 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Performance Support Vector Machines and Its Applications
Paper and Code
May 01, 2019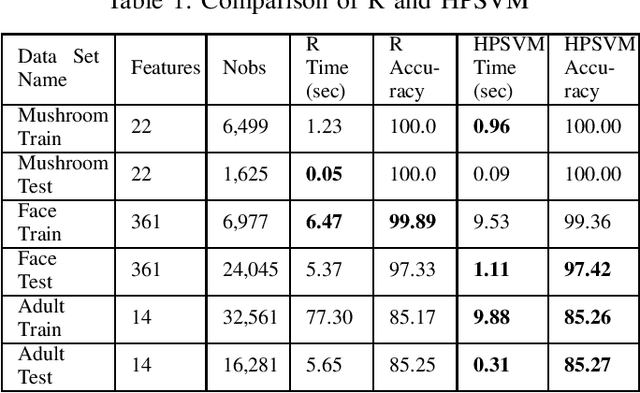
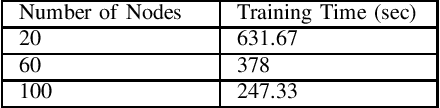

The support vector machines (SVM) algorithm is a popular classification technique in data mining and machine learning. In this paper, we propose a distributed SVM algorithm and demonstrate its use in a number of applications. The algorithm is named high-performance support vector machines (HPSVM). The major contribution of HPSVM is two-fold. First, HPSVM provides a new way to distribute computations to the machines in the cloud without shuffling the data. Second, HPSVM minimizes the inter-machine communications in order to maximize the performance. We apply HPSVM to some real-world classification problems and compare it with the state-of-the-art SVM technique implemented in R on several public data sets. HPSVM achieves similar or better results.