 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustable and Automated Machine Learning Running with Blockchain and Its Applications
Aug 14, 2019



Machine learning algorithms learn from data and use data from databases that are mutable; therefore, the data and the results of machine learning cannot be fully trusted. Also, the machine learning process is often difficult to automate. A unified analytical framework for trustable machine learning has been presented in the literature. It proposed building a trustable machine learning system by using blockchain technology, which can store data in a permanent and immutable way. In addition, smart contracts on blockchain are used to automate the machine learning process. In the proposed framework, a core machine learning algorithm can have three implementations: server layer implementation, streaming layer implementation, and smart contract implementation. However, there are still open questions. First, the streaming layer usually deploys on edge devices and therefore has limited memory and computing power. How can we run machine learning on the streaming layer? Second, most data that are stored on blockchain are financial transactions, for which fraud detection is often needed. However, in some applications, training data are hard to obtain. Can we build good machine learning models to do fraud detection with limited training data? These questions motivated this paper; which makes two contributions. First, it proposes training a machine learning model on the server layer and saving the model with a special binary data format. Then, the streaming layer can take this blob of binary data as input and score incoming data online. The blob of binary data is very compact and can be deployed on edge devices. Second, the paper presents a new method of synthetic data generation that can enrich the training data set. Experiments show that this synthetic data generation is very effective in applications such as fraud detection in financial data.
High-Performance Support Vector Machines and Its Applications
May 01, 2019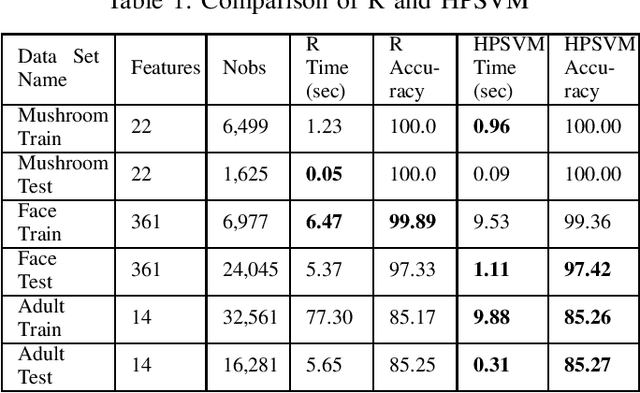
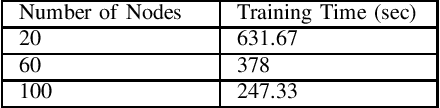

The support vector machines (SVM) algorithm is a popular classification technique in data mining and machine learning. In this paper, we propose a distributed SVM algorithm and demonstrate its use in a number of applications. The algorithm is named high-performance support vector machines (HPSVM). The major contribution of HPSVM is two-fold. First, HPSVM provides a new way to distribute computations to the machines in the cloud without shuffling the data. Second, HPSVM minimizes the inter-machine communications in order to maximize the performance. We apply HPSVM to some real-world classification problems and compare it with the state-of-the-art SVM technique implemented in R on several public data sets. HPSVM achieves similar or better results.