 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Data Repair Lead to Fair Models? Curating Contextually Fair Data To Reduce Model Bias
Oct 20, 2021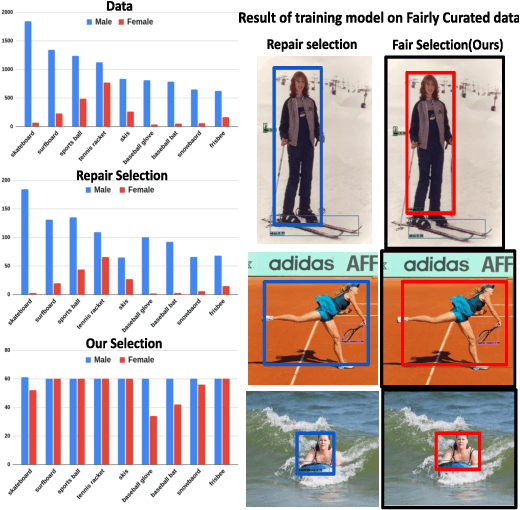
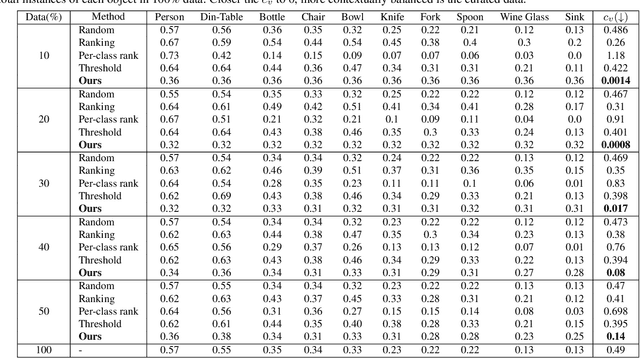


Contextual information is a valuable cue for Deep Neural Networks (DNNs) to learn better representations and improve accuracy. However, co-occurrence bias in the training dataset may hamper a DNN model's generalizability to unseen scenarios in the real world. For example, in COCO, many object categories have a much higher co-occurrence with men compared to women, which can bias a DNN's prediction in favor of men. Recent works have focused on task-specific training strategies to handle bias in such scenarios, but fixing the available data is often ignored. In this paper, we propose a novel and more generic solution to address the contextual bias in the datasets by selecting a subset of the samples, which is fair in terms of the co-occurrence with various classes for a protected attribute. We introduce a data repair algorithm using the coefficient of variation, which can curate fair and contextually balanced data for a protected class(es). This helps in training a fair model irrespective of the task, architecture or training methodology. Our proposed solution is simple, effective, and can even be used in an active learning setting where the data labels are not present or being generated incrementally. We demonstrate the effectiveness of our algorithm for the task of object detection and multi-label image classification across different datasets. Through a series of experiments, we validate that curating contextually fair data helps make model predictions fair by balancing the true positive rate for the protected class across groups without compromising on the model's overall performance.
A Study of Black Box Adversarial Attacks in Computer Vision
Dec 03, 2019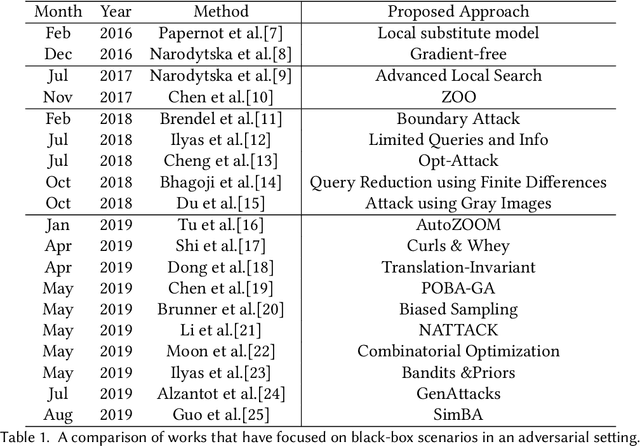

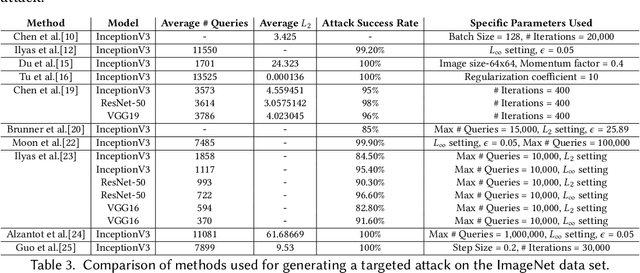

Machine learning has seen tremendous advances in the past few years which has lead to deep learning models being deployed in varied applications of day-to-day life. Attacks on such models using perturbations, particularly in real-life scenarios, pose a serious challenge to their applicability, pushing research into the direction which aims to enhance the robustness of these models. After the introduction of these perturbations by Szegedy et al., significant amount of research has focused on the reliability of such models, primarily in two aspects - white-box, where the adversary has access to the targeted model and related parameters; and the black-box, which resembles a real-life scenario with the adversary having almost no knowledge of the model to be attacked. We propose to attract attention on the latter scenario and thus, present a comprehensive comparative study among the different adversarial black-box attack approaches proposed till date. The second half of this literature survey focuses on the defense techniques. This is the first study, to the best of our knowledge, that specifically focuses on the black-box setting to motivate future work on the same.