 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStitchNet: Composing Neural Networks from Pre-Trained Fragments
Jan 05, 2023



We propose StitchNet, a novel neural network creation paradigm that stitches together fragments (one or more consecutive network layers) from multiple pre-trained neural networks. StitchNet allows the creation of high-performing neural networks without the large compute and data requirements needed under traditional model creation processes via backpropagation training. We leverage Centered Kernel Alignment (CKA) as a compatibility measure to efficiently guide the selection of these fragments in composing a network for a given task tailored to specific accuracy needs and computing resource constraints. We then show that these fragments can be stitched together to create neural networks with comparable accuracy to traditionally trained networks at a fraction of computing resource and data requirements. Finally, we explore a novel on-the-fly personalized model creation and inference application enabled by this new paradigm.
DaiMoN: A Decentralized Artificial Intelligence Model Network
Jul 19, 2019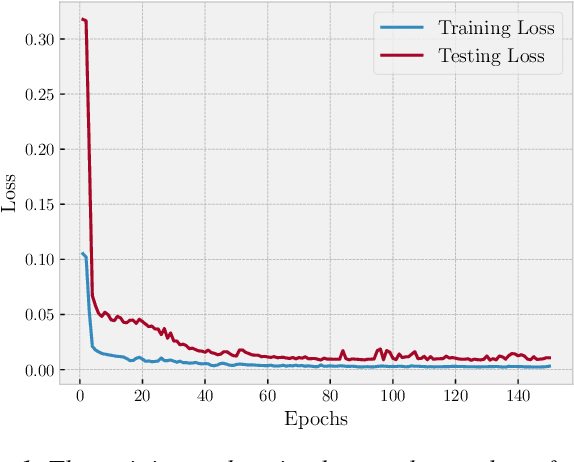
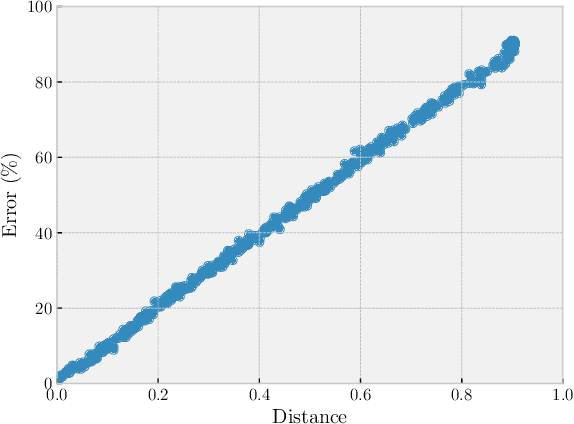
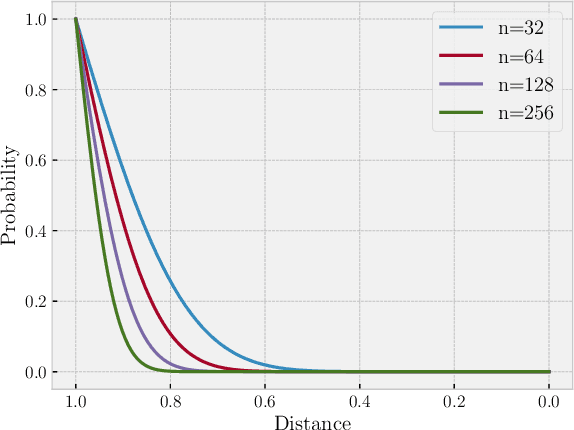
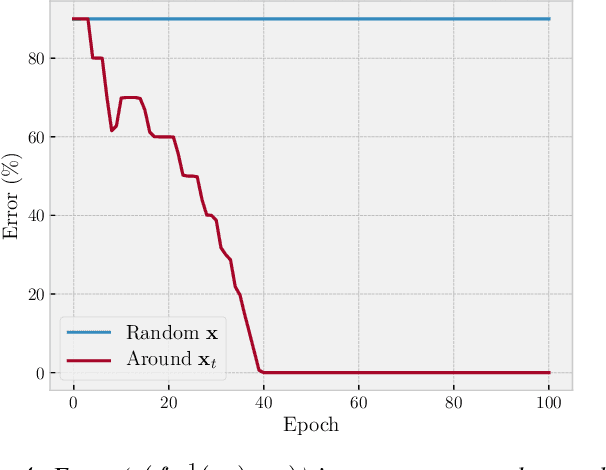
We introduce DaiMoN, a decentralized artificial intelligence model network, which incentivizes peer collaboration in improving the accuracy of machine learning models for a given classification problem. It is an autonomous network where peers may submit models with improved accuracy and other peers may verify the accuracy improvement. The system maintains an append-only decentralized ledger to keep the log of critical information, including who has trained the model and improved its accuracy, when it has been improved, by how much it has improved, and where to find the newly updated model. DaiMoN rewards these contributing peers with cryptographic tokens. A main feature of DaiMoN is that it allows peers to verify the accuracy improvement of submitted models without knowing the test labels. This is an essential component in order to mitigate intentional model overfitting by model-improving peers. To enable this model accuracy evaluation with hidden test labels, DaiMoN uses a novel learnable Distance Embedding for Labels (DEL) function proposed in this paper. Specific to each test dataset, DEL scrambles the test label vector by embedding it in a low-dimension space while approximately preserving the distance between the dataset's test label vector and a label vector inferred by the classifier. It therefore allows proof-of-improvement (PoI) by peers without providing them access to true test labels. We provide analysis and empirical evidence that under DEL, peers can accurately assess model accuracy. We also argue that it is hard to invert the embedding function and thus, DEL is resilient against attacks aiming to recover test labels in order to cheat. Our prototype implementation of DaiMoN is available at https://github.com/steerapi/daimon.
CheckNet: Secure Inference on Untrusted Devices
Jun 17, 2019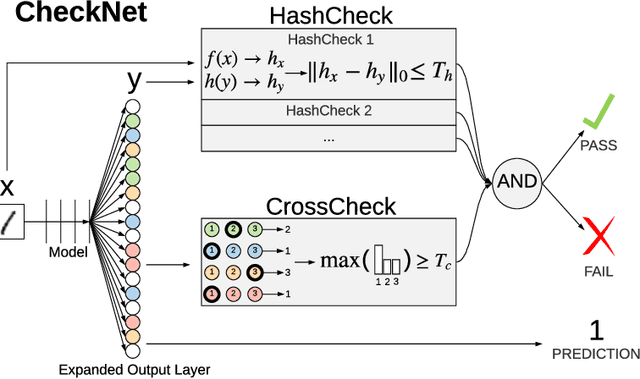
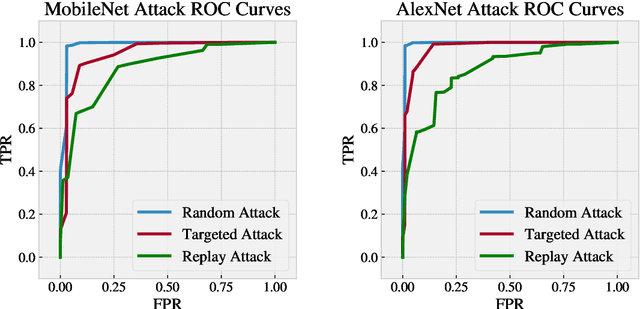
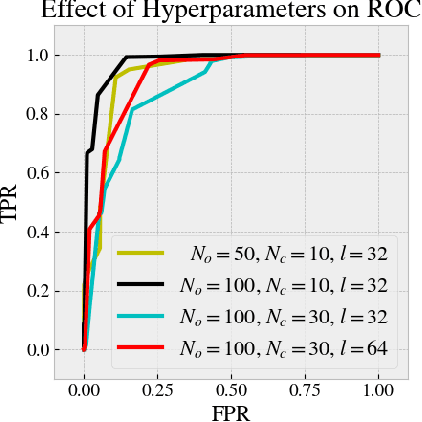
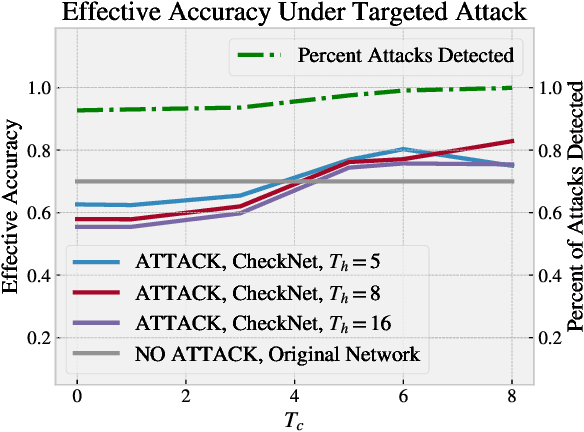
We introduce CheckNet, a method for secure inference with deep neural networks on untrusted devices. CheckNet is like a checksum for neural network inference: it verifies the integrity of the inference computation performed by untrusted devices to 1) ensure the inference has actually been performed, and 2) ensure the inference has not been manipulated by an attacker. CheckNet is completely transparent to the third party running the computation, applicable to all types of neural networks, does not require specialized hardware, adds little overhead, and has negligible impact on model performance. CheckNet can be configured to provide different levels of security depending on application needs and compute/communication budgets. We present both empirical and theoretical validation of CheckNet on multiple popular deep neural network models, showing excellent attack detection (0.88-0.99 AUC) and attack success bounds.
Incomplete Dot Products for Dynamic Computation Scaling in Neural Network Inference
Oct 21, 2017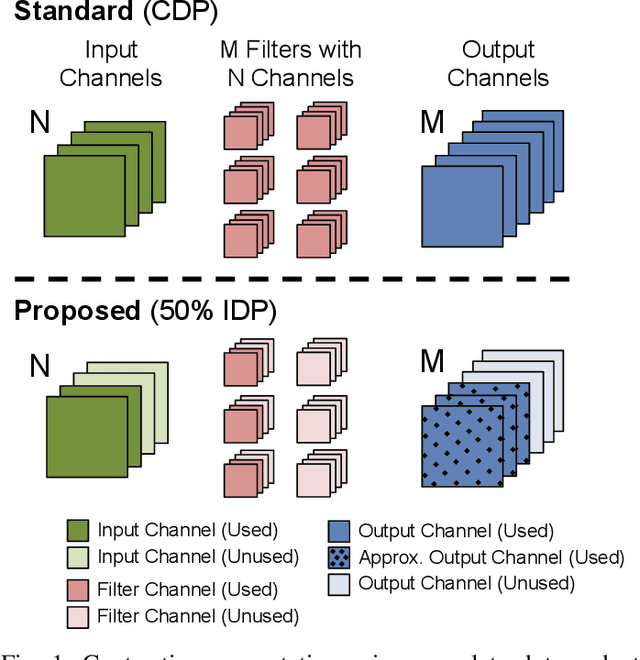



We propose the use of incomplete dot products (IDP) to dynamically adjust the number of input channels used in each layer of a convolutional neural network during feedforward inference. IDP adds monotonically non-increasing coefficients, referred to as a "profile", to the channels during training. The profile orders the contribution of each channel in non-increasing order. At inference time, the number of channels used can be dynamically adjusted to trade off accuracy for lowered power consumption and reduced latency by selecting only a beginning subset of channels. This approach allows for a single network to dynamically scale over a computation range, as opposed to training and deploying multiple networks to support different levels of computation scaling. Additionally, we extend the notion to multiple profiles, each optimized for some specific range of computation scaling. We present experiments on the computation and accuracy trade-offs of IDP for popular image classification models and datasets. We demonstrate that, for MNIST and CIFAR-10, IDP reduces computation significantly, e.g., by 75%, without significantly compromising accuracy. We argue that IDP provides a convenient and effective means for devices to lower computation costs dynamically to reflect the current computation budget of the system. For example, VGG-16 with 50% IDP (using only the first 50% of channels) achieves 70% in accuracy on the CIFAR-10 dataset compared to the standard network which achieves only 35% accuracy when using the reduced channel set.
Embedded Binarized Neural Networks
Sep 06, 2017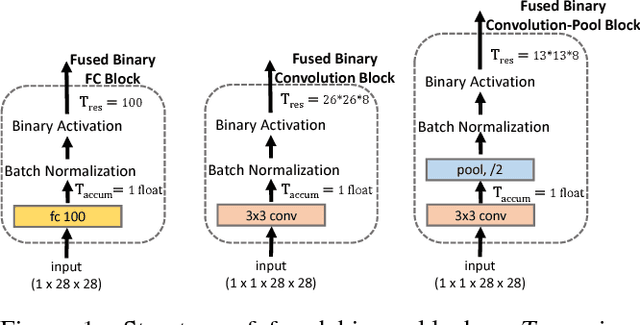

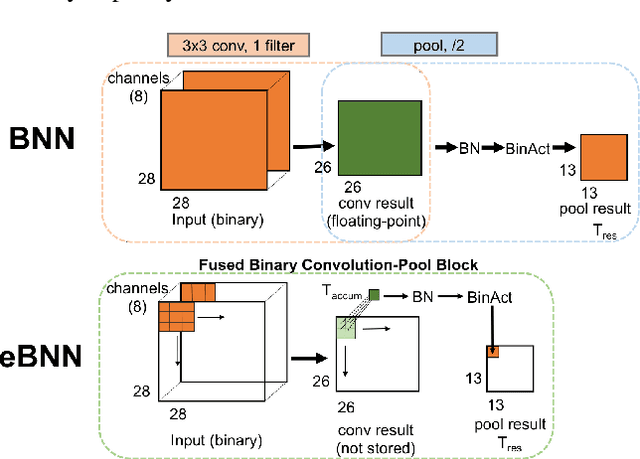

We study embedded Binarized Neural Networks (eBNNs) with the aim of allowing current binarized neural networks (BNNs) in the literature to perform feedforward inference efficiently on small embedded devices. We focus on minimizing the required memory footprint, given that these devices often have memory as small as tens of kilobytes (KB). Beyond minimizing the memory required to store weights, as in a BNN, we show that it is essential to minimize the memory used for temporaries which hold intermediate results between layers in feedforward inference. To accomplish this, eBNN reorders the computation of inference while preserving the original BNN structure, and uses just a single floating-point temporary for the entire neural network. All intermediate results from a layer are stored as binary values, as opposed to floating-points used in current BNN implementations, leading to a 32x reduction in required temporary space. We provide empirical evidence that our proposed eBNN approach allows efficient inference (10s of ms) on devices with severely limited memory (10s of KB). For example, eBNN achieves 95\% accuracy on the MNIST dataset running on an Intel Curie with only 15 KB of usable memory with an inference runtime of under 50 ms per sample. To ease the development of applications in embedded contexts, we make our source code available that allows users to train and discover eBNN models for a learning task at hand, which fit within the memory constraint of the target device.
BranchyNet: Fast Inference via Early Exiting from Deep Neural Networks
Sep 06, 2017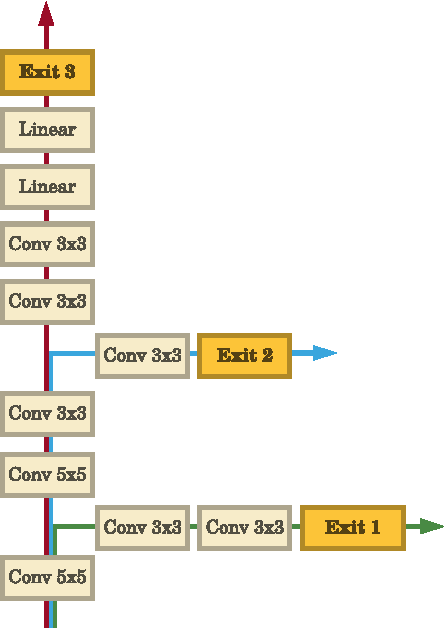


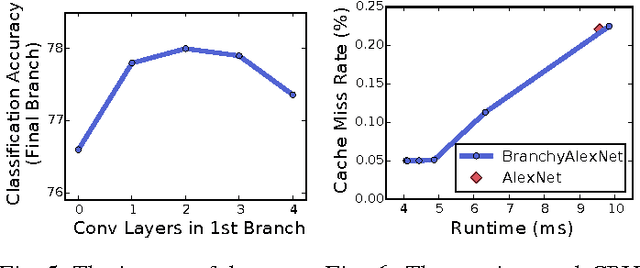
Deep neural networks are state of the art methods for many learning tasks due to their ability to extract increasingly better features at each network layer. However, the improved performance of additional layers in a deep network comes at the cost of added latency and energy usage in feedforward inference. As networks continue to get deeper and larger, these costs become more prohibitive for real-time and energy-sensitive applications. To address this issue, we present BranchyNet, a novel deep network architecture that is augmented with additional side branch classifiers. The architecture allows prediction results for a large portion of test samples to exit the network early via these branches when samples can already be inferred with high confidence. BranchyNet exploits the observation that features learned at an early layer of a network may often be sufficient for the classification of many data points. For more difficult samples, which are expected less frequently, BranchyNet will use further or all network layers to provide the best likelihood of correct prediction. We study the BranchyNet architecture using several well-known networks (LeNet, AlexNet, ResNet) and datasets (MNIST, CIFAR10) and show that it can both improve accuracy and significantly reduce the inference time of the network.
Distributed Deep Neural Networks over the Cloud, the Edge and End Devices
Sep 06, 2017
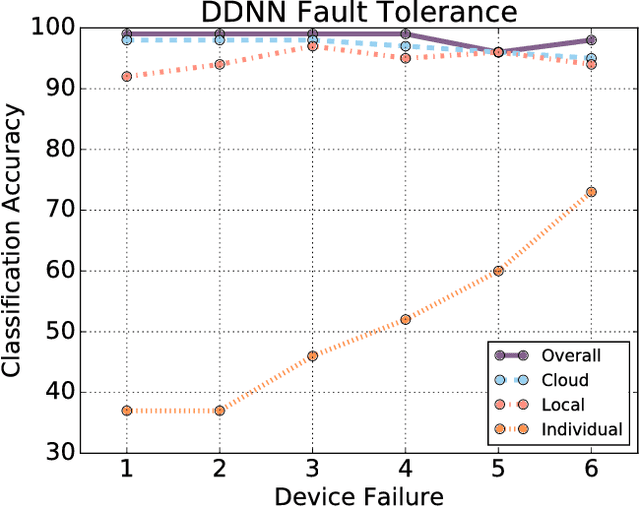
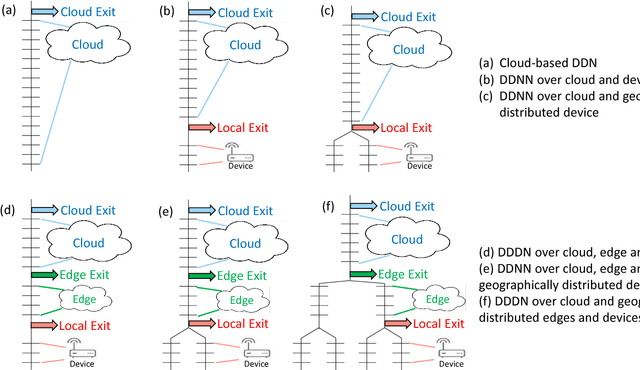
We propose distributed deep neural networks (DDNNs) over distributed computing hierarchies, consisting of the cloud, the edge (fog) and end devices. While being able to accommodate inference of a deep neural network (DNN) in the cloud, a DDNN also allows fast and localized inference using shallow portions of the neural network at the edge and end devices. When supported by a scalable distributed computing hierarchy, a DDNN can scale up in neural network size and scale out in geographical span. Due to its distributed nature, DDNNs enhance sensor fusion, system fault tolerance and data privacy for DNN applications. In implementing a DDNN, we map sections of a DNN onto a distributed computing hierarchy. By jointly training these sections, we minimize communication and resource usage for devices and maximize usefulness of extracted features which are utilized in the cloud. The resulting system has built-in support for automatic sensor fusion and fault tolerance. As a proof of concept, we show a DDNN can exploit geographical diversity of sensors to improve object recognition accuracy and reduce communication cost. In our experiment, compared with the traditional method of offloading raw sensor data to be processed in the cloud, DDNN locally processes most sensor data on end devices while achieving high accuracy and is able to reduce the communication cost by a factor of over 20x.