 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble Machine Learning at Scale to Predict Causal Impact of Customer Actions
Sep 03, 2024Causal Impact (CI) of customer actions are broadly used across the industry to inform both short- and long-term investment decisions of various types. In this paper, we apply the double machine learning (DML) methodology to estimate the CI values across 100s of customer actions of business interest and 100s of millions of customers. We operationalize DML through a causal ML library based on Spark with a flexible, JSON-driven model configuration approach to estimate CI at scale (i.e., across hundred of actions and millions of customers). We outline the DML methodology and implementation, and associated benefits over the traditional potential outcomes based CI model. We show population-level as well as customer-level CI values along with confidence intervals. The validation metrics show a 2.2% gain over the baseline methods and a 2.5X gain in the computational time. Our contribution is to advance the scalable application of CI, while also providing an interface that allows faster experimentation, cross-platform support, ability to onboard new use cases, and improves accessibility of underlying code for partner teams.
* 16 pages, 11 figures. Accepted at the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD) 2023, Turin, Italy
Valuing an Engagement Surface using a Large Scale Dynamic Causal Model
Aug 21, 2024With recent rapid growth in online shopping, AI-powered Engagement Surfaces (ES) have become ubiquitous across retail services. These engagement surfaces perform an increasing range of functions, including recommending new products for purchase, reminding customers of their orders and providing delivery notifications. Understanding the causal effect of engagement surfaces on value driven for customers and businesses remains an open scientific question. In this paper, we develop a dynamic causal model at scale to disentangle value attributable to an ES, and to assess its effectiveness. We demonstrate the application of this model to inform business decision-making by understanding returns on investment in the ES, and identifying product lines and features where the ES adds the most value.
Identifying and Overcoming Transformation Bias in Forecasting Models
Aug 24, 2022

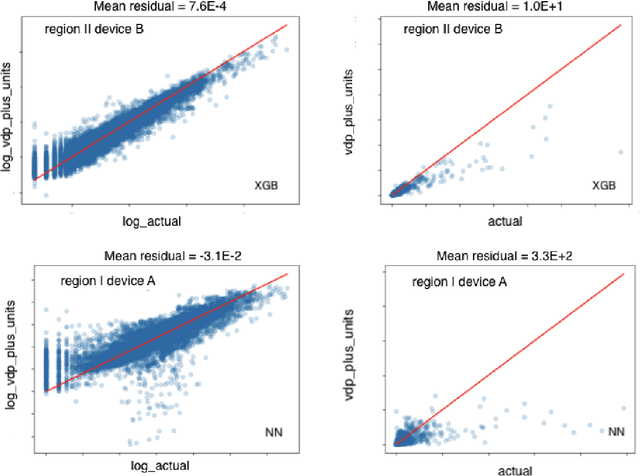
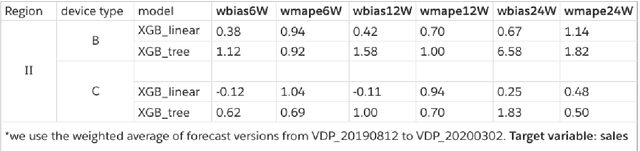
Log and square root transformations of target variable are routinely used in forecasting models to predict future sales. These transformations often lead to better performing models. However, they also introduce a systematic negative bias (under-forecasting). In this paper, we demonstrate the existence of this bias, dive deep into its root cause and introduce two methods to correct for the bias. We conclude that the proposed bias correction methods improve model performance (by up to 50%) and make a case for incorporating bias correction in modeling workflow. We also experiment with `Tweedie' family of cost functions which circumvents the transformation bias issue by modeling directly on sales. We conclude that Tweedie regression gives the best performance so far when modeling on sales making it a strong alternative to working with a transformed target variable.