 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBranchyNet: Fast Inference via Early Exiting from Deep Neural Networks
Paper and Code
Sep 06, 2017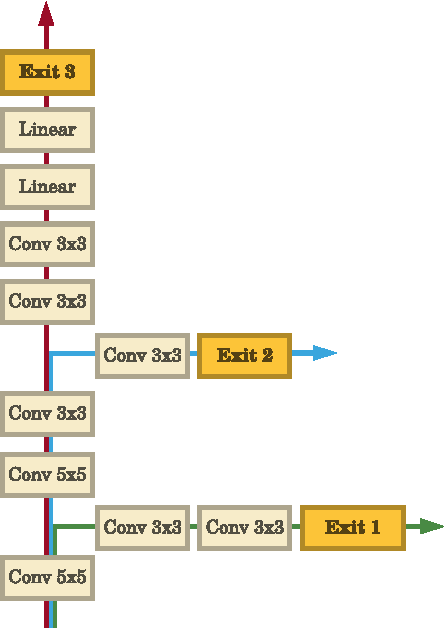


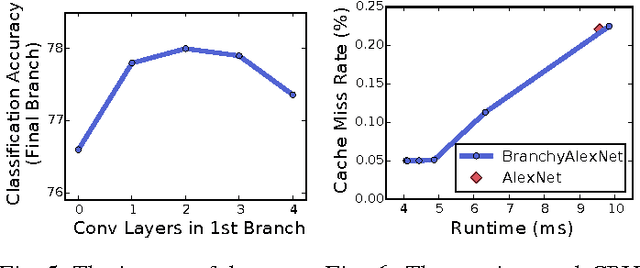
Deep neural networks are state of the art methods for many learning tasks due to their ability to extract increasingly better features at each network layer. However, the improved performance of additional layers in a deep network comes at the cost of added latency and energy usage in feedforward inference. As networks continue to get deeper and larger, these costs become more prohibitive for real-time and energy-sensitive applications. To address this issue, we present BranchyNet, a novel deep network architecture that is augmented with additional side branch classifiers. The architecture allows prediction results for a large portion of test samples to exit the network early via these branches when samples can already be inferred with high confidence. BranchyNet exploits the observation that features learned at an early layer of a network may often be sufficient for the classification of many data points. For more difficult samples, which are expected less frequently, BranchyNet will use further or all network layers to provide the best likelihood of correct prediction. We study the BranchyNet architecture using several well-known networks (LeNet, AlexNet, ResNet) and datasets (MNIST, CIFAR10) and show that it can both improve accuracy and significantly reduce the inference time of the network.