 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2S-ODIS: Two-Stage Omni-Directional Image Synthesis by Geometric Distortion Correction
Sep 16, 2024Omni-directional images have been increasingly used in various applications, including virtual reality and SNS (Social Networking Services). However, their availability is comparatively limited in contrast to normal field of view (NFoV) images, since specialized cameras are required to take omni-directional images. Consequently, several methods have been proposed based on generative adversarial networks (GAN) to synthesize omni-directional images, but these approaches have shown difficulties in training of the models, due to instability and/or significant time consumption in the training. To address these problems, this paper proposes a novel omni-directional image synthesis method, 2S-ODIS (Two-Stage Omni-Directional Image Synthesis), which generated high-quality omni-directional images but drastically reduced the training time. This was realized by utilizing the VQGAN (Vector Quantized GAN) model pre-trained on a large-scale NFoV image database such as ImageNet without fine-tuning. Since this pre-trained model does not represent distortions of omni-directional images in the equi-rectangular projection (ERP), it cannot be applied directly to the omni-directional image synthesis in ERP. Therefore, two-stage structure was adopted to first create a global coarse image in ERP and then refine the image by integrating multiple local NFoV images in the higher resolution to compensate the distortions in ERP, both of which are based on the pre-trained VQGAN model. As a result, the proposed method, 2S-ODIS, achieved the reduction of the training time from 14 days in OmniDreamer to four days in higher image quality.
Multi-Scale Estimation for Omni-Directional Saliency Maps Using Learnable Equator Bias
Sep 15, 2023



Omni-directional images have been used in wide range of applications. For the applications, it would be useful to estimate saliency maps representing probability distributions of gazing points with a head-mounted display, to detect important regions in the omni-directional images. This paper proposes a novel saliency-map estimation model for the omni-directional images by extracting overlapping 2-dimensional (2D) plane images from omni-directional images at various directions and angles of view. While 2D saliency maps tend to have high probability at the center of images (center bias), the high-probability region appears at horizontal directions in omni-directional saliency maps when a head-mounted display is used (equator bias). Therefore, the 2D saliency model with a center-bias layer was fine-tuned with an omni-directional dataset by replacing the center-bias layer to an equator-bias layer conditioned on the elevation angle for the extraction of the 2D plane image. The limited availability of omni-directional images in saliency datasets can be compensated by using the well-established 2D saliency model pretrained by a large number of training images with the ground truth of 2D saliency maps. In addition, this paper proposes a multi-scale estimation method by extracting 2D images in multiple angles of view to detect objects of various sizes with variable receptive fields. The saliency maps estimated from the multiple angles of view were integrated by using pixel-wise attention weights calculated in an integration layer for weighting the optimal scale to each object. The proposed method was evaluated using a publicly available dataset with evaluation metrics for omni-directional saliency maps. It was confirmed that the accuracy of the saliency maps was improved by the proposed method.
Increasing diversity of omni-directional images generated from single image using cGAN based on MLPMixer
Sep 15, 2023



This paper proposes a novel approach to generating omni-directional images from a single snapshot picture. The previous method has relied on the generative adversarial networks based on convolutional neural networks (CNN). Although this method has successfully generated omni-directional images, CNN has two drawbacks for this task. First, since a convolutional layer only processes a local area, it is difficult to propagate the information of an input snapshot picture embedded in the center of the omni-directional image to the edges of the image. Thus, the omni-directional images created by the CNN-based generator tend to have less diversity at the edges of the generated images, creating similar scene images. Second, the CNN-based model requires large video memory in graphics processing units due to the nature of the deep structure in CNN since shallow-layer networks only receives signals from a limited range of the receptive field. To solve these problems, MLPMixer-based method was proposed in this paper. The MLPMixer has been proposed as an alternative to the self-attention in the transformer, which captures long-range dependencies and contextual information. This enables to propagate information efficiently in the omni-directional image generation task. As a result, competitive performance has been achieved with reduced memory consumption and computational cost, in addition to increasing diversity of the generated omni-directional images.
Improving Translation Invariance in Convolutional Neural Networks with Peripheral Prediction Padding
Jul 15, 2023



Zero padding is often used in convolutional neural networks to prevent the feature map size from decreasing with each layer. However, recent studies have shown that zero padding promotes encoding of absolute positional information, which may adversely affect the performance of some tasks. In this work, a novel padding method called Peripheral Prediction Padding (PP-Pad) method is proposed, which enables end-to-end training of padding values suitable for each task instead of zero padding. Moreover, novel metrics to quantitatively evaluate the translation invariance of the model are presented. By evaluating with these metrics, it was confirmed that the proposed method achieved higher accuracy and translation invariance than the previous methods in a semantic segmentation task.
Improving NeRF with Height Data for Utilization of GIS Data
Jul 15, 2023Neural Radiance Fields (NeRF) has been applied to various tasks related to representations of 3D scenes. Most studies based on NeRF have focused on a small object, while a few studies have tried to reconstruct large-scale scenes although these methods tend to require large computational cost. For the application of NeRF to large-scale scenes, a method based on NeRF is proposed in this paper to effectively use height data which can be obtained from GIS (Geographic Information System). For this purpose, the scene space was divided into multiple objects and a background using the height data to represent them with separate neural networks. In addition, an adaptive sampling method is also proposed by using the height data. As a result, the accuracy of image rendering was improved with faster training speed.
Omni-Directional Image Generation from Single Snapshot Image
Oct 12, 2020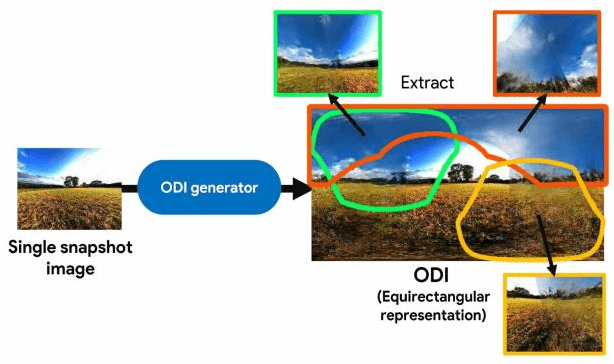
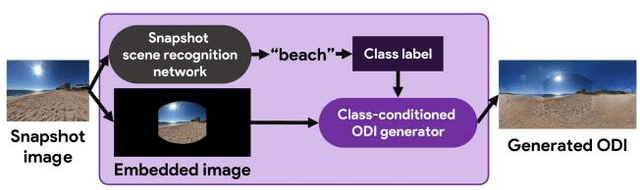
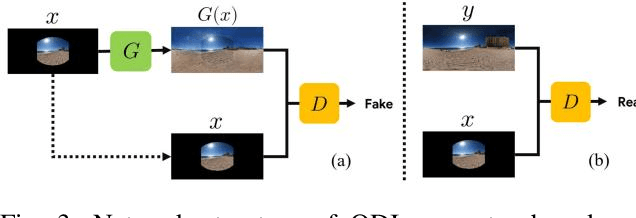
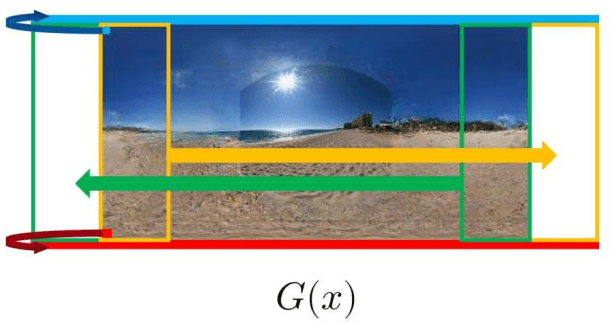
An omni-directional image (ODI) is the image that has a field of view covering the entire sphere around the camera. The ODIs have begun to be used in a wide range of fields such as virtual reality (VR), robotics, and social network services. Although the contents using ODI have increased, the available images and videos are still limited, compared with widespread snapshot images. A large number of ODIs are desired not only for the VR contents, but also for training deep learning models for ODI. For these purposes, a novel computer vision task to generate ODI from a single snapshot image is proposed in this paper. To tackle this problem, the conditional generative adversarial network was applied in combination with class-conditioned convolution layers. With this novel task, VR images and videos will be easily created even with a smartphone camera.
LPM: Learnable Pooling Module for Efficient Full-Face Gaze Estimation
Mar 21, 2019

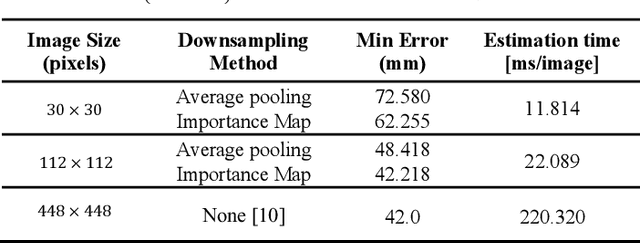
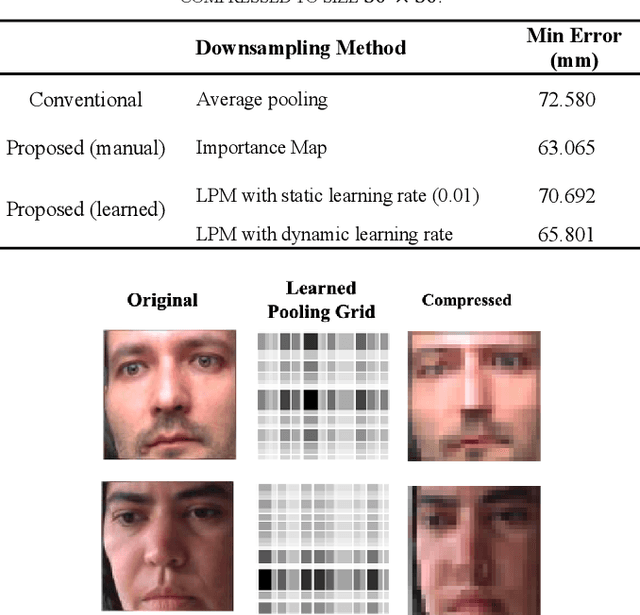
Gaze tracking is an important technology in many domains. Techniques such as Convolutional Neural Networks (CNN) has allowed the invention of gaze tracking method that relies only on commodity hardware such as the camera on a personal computer. It has been shown that the full-face region for gaze estimation can provide better performance than from an eye image alone. However, a problem with using the full-face image is the heavy computation due to the larger image size. This study tackles this problem through compression of the input full-face image by removing redundant information using a novel learnable pooling module. The module can be trained end-to-end by backpropagation to learn the size of the grid in the pooling filter. The learnable pooling module keeps the resolution of valuable regions high and vice versa. This proposed method preserved the gaze estimation accuracy at a certain level when the image was reduced to a smaller size.
Influence of Image Classification Accuracy on Saliency Map Estimation
Jul 27, 2018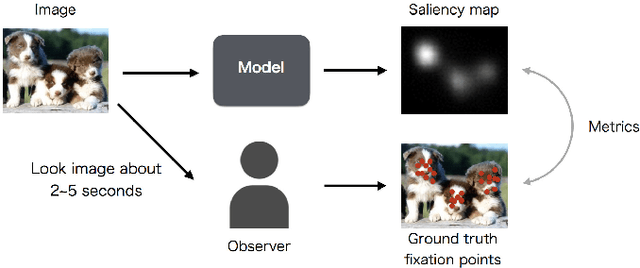
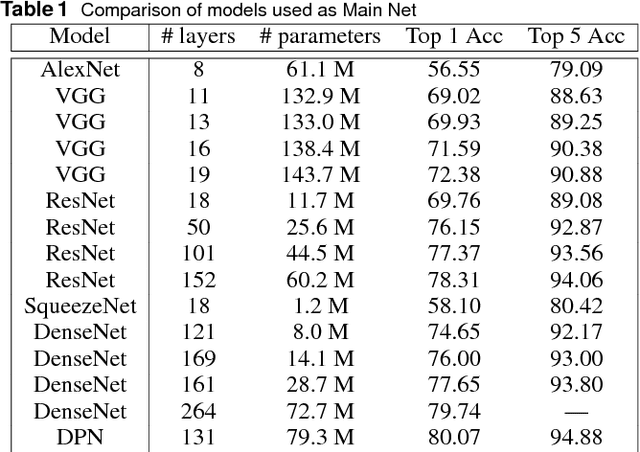
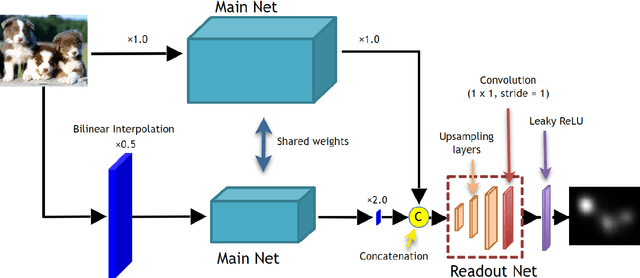
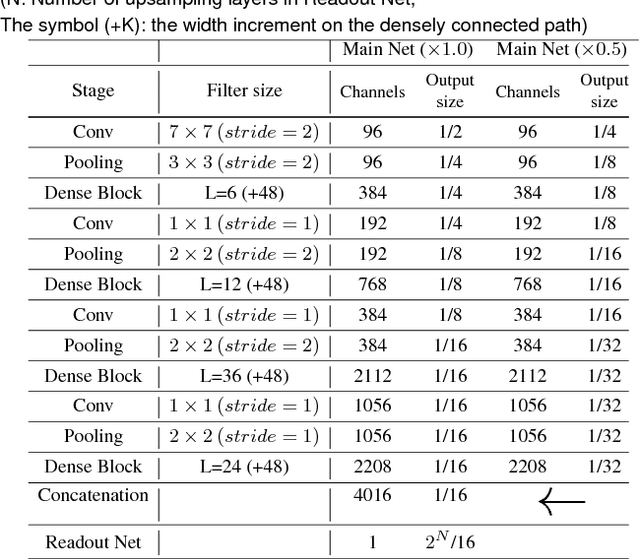
Saliency map estimation in computer vision aims to estimate the locations where people gaze in images. Since people tend to look at objects in images, the parameters of the model pretrained on ImageNet for image classification are useful for the saliency map estimation. However, there is no research on the relationship between the image classification accuracy and the performance of the saliency map estimation. In this paper, it is shown that there is a strong correlation between image classification accuracy and saliency map estimation accuracy. We also investigated the effective architecture based on multi scale images and the upsampling layers to refine the saliency-map resolution. Our model achieved the state-of-the-art accuracy on the PASCAL-S, OSIE, and MIT1003 datasets. In the MIT Saliency Benchmark, our model achieved the best performance in some metrics and competitive results in the other metrics.
Saliency Map Estimation for Omni-Directional Image Considering Prior Distributions
Jul 17, 2018
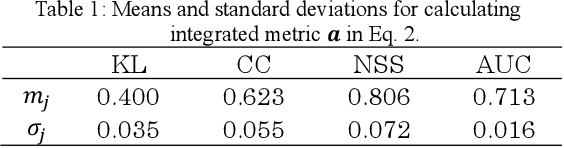

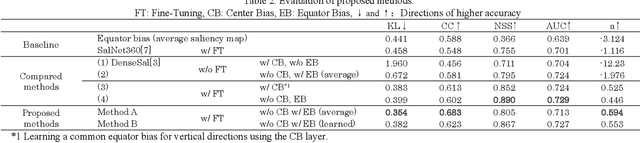
In recent years, the deep learning techniques have been applied to the estimation of saliency maps, which represent probability density functions of fixations when people look at the images. Although the methods of saliency-map estimation have been actively studied for 2-dimensional planer images, the methods for omni-directional images to be utilized in virtual environments had not been studied, until a competition of saliency-map estimation for the omni-directional images was held in ICME2017. In this paper, novel methods for estimating saliency maps for the omni-directional images are proposed considering the properties of prior distributions for fixations in the planar images and the omni-directional images.