning
Jan 18, 2024A combined task-level reinforcement learning and motion planning framework is proposed in this paper to address a multi-class in-rack test tube rearrangement problem. At the task level, the framework uses reinforcement learning to infer a sequence of swap actions while ignoring robotic motion details. At the motion level, the framework accepts the swapping action sequences inferred by task-level agents and plans the detailed robotic pick-and-place motion. The task and motion-level planning form a closed loop with the help of a condition set maintained for each rack slot, which allows the framework to perform replanning and effectively find solutions in the presence of low-level failures. Particularly for reinforcement learning, the framework leverages a distributed deep Q-learning structure with the Dueling Double Deep Q Network (D3QN) to acquire near-optimal policies and uses an A${}^\star$-based post-processing technique to amplify the collected training data. The D3QN and distributed learning help increase training efficiency. The post-processing helps complete unfinished action sequences and remove redundancy, thus making the training data more effective. We carry out both simulations and real-world studies to understand the performance of the proposed framework. The results verify the performance of the RL and post-processing and show that the closed-loop combination improves robustness. The framework is ready to incorporate various sensory feedback. The real-world studies also demonstrated the incorporation.
In-Rack Test Tube Pose Estimation Using RGB-D Data
Aug 21, 2023Accurate robotic manipulation of test tubes in biology and medical industries is becoming increasingly important to address workforce shortages and improve worker safety. The detection and localization of test tubes are essential for the robots to successfully manipulate test tubes. In this paper, we present a framework to detect and estimate poses for the in-rack test tubes using color and depth data. The methodology involves the utilization of a YOLO object detector to effectively classify and localize both the test tubes and the tube racks within the provided image data. Subsequently, the pose of the tube rack is estimated through point cloud registration techniques. During the process of estimating the poses of the test tubes, we capitalize on constraints derived from the arrangement of rack slots. By employing an optimization-based algorithm, we effectively evaluate and refine the pose of the test tubes. This strategic approach ensures the robustness of pose estimation, even when confronted with noisy and incomplete point cloud data.
Automatically Prepare Training Data for YOLO Using Robotic In-Hand Observation and Synthesis
Jan 04, 2023



Deep learning methods have recently exhibited impressive performance in object detection. However, such methods needed much training data to achieve high recognition accuracy, which was time-consuming and required considerable manual work like labeling images. In this paper, we automatically prepare training data using robots. Considering the low efficiency and high energy consumption in robot motion, we proposed combining robotic in-hand observation and data synthesis to enlarge the limited data set collected by the robot. We first used a robot with a depth sensor to collect images of objects held in the robot's hands and segment the object pictures. Then, we used a copy-paste method to synthesize the segmented objects with rack backgrounds. The collected and synthetic images are combined to train a deep detection neural network. We conducted experiments to compare YOLOv5x detectors trained with images collected using the proposed method and several other methods. The results showed that combined observation and synthetic images led to comparable performance to manual data preparation. They provided a good guide on optimizing data configurations and parameter settings for training detectors. The proposed method required only a single process and was a low-cost way to produce the combined data. Interested readers may find the data sets and trained models from the following GitHub repository: github.com/wrslab/tubedet
Arranging Test Tubes in Racks Using Combined Task and Motion Planning
May 07, 2020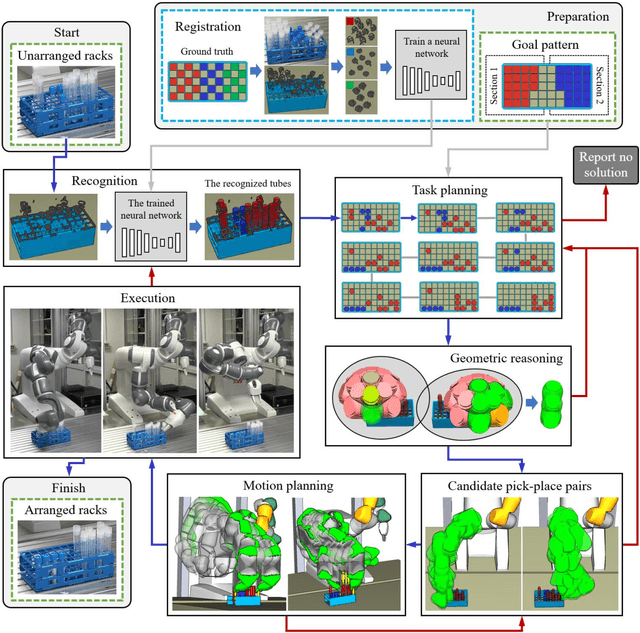
The paper develops a robotic manipulation system to treat the pressing needs for handling a large number of test tubes in clinical examination and replace or reduce human labor. It presents the technical details of the system, which separates and arranges test tubes in racks with the help of 3D vision and artificial intelligence (AI) reasoning/planning. The developed system only requires a person to put a rack with mixed and non-arranged tubes in front of a robot. The robot autonomously performs recognition, reasoning, planning, manipulation, etc., and returns a rack with separated and arranged tubes. The system is simple-to-use, and there are no requests for expert knowledge in robotics. We expect such a system to play an important role in helping managing public health and hope similar systems could be extended to other clinical manipulation like handling mixers and pipettes in the future.