 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhotometric Redshift Estimation Using Scaled Ensemble Learning
Jan 12, 2026The development of the state-of-the-art telescopic systems capable of performing expansive sky surveys such as the Sloan Digital Sky Survey, Euclid, and the Rubin Observatory's Legacy Survey of Space and Time (LSST) has significantly advanced efforts to refine cosmological models. These advances offer deeper insight into persistent challenges in astrophysics and our understanding of the Universe's evolution. A critical component of this progress is the reliable estimation of photometric redshifts (Pz). To improve the precision and efficiency of such estimations, the application of machine learning (ML) techniques to large-scale astronomical datasets has become essential. This study presents a new ensemble-based ML framework aimed at predicting Pz for faint galaxies and higher redshift ranges, relying solely on optical (grizy) photometric data. The proposed architecture integrates several learning algorithms, including gradient boosting machine, extreme gradient boosting, k-nearest neighbors, and artificial neural networks, within a scaled ensemble structure. By using bagged input data, the ensemble approach delivers improved predictive performance compared to stand-alone models. The framework demonstrates consistent accuracy in estimating redshifts, maintaining strong performance up to z ~ 4. The model is validated using publicly available data from the Hyper Suprime-Cam Strategic Survey Program by the Subaru Telescope. Our results show marked improvements in the precision and reliability of Pz estimation. Furthermore, this approach closely adheres to-and in certain instances exceeds-the benchmarks specified in the LSST Science Requirements Document. Evaluation metrics include catastrophic outlier, bias, and rms.
* 10 pages, 2 figures, 3 tables
Towards Wide Learning: Experiments in Healthcare
Dec 21, 2016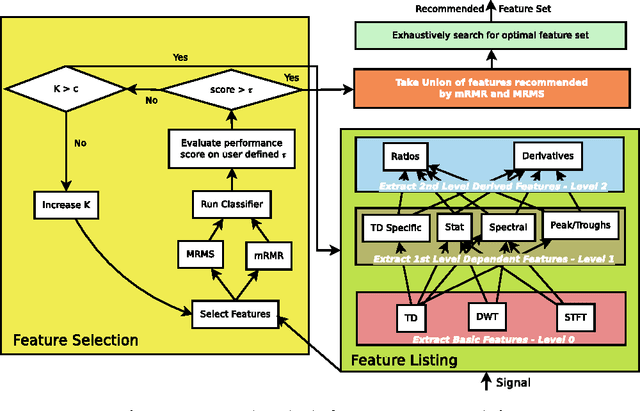
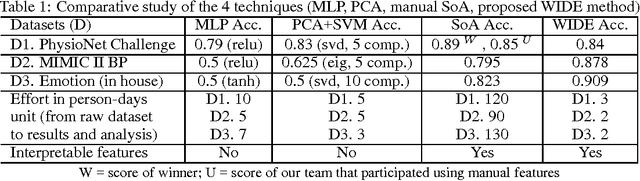
In this paper, a Wide Learning architecture is proposed that attempts to automate the feature engineering portion of the machine learning (ML) pipeline. Feature engineering is widely considered as the most time consuming and expert knowledge demanding portion of any ML task. The proposed feature recommendation approach is tested on 3 healthcare datasets: a) PhysioNet Challenge 2016 dataset of phonocardiogram (PCG) signals, b) MIMIC II blood pressure classification dataset of photoplethysmogram (PPG) signals and c) an emotion classification dataset of PPG signals. While the proposed method beats the state of the art techniques for 2nd and 3rd dataset, it reaches 94.38% of the accuracy level of the winner of PhysioNet Challenge 2016. In all cases, the effort to reach a satisfactory performance was drastically less (a few days) than manual feature engineering.