 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLPM: Learnable Pooling Module for Efficient Full-Face Gaze Estimation
Mar 21, 2019

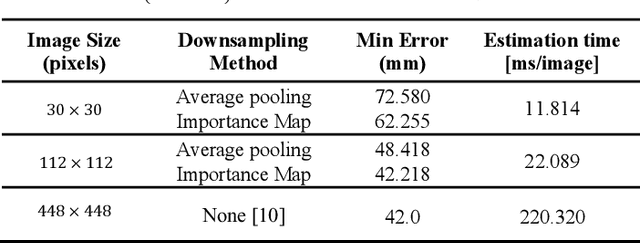
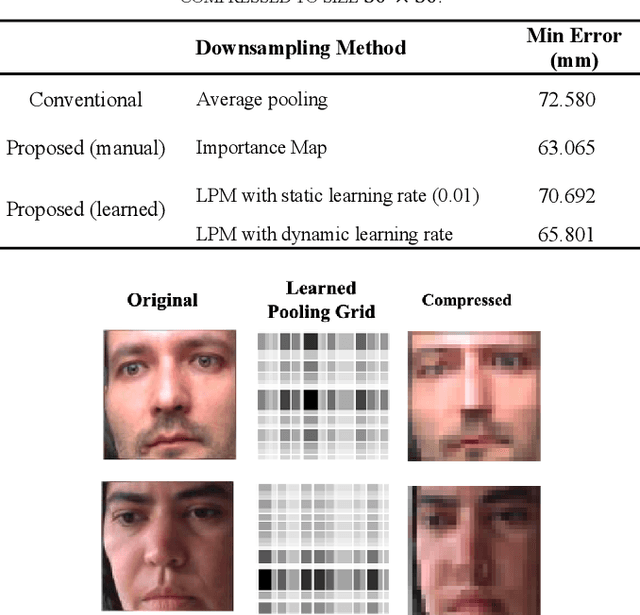
Gaze tracking is an important technology in many domains. Techniques such as Convolutional Neural Networks (CNN) has allowed the invention of gaze tracking method that relies only on commodity hardware such as the camera on a personal computer. It has been shown that the full-face region for gaze estimation can provide better performance than from an eye image alone. However, a problem with using the full-face image is the heavy computation due to the larger image size. This study tackles this problem through compression of the input full-face image by removing redundant information using a novel learnable pooling module. The module can be trained end-to-end by backpropagation to learn the size of the grid in the pooling filter. The learnable pooling module keeps the resolution of valuable regions high and vice versa. This proposed method preserved the gaze estimation accuracy at a certain level when the image was reduced to a smaller size.