 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScript-to-Slide Grounding: Grounding Script Sentences to Slide Objects for Automatic Instructional Video Generation
Mar 14, 2026While slide-based videos augmented with visual effects are widely utilized in education and research presentations, the video editing process -- particularly applying visual effects to ground spoken content to slide objects -- remains highly labor-intensive. This study aims to develop a system that automatically generates such instructional videos from slides and corresponding scripts. As a foundational step, this paper proposes and formulates Script-to-Slide Grounding (S2SG), defined as the task of grounding script sentences to their corresponding slide objects. Furthermore, as an initial step, we propose ``Text-S2SG,'' a method that utilizes a large language model (LLM) to perform this grounding task for text objects. Our experiments demonstrate that the proposed method achieves high performance (F1-score: 0.924). The contribution of this work is the formalization of a previously implicit slide-based video editing process into a computable task, thereby paving the way for its automation.
Coarse-Grained Sense Inventories Based on Semantic Matching between English Dictionaries
Sep 10, 2024WordNet is one of the largest handcrafted concept dictionaries visualizing word connections through semantic relationships. It is widely used as a word sense inventory in natural language processing tasks. However, WordNet's fine-grained senses have been criticized for limiting its usability. In this paper, we semantically match sense definitions from Cambridge dictionaries and WordNet and develop new coarse-grained sense inventories. We verify the effectiveness of our inventories by comparing their semantic coherences with that of Coarse Sense Inventory. The advantages of the proposed inventories include their low dependency on large-scale resources, better aggregation of closely related senses, CEFR-level assignments, and ease of expansion and improvement.
Lyricist-Singer Entropy Affects Lyric-Lyricist Classification Performance
Oct 17, 2023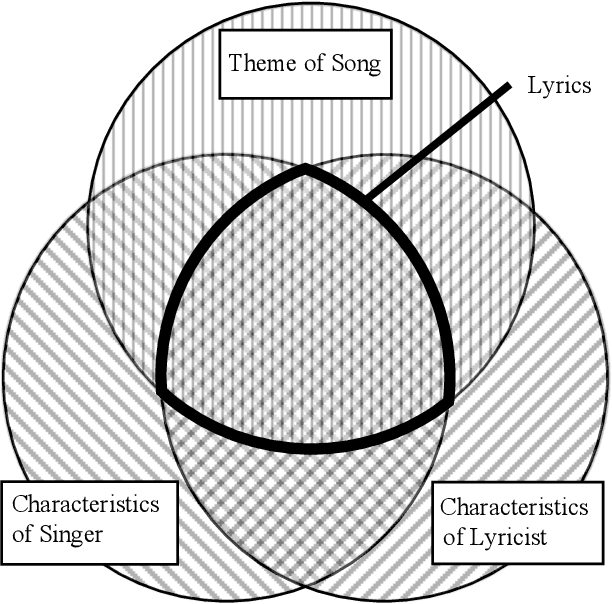
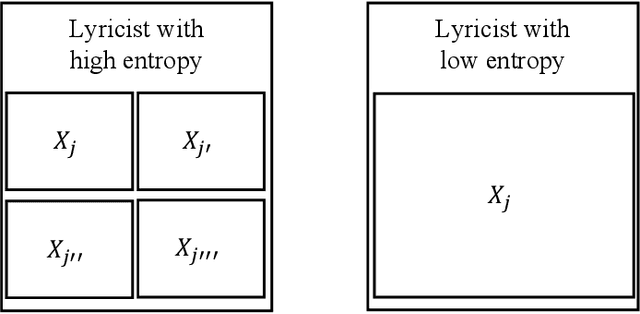
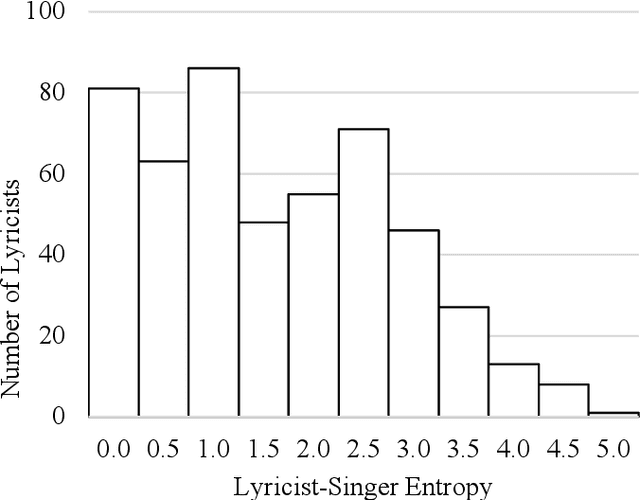
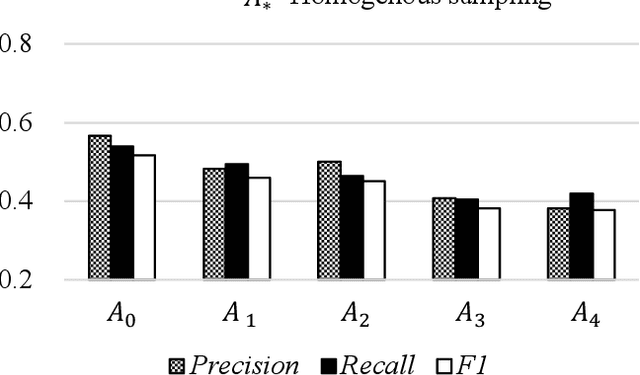
Although lyrics represent an essential component of music, few music information processing studies have been conducted on the characteristics of lyricists. Because these characteristics may be valuable for musical applications, such as recommendations, they warrant further study. We considered a potential method that extracts features representing the characteristics of lyricists from lyrics. Because these features must be identified prior to extraction, we focused on lyricists with easily identifiable features. We believe that it is desirable for singers to perform unique songs that share certain characteristics specific to the singer. Accordingly, we hypothesized that lyricists account for the unique characteristics of the singers they write lyrics for. In other words, lyric-lyricist classification performance or the ease of capturing the features of a lyricist from the lyrics may depend on the variety of singers. In this study, we observed a relationship between lyricist-singer entropy or the variety of singers associated with a single lyricist and lyric-lyricist classification performance. As an example, the lyricist-singer entropy is minimal when the lyricist writes lyrics for only one singer. In our experiments, we grouped lyricists among five groups in terms of lyricist-singer entropy and assessed the lyric-lyricist classification performance within each group. Consequently, the best F1 score was obtained for the group with the lowest lyricist-singer entropy. Our results suggest that further analyses of the features contributing to lyric-lyricist classification performance on the lowest lyricist-singer entropy group may improve the feature extraction task for lyricists.
Improving Multi-class Classifier Using Likelihood Ratio Estimation with Regularization
Oct 28, 2022The universal-set naive Bayes classifier (UNB)~\cite{Komiya:13}, defined using likelihood ratios (LRs), was proposed to address imbalanced classification problems. However, the LR estimator used in the UNB overestimates LRs for low-frequency data, degrading the classification performance. Our previous study~\cite{Kikuchi:19} proposed an effective LR estimator even for low-frequency data. This estimator uses regularization to suppress the overestimation, but we did not consider imbalanced data. In this paper, we integrated the estimator with the UNB. Our experiments with imbalanced data showed that our proposed classifier effectively adjusts the classification scores according to the class balance using regularization parameters and improves the classification performance.
Conservative Likelihood Ratio Estimator for Infrequent Data Slightly above a Frequency Threshold
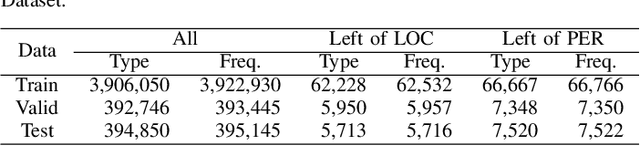
Oct 28, 2022A naive likelihood ratio (LR) estimation using the observed frequencies of events can overestimate LRs for infrequent data. One approach to avoid this problem is to use a frequency threshold and set the estimates to zero for frequencies below the threshold. This approach eliminates the computation of some estimates, thereby making practical tasks using LRs more efficient. However, it still overestimates LRs for low frequencies near the threshold. This study proposes a conservative estimator for low frequencies, slightly above the threshold. Our experiment used LRs to predict the occurrence contexts of named entities from a corpus. The experimental results demonstrate that our estimator improves the prediction accuracy while maintaining efficiency in the context prediction task.
Developing a Component Comment Extractor from Product Reviews on E-Commerce Sites
Jul 13, 2022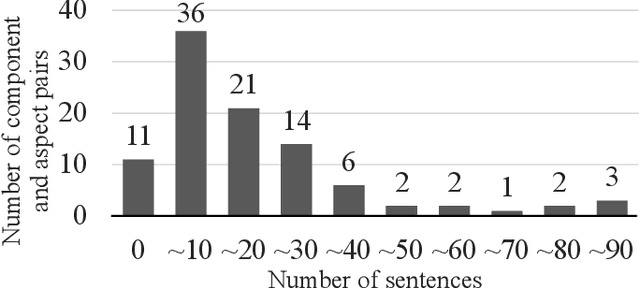
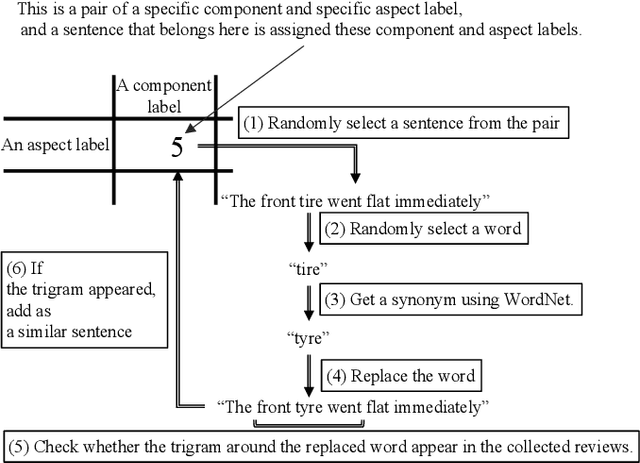
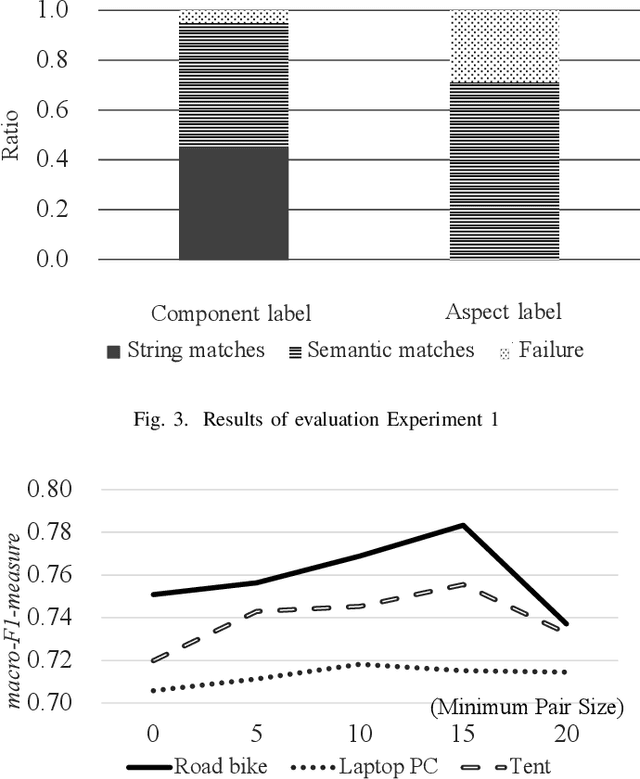
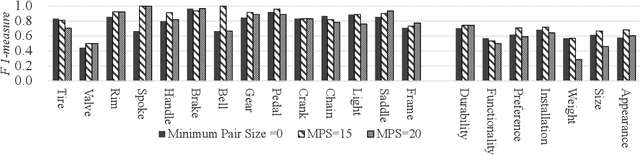
Consumers often read product reviews to inform their buying decision, as some consumers want to know a specific component of a product. However, because typical sentences on product reviews contain various details, users must identify sentences about components they want to know amongst the many reviews. Therefore, we aimed to develop a system that identifies and collects component and aspect information of products in sentences. Our BERT-based classifiers assign labels referring to components and aspects to sentences in reviews and extract sentences with comments on specific components and aspects. We determined proper labels based for the words identified through pattern matching from product reviews to create the training data. Because we could not use the words as labels, we carefully created labels covering the meanings of the words. However, the training data was imbalanced on component and aspect pairs. We introduced a data augmentation method using WordNet to reduce the bias. Our evaluation demonstrates that the system can determine labels for road bikes using pattern matching, covering more than 88\% of the indicators of components and aspects on e-commerce sites. Moreover, our data augmentation method can improve the-F1-measure on insufficient data from 0.66 to 0.76.
* The 14th International Conference on E-Service and Knowledge Management (ESKM 2022), 6 pages, 6 figures, 5 tables
Product Information Browsing Support System Using Analytic Hierarchy Process
Dec 17, 2021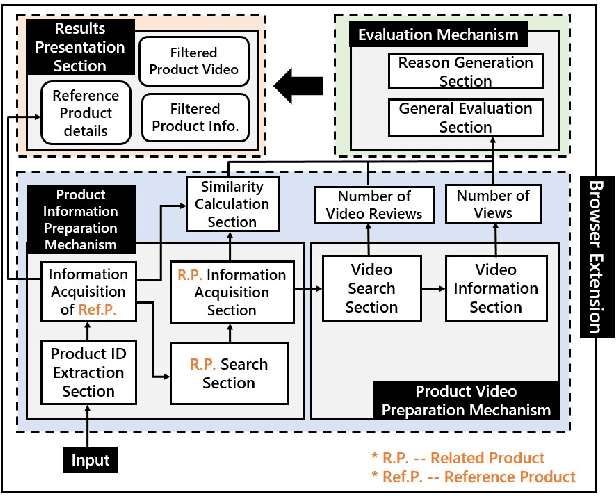
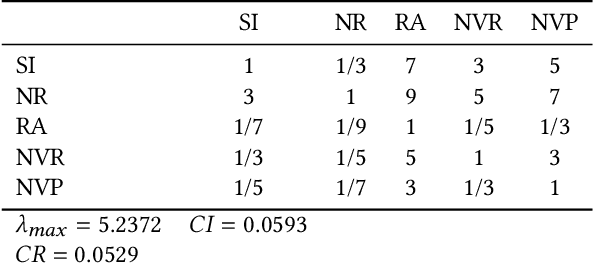

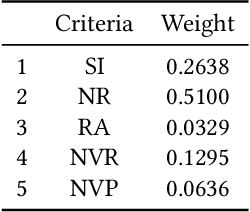
Large-scale e-commerce sites can collect and analyze a large number of user preferences and behaviors, and thus can recommend highly trusted products to users. However, it is very difficult for individuals or non-corporate groups to obtain large-scale user data. Therefore, we consider whether knowledge of the decision-making domain can be used to obtain user preferences and combine it with content-based filtering to design an information retrieval system. This study describes the process of building a product information browsing support system with high satisfaction based on product similarity and multiple other perspectives about products on the Internet. We present the architecture of the proposed system and explain the working principle of its constituent modules. Finally, we demonstrate the effectiveness of the proposed system through an evaluation experiment and a questionnaire.
Feature Selective Likelihood Ratio Estimator for Low- and Zero-frequency N-grams
Nov 05, 2021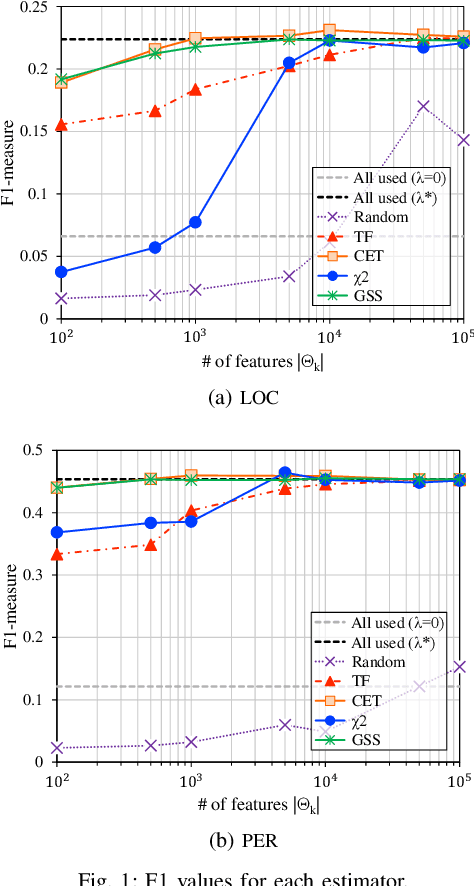
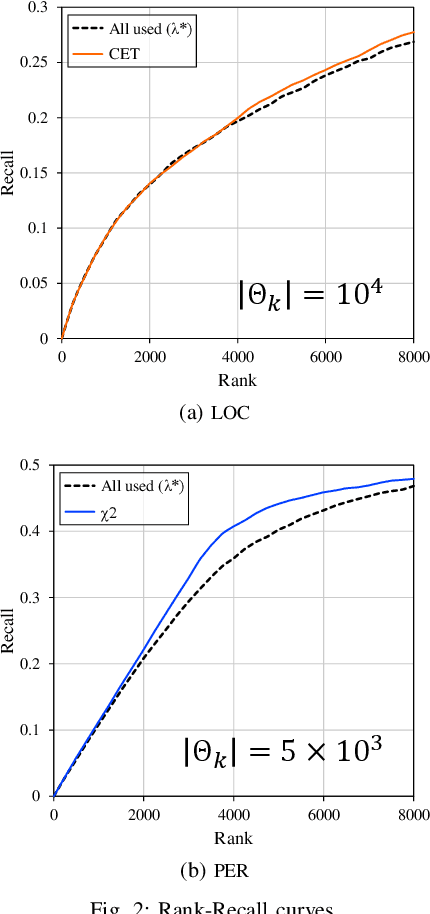
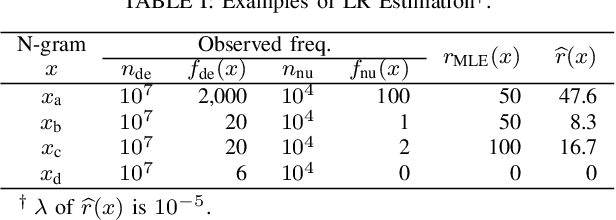
In natural language processing (NLP), the likelihood ratios (LRs) of N-grams are often estimated from the frequency information. However, a corpus contains only a fraction of the possible N-grams, and most of them occur infrequently. Hence, we desire an LR estimator for low- and zero-frequency N-grams. One way to achieve this is to decompose the N-grams into discrete values, such as letters and words, and take the product of the LRs for the values. However, because this method deals with a large number of discrete values, the running time and memory usage for estimation are problematic. Moreover, use of unnecessary discrete values causes deterioration of the estimation accuracy. Therefore, this paper proposes combining the aforementioned method with the feature selection method used in document classification, and shows that our estimator provides effective and efficient estimation results for low- and zero-frequency N-grams.
Development of an Extractive Title Generation System Using Titles of Papers of Top Conferences for Intermediate English Students
Oct 08, 2021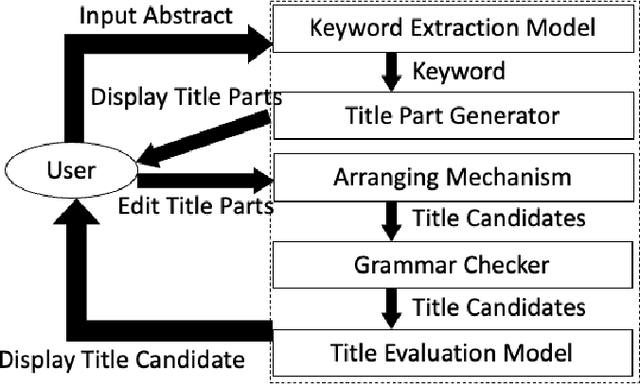
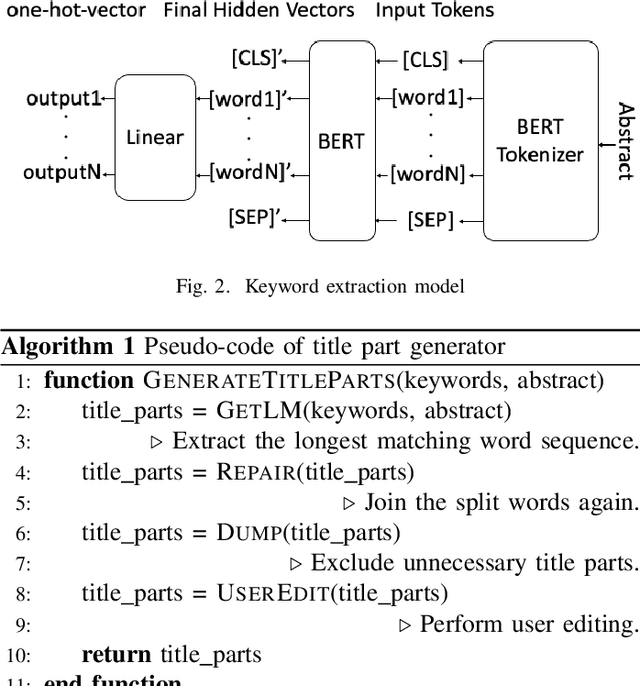
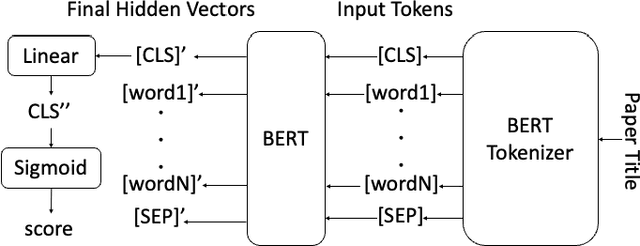
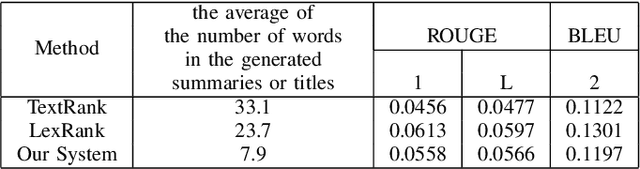
The formulation of good academic paper titles in English is challenging for intermediate English authors (particularly students). This is because such authors are not aware of the type of titles that are generally in use. We aim to realize a support system for formulating more effective English titles for intermediate English and beginner authors. This study develops an extractive title generation system that formulates titles from keywords extracted from an abstract. Moreover, we realize a title evaluation model that can evaluate the appropriateness of paper titles. We train the model with titles of top-conference papers by using BERT. This paper describes the training data, implementation, and experimental results. The results show that our evaluation model can identify top-conference titles more effectively than intermediate English and beginner students.
* 6 pages, 3 figures, 4 tables, 2 algorithms