 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRanking Counterfactual Explanations
Mar 20, 2025AI-driven outcomes can be challenging for end-users to understand. Explanations can address two key questions: "Why this outcome?" (factual) and "Why not another?" (counterfactual). While substantial efforts have been made to formalize factual explanations, a precise and comprehensive study of counterfactual explanations is still lacking. This paper proposes a formal definition of counterfactual explanations, proving some properties they satisfy, and examining the relationship with factual explanations. Given that multiple counterfactual explanations generally exist for a specific case, we also introduce a rigorous method to rank these counterfactual explanations, going beyond a simple minimality condition, and to identify the optimal ones. Our experiments with 12 real-world datasets highlight that, in most cases, a single optimal counterfactual explanation emerges. We also demonstrate, via three metrics, that the selected optimal explanation exhibits higher representativeness and can explain a broader range of elements than a random minimal counterfactual. This result highlights the effectiveness of our approach in identifying more robust and comprehensive counterfactual explanations.
Frank's triangular norms in Piaget's logical proportions
Aug 07, 2024Starting from the Boolean notion of logical proportion in Piaget's sense, which turns out to be equivalent to analogical proportion, this note proposes a definition of analogical proportion between numerical values based on triangular norms (and dual co-norms). Frank's family of triangular norms is particularly interesting from this perspective. The article concludes with a comparative discussion with another very recent proposal for defining analogical proportions between numerical values based on the family of generalized means.
Analogical Relevance Index
Jan 08, 2023Focusing on the most significant features of a dataset is useful both in machine learning (ML) and data mining. In ML, it can lead to a higher accuracy, a faster learning process, and ultimately a simpler and more understandable model. In data mining, identifying significant features is essential not only for gaining a better understanding of the data but also for visualization. In this paper, we demonstrate a new way of identifying significant features inspired by analogical proportions. Such a proportion is of the form of "a is to b as c is to d", comparing two pairs of items (a, b) and (c, d) in terms of similarities and dissimilarities. In a classification context, if the similarities/dissimilarities between a and b correlate with the fact that a and b have different labels, this knowledge can be transferred to c and d, inferring that c and d also have different labels. From a feature selection perspective, observing a huge number of such pairs (a, b) where a and b have different labels provides a hint about the importance of the features where a and b differ. Following this idea, we introduce the Analogical Relevance Index (ARI), a new statistical test of the significance of a given feature with respect to the label. ARI is a filter-based method. Filter-based methods are ML-agnostic but generally unable to handle feature redundancy. However, ARI can detect feature redundancy. Our experiments show that ARI is effective and outperforms well-known methods on a variety of artificial and some real datasets.
Some recent advances in reasoning based on analogical proportions
Dec 22, 2022



Analogical proportions compare pairs of items (a, b) and (c, d) in terms of their differences and similarities. They play a key role in the formalization of analogical inference. The paper first discusses how to improve analogical inference in terms of accuracy and in terms of computational cost. Then it indicates the potential of analogical proportions for explanation. Finally, it highlights the close relationship between analogical proportions and multi-valued dependencies, which reveals an unsuspected aspect of the former.
Dyslexia and Dysgraphia prediction: A new machine learning approach
Apr 15, 2020
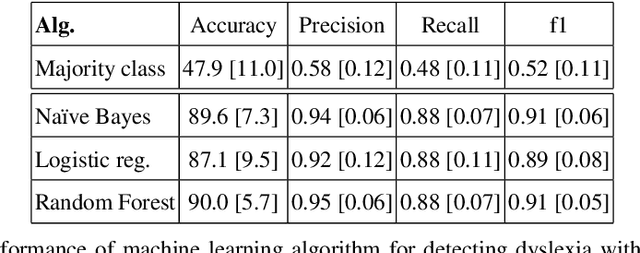


Learning disabilities like dysgraphia, dyslexia, dyspraxia, etc. interfere with academic achievements but have also long terms consequences beyond the academic time. It is widely admitted that between 5% to 10% of the world population is subject to this kind of disabilities. For assessing such disabilities in early childhood, children have to solve a battery of tests. Human experts score these tests, and decide whether the children require specific education strategy on the basis of their marks. The assessment can be lengthy, costly and emotionally painful. In this paper, we investigate how Artificial Intelligence can help in automating this assessment. Gathering a dataset of handwritten text pictures and audio recordings, both from standard children and from dyslexic and/or dysgraphic children, we apply machine learning techniques for classification in order to analyze the differences between dyslexic/dysgraphic and standard readers/writers and to build a model. The model is trained on simple features obtained by analysing the pictures and the audio files. Our preliminary implementation shows relatively high performances on the dataset we have used. This suggests the possibility to screen dyslexia and dysgraphia via non-invasive methods in an accurate way as soon as enough data are available.