 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyslexia and Dysgraphia prediction: A new machine learning approach
Paper and Code
Apr 15, 2020
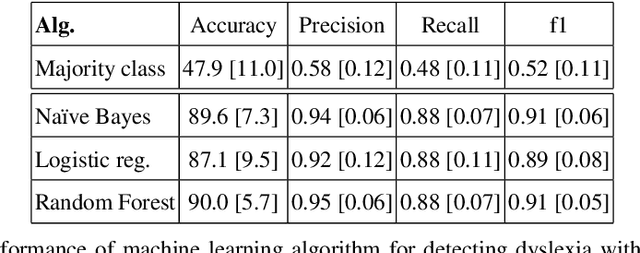


Learning disabilities like dysgraphia, dyslexia, dyspraxia, etc. interfere with academic achievements but have also long terms consequences beyond the academic time. It is widely admitted that between 5% to 10% of the world population is subject to this kind of disabilities. For assessing such disabilities in early childhood, children have to solve a battery of tests. Human experts score these tests, and decide whether the children require specific education strategy on the basis of their marks. The assessment can be lengthy, costly and emotionally painful. In this paper, we investigate how Artificial Intelligence can help in automating this assessment. Gathering a dataset of handwritten text pictures and audio recordings, both from standard children and from dyslexic and/or dysgraphic children, we apply machine learning techniques for classification in order to analyze the differences between dyslexic/dysgraphic and standard readers/writers and to build a model. The model is trained on simple features obtained by analysing the pictures and the audio files. Our preliminary implementation shows relatively high performances on the dataset we have used. This suggests the possibility to screen dyslexia and dysgraphia via non-invasive methods in an accurate way as soon as enough data are available.