 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRanking Counterfactual Explanations
Mar 20, 2025AI-driven outcomes can be challenging for end-users to understand. Explanations can address two key questions: "Why this outcome?" (factual) and "Why not another?" (counterfactual). While substantial efforts have been made to formalize factual explanations, a precise and comprehensive study of counterfactual explanations is still lacking. This paper proposes a formal definition of counterfactual explanations, proving some properties they satisfy, and examining the relationship with factual explanations. Given that multiple counterfactual explanations generally exist for a specific case, we also introduce a rigorous method to rank these counterfactual explanations, going beyond a simple minimality condition, and to identify the optimal ones. Our experiments with 12 real-world datasets highlight that, in most cases, a single optimal counterfactual explanation emerges. We also demonstrate, via three metrics, that the selected optimal explanation exhibits higher representativeness and can explain a broader range of elements than a random minimal counterfactual. This result highlights the effectiveness of our approach in identifying more robust and comprehensive counterfactual explanations.
Analogical Relevance Index
Jan 08, 2023Focusing on the most significant features of a dataset is useful both in machine learning (ML) and data mining. In ML, it can lead to a higher accuracy, a faster learning process, and ultimately a simpler and more understandable model. In data mining, identifying significant features is essential not only for gaining a better understanding of the data but also for visualization. In this paper, we demonstrate a new way of identifying significant features inspired by analogical proportions. Such a proportion is of the form of "a is to b as c is to d", comparing two pairs of items (a, b) and (c, d) in terms of similarities and dissimilarities. In a classification context, if the similarities/dissimilarities between a and b correlate with the fact that a and b have different labels, this knowledge can be transferred to c and d, inferring that c and d also have different labels. From a feature selection perspective, observing a huge number of such pairs (a, b) where a and b have different labels provides a hint about the importance of the features where a and b differ. Following this idea, we introduce the Analogical Relevance Index (ARI), a new statistical test of the significance of a given feature with respect to the label. ARI is a filter-based method. Filter-based methods are ML-agnostic but generally unable to handle feature redundancy. However, ARI can detect feature redundancy. Our experiments show that ARI is effective and outperforms well-known methods on a variety of artificial and some real datasets.
Distortion Robust Image Classification using Deep Convolutional Neural Network with Discrete Cosine Transform
Nov 19, 2018
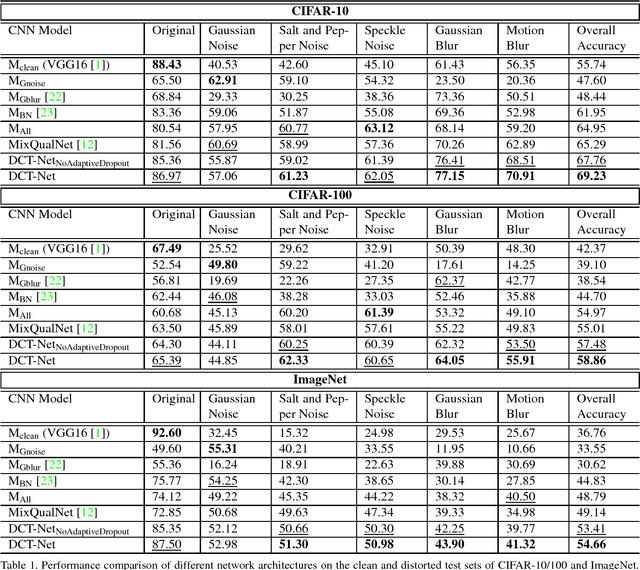


Convolutional Neural Network is good at image classification. However, it is found to be vulnerable to image quality degradation. Even a small amount of distortion such as noise or blur can severely hamper the performance of these CNN architectures. Most of the work in the literature strives to mitigate this problem simply by fine-tuning a pre-trained CNN on mutually exclusive or a union set of distorted training data. This iterative fine-tuning process with all known types of distortion is exhaustive and the network struggles to handle unseen distortions. In this work, we propose distortion robust DCT-Net, a Discrete Cosine Transform based module integrated into a deep network which is built on top of VGG16. Unlike other works in the literature, DCT-Net is "blind" to the distortion type and level in an image both during training and testing. As a part of the training process, the proposed DCT module discards input information which mostly represents the contribution of high frequencies. The DCT-Net is trained "blindly" only once and applied in generic situation without further retraining. We also extend the idea of traditional dropout and present a training adaptive version of the same. We evaluate our proposed method against Gaussian blur, motion blur, salt and pepper noise, Gaussian noise and speckle noise added to CIFAR-10/100 and ImageNet test sets. Experimental results demonstrate that once trained, DCT-Net not only generalizes well to a variety of unseen image distortions but also outperforms other methods in the literature.