 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Intrusion Detection for Evolving RPL IoT Attacks Using Incremental Learning
Nov 14, 2025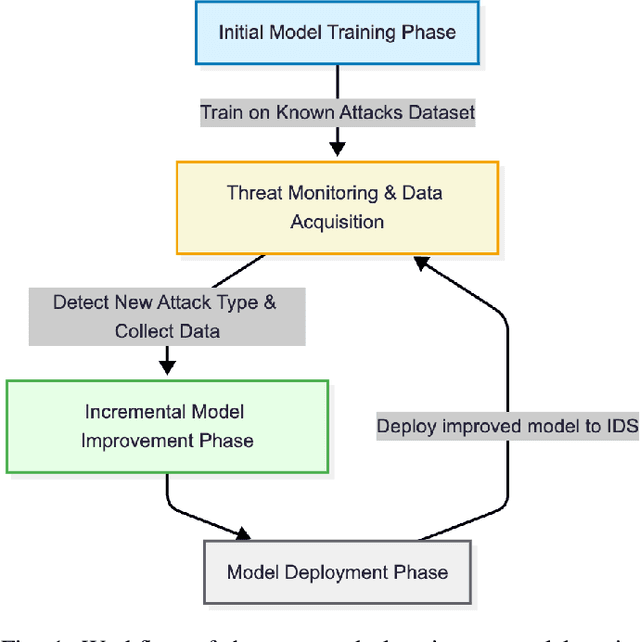

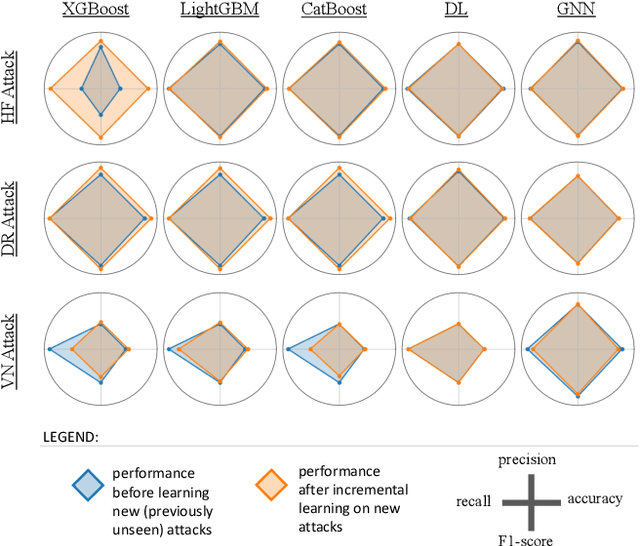

The routing protocol for low-power and lossy networks (RPL) has become the de facto routing standard for resource-constrained IoT systems, but its lightweight design exposes critical vulnerabilities to a wide range of routing-layer attacks such as hello flood, decreased rank, and version number manipulation. Traditional countermeasures, including protocol-level modifications and machine learning classifiers, can achieve high accuracy against known threats, yet they fail when confronted with novel or zero-day attacks unless fully retrained, an approach that is impractical for dynamic IoT environments. In this paper, we investigate incremental learning as a practical and adaptive strategy for intrusion detection in RPL-based networks. We systematically evaluate five model families, including ensemble models and deep learning models. Our analysis highlights that incremental learning not only restores detection performance on new attack classes but also mitigates catastrophic forgetting of previously learned threats, all while reducing training time compared to full retraining. By combining five diverse models with attack-specific analysis, forgetting behavior, and time efficiency, this study provides systematic evidence that incremental learning offers a scalable pathway to maintain resilient intrusion detection in evolving RPL-based IoT networks.
WBHT: A Generative Attention Architecture for Detecting Black Hole Anomalies in Backbone Networks
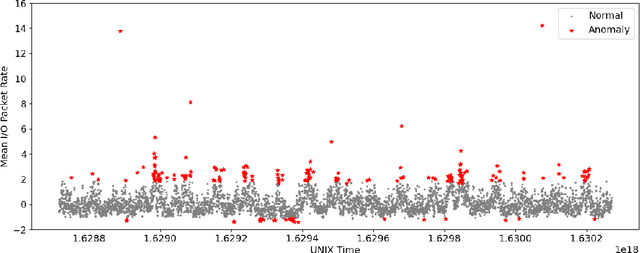
Jul 27, 2025We propose the Wasserstein Black Hole Transformer (WBHT) framework for detecting black hole (BH) anomalies in communication networks. These anomalies cause packet loss without failure notifications, disrupting connectivity and leading to financial losses. WBHT combines generative modeling, sequential learning, and attention mechanisms to improve BH anomaly detection. It integrates a Wasserstein generative adversarial network with attention mechanisms for stable training and accurate anomaly identification. The model uses long-short-term memory layers to capture long-term dependencies and convolutional layers for local temporal patterns. A latent space encoding mechanism helps distinguish abnormal network behavior. Tested on real-world network data, WBHT outperforms existing models, achieving significant improvements in F1 score (ranging from 1.65% to 58.76%). Its efficiency and ability to detect previously undetected anomalies make it a valuable tool for proactive network monitoring and security, especially in mission-critical networks.
IBB Traffic Graph Data: Benchmarking and Road Traffic Prediction Model
Aug 02, 2024Road traffic congestion prediction is a crucial component of intelligent transportation systems, since it enables proactive traffic management, enhances suburban experience, reduces environmental impact, and improves overall safety and efficiency. Although there are several public datasets, especially for metropolitan areas, these datasets may not be applicable to practical scenarios due to insufficiency in the scale of data (i.e. number of sensors and road links) and several external factors like different characteristics of the target area such as urban, highways and the data collection location. To address this, this paper introduces a novel IBB Traffic graph dataset as an alternative benchmark dataset to mitigate these limitations and enrich the literature with new geographical characteristics. IBB Traffic graph dataset covers the sensor data collected at 2451 distinct locations. Moreover, we propose a novel Road Traffic Prediction Model that strengthens temporal links through feature engineering, node embedding with GLEE to represent inter-related relationships within the traffic network, and traffic prediction with ExtraTrees. The results indicate that the proposed model consistently outperforms the baseline models, demonstrating an average accuracy improvement of 4%.
Data Augmentation in Graph Neural Networks: The Role of Generated Synthetic Graphs
Jul 20, 2024



Graphs are crucial for representing interrelated data and aiding predictive modeling by capturing complex relationships. Achieving high-quality graph representation is important for identifying linked patterns, leading to improvements in Graph Neural Networks (GNNs) to better capture data structures. However, challenges such as data scarcity, high collection costs, and ethical concerns limit progress. As a result, generative models and data augmentation have become more and more popular. This study explores using generated graphs for data augmentation, comparing the performance of combining generated graphs with real graphs, and examining the effect of different quantities of generated graphs on graph classification tasks. The experiments show that balancing scalability and quality requires different generators based on graph size. Our results introduce a new approach to graph data augmentation, ensuring consistent labels and enhancing classification performance.
Enriching User Shopping History: Empowering E-commerce with a Hierarchical Recommendation System
Mar 15, 2024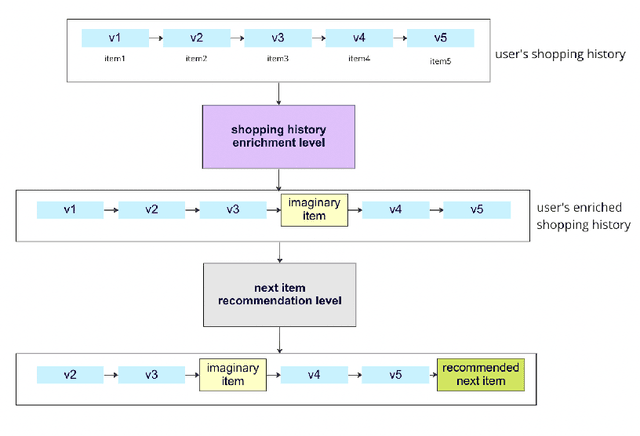



Recommendation systems can provide accurate recommendations by analyzing user shopping history. A richer user history results in more accurate recommendations. However, in real applications, users prefer e-commerce platforms where the item they seek is at the lowest price. In other words, most users shop from multiple e-commerce platforms simultaneously; different parts of the user's shopping history are shared between different e-commerce platforms. Consequently, we assume in this study that any e-commerce platform has a complete record of the user's history but can only access some parts of it. If a recommendation system is able to predict the missing parts first and enrich the user's shopping history properly, it will be possible to recommend the next item more accurately. Our recommendation system leverages user shopping history to improve prediction accuracy. The proposed approach shows significant improvements in both NDCG@10 and HR@10.
X-CBA: Explainability Aided CatBoosted Anomal-E for Intrusion Detection System
Feb 01, 2024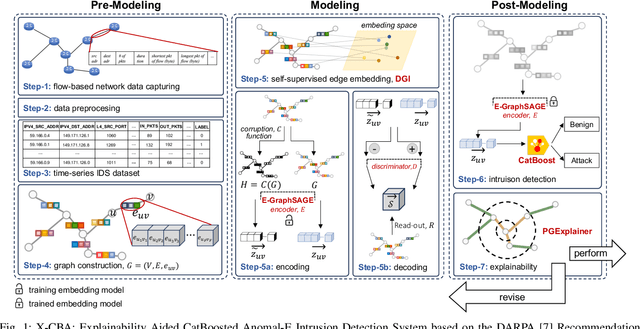
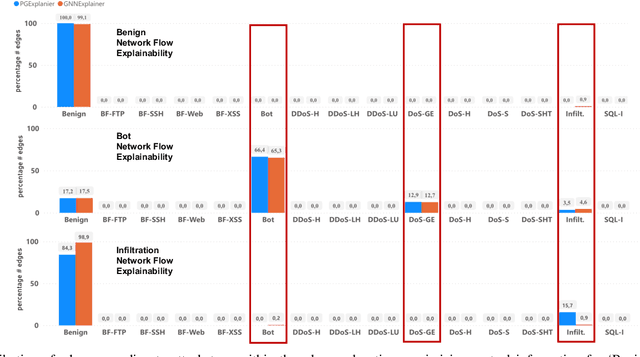
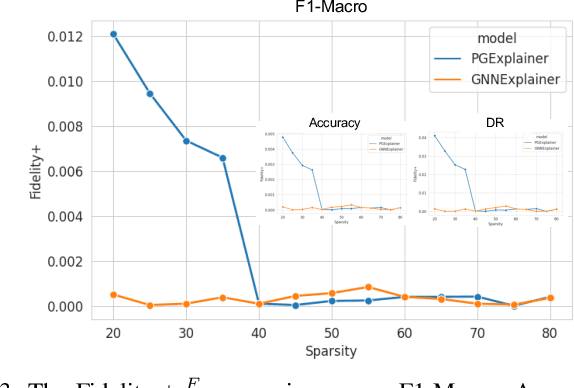

The effectiveness of Intrusion Detection Systems (IDS) is critical in an era where cyber threats are becoming increasingly complex. Machine learning (ML) and deep learning (DL) models provide an efficient and accurate solution for identifying attacks and anomalies in computer networks. However, using ML and DL models in IDS has led to a trust deficit due to their non-transparent decision-making. This transparency gap in IDS research is significant, affecting confidence and accountability. To address, this paper introduces a novel Explainable IDS approach, called X-CBA, that leverages the structural advantages of Graph Neural Networks (GNNs) to effectively process network traffic data, while also adapting a new Explainable AI (XAI) methodology. Unlike most GNN-based IDS that depend on labeled network traffic and node features, thereby overlooking critical packet-level information, our approach leverages a broader range of traffic data through network flows, including edge attributes, to improve detection capabilities and adapt to novel threats. Through empirical testing, we establish that our approach not only achieves high accuracy with 99.47% in threat detection but also advances the field by providing clear, actionable explanations of its analytical outcomes. This research also aims to bridge the current gap and facilitate the broader integration of ML/DL technologies in cybersecurity defenses by offering a local and global explainability solution that is both precise and interpretable.
A YANG-aided Unified Strategy for Black Hole Detection for Backbone Networks
Feb 01, 2024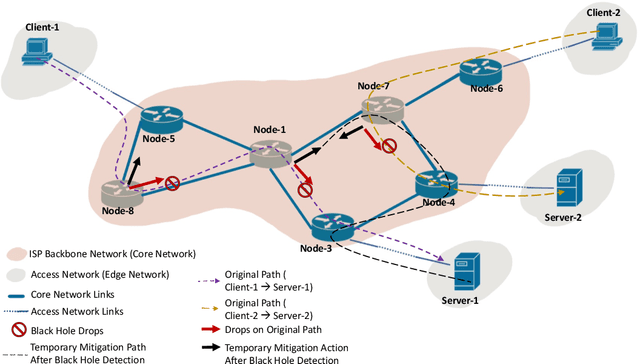

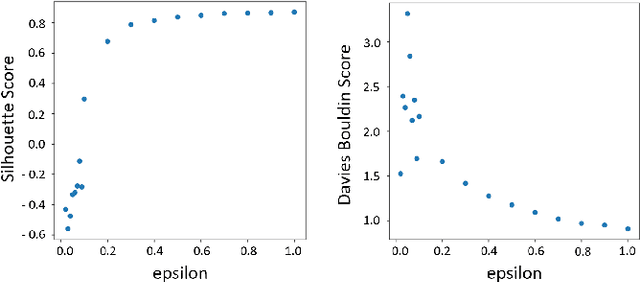
Despite the crucial importance of addressing Black Hole failures in Internet backbone networks, effective detection strategies in backbone networks are lacking. This is largely because previous research has been centered on Mobile Ad-hoc Networks (MANETs), which operate under entirely different dynamics, protocols, and topologies, making their findings not directly transferable to backbone networks. Furthermore, detecting Black Hole failures in backbone networks is particularly challenging. It requires a comprehensive range of network data due to the wide variety of conditions that need to be considered, making data collection and analysis far from straightforward. Addressing this gap, our study introduces a novel approach for Black Hole detection in backbone networks using specialized Yet Another Next Generation (YANG) data models with Black Hole-sensitive Metric Matrix (BHMM) analysis. This paper details our method of selecting and analyzing four YANG models relevant to Black Hole detection in ISP networks, focusing on routing protocols and ISP-specific configurations. Our BHMM approach derived from these models demonstrates a 10% improvement in detection accuracy and a 13% increase in packet delivery rate, highlighting the efficiency of our approach. Additionally, we evaluate the Machine Learning approach leveraged with BHMM analysis in two different network settings, a commercial ISP network, and a scientific research-only network topology. This evaluation also demonstrates the practical applicability of our method, yielding significantly improved prediction outcomes in both environments.
Ranky : An Approach to Solve Distributed SVD on Large Sparse Matrices
Sep 21, 2020

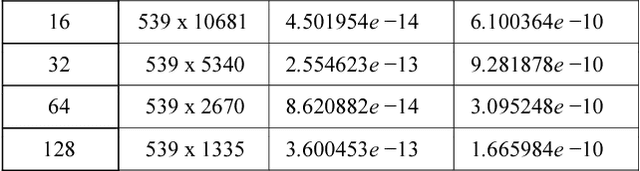
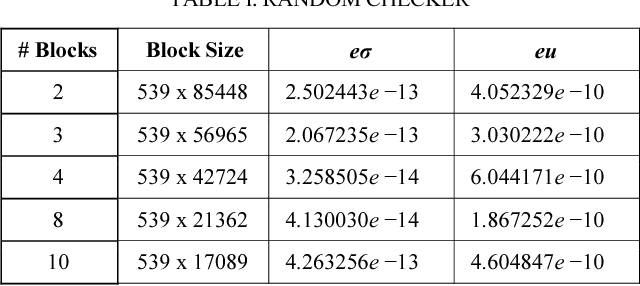
Singular Value Decomposition (SVD) is a well studied research topic in many fields and applications from data mining to image processing. Data arising from these applications can be represented as a matrix where it is large and sparse. Most existing algorithms are used to calculate singular values, left and right singular vectors of a large-dense matrix but not large and sparse matrix. Even if they can find SVD of a large matrix, calculation of large-dense matrix has high time complexity due to sequential algorithms. Distributed approaches are proposed for computing SVD of large matrices. However, rank of the matrix is still being a problem when solving SVD with these distributed algorithms. In this paper we propose Ranky, set of methods to solve rank problem on large and sparse matrices in a distributed manner. Experimental results show that the Ranky approach recovers singular values, singular left and right vectors of a given large and sparse matrix with negligible error.
Demand Prediction Using Machine Learning Methods and Stacked Generalization
Sep 21, 2020
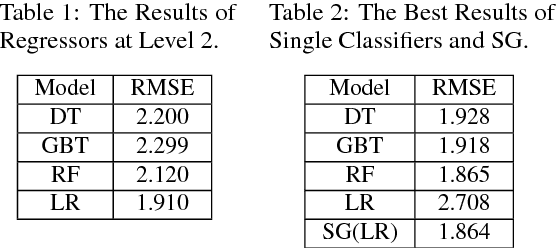


Supply and demand are two fundamental concepts of sellers and customers. Predicting demand accurately is critical for organizations in order to be able to make plans. In this paper, we propose a new approach for demand prediction on an e-commerce web site. The proposed model differs from earlier models in several ways. The business model used in the e-commerce web site, for which the model is implemented, includes many sellers that sell the same product at the same time at different prices where the company operates a market place model. The demand prediction for such a model should consider the price of the same product sold by competing sellers along the features of these sellers. In this study we first applied different regression algorithms for specific set of products of one department of a company that is one of the most popular online e-commerce companies in Turkey. Then we used stacked generalization or also known as stacking ensemble learning to predict demand. Finally, all the approaches are evaluated on a real world data set obtained from the e-commerce company. The experimental results show that some of the machine learning methods do produce almost as good results as the stacked generalization method.