 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Cross-Market Recommendation System with Graph Isomorphism Networks: A Novel Approach to Personalized User Experience
Sep 12, 2024In today's world of globalized commerce, cross-market recommendation systems (CMRs) are crucial for providing personalized user experiences across diverse market segments. However, traditional recommendation algorithms have difficulties dealing with market specificity and data sparsity, especially in new or emerging markets. In this paper, we propose the CrossGR model, which utilizes Graph Isomorphism Networks (GINs) to improve CMR systems. It outperforms existing benchmarks in NDCG@10 and HR@10 metrics, demonstrating its adaptability and accuracy in handling diverse market segments. The CrossGR model is adaptable and accurate, making it well-suited for handling the complexities of cross-market recommendation tasks. Its robustness is demonstrated by consistent performance across different evaluation timeframes, indicating its potential to cater to evolving market trends and user preferences. Our findings suggest that GINs represent a promising direction for CMRs, paving the way for more sophisticated, personalized, and context-aware recommendation systems in the dynamic landscape of global e-commerce.
IBB Traffic Graph Data: Benchmarking and Road Traffic Prediction Model
Aug 02, 2024Road traffic congestion prediction is a crucial component of intelligent transportation systems, since it enables proactive traffic management, enhances suburban experience, reduces environmental impact, and improves overall safety and efficiency. Although there are several public datasets, especially for metropolitan areas, these datasets may not be applicable to practical scenarios due to insufficiency in the scale of data (i.e. number of sensors and road links) and several external factors like different characteristics of the target area such as urban, highways and the data collection location. To address this, this paper introduces a novel IBB Traffic graph dataset as an alternative benchmark dataset to mitigate these limitations and enrich the literature with new geographical characteristics. IBB Traffic graph dataset covers the sensor data collected at 2451 distinct locations. Moreover, we propose a novel Road Traffic Prediction Model that strengthens temporal links through feature engineering, node embedding with GLEE to represent inter-related relationships within the traffic network, and traffic prediction with ExtraTrees. The results indicate that the proposed model consistently outperforms the baseline models, demonstrating an average accuracy improvement of 4%.
Data Augmentation in Graph Neural Networks: The Role of Generated Synthetic Graphs
Jul 20, 2024



Graphs are crucial for representing interrelated data and aiding predictive modeling by capturing complex relationships. Achieving high-quality graph representation is important for identifying linked patterns, leading to improvements in Graph Neural Networks (GNNs) to better capture data structures. However, challenges such as data scarcity, high collection costs, and ethical concerns limit progress. As a result, generative models and data augmentation have become more and more popular. This study explores using generated graphs for data augmentation, comparing the performance of combining generated graphs with real graphs, and examining the effect of different quantities of generated graphs on graph classification tasks. The experiments show that balancing scalability and quality requires different generators based on graph size. Our results introduce a new approach to graph data augmentation, ensuring consistent labels and enhancing classification performance.
Ranky : An Approach to Solve Distributed SVD on Large Sparse Matrices
Sep 21, 2020

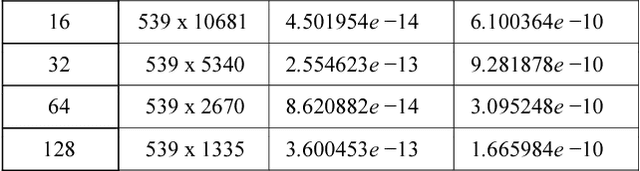
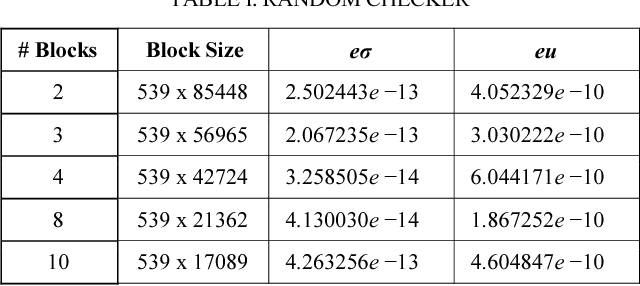
Singular Value Decomposition (SVD) is a well studied research topic in many fields and applications from data mining to image processing. Data arising from these applications can be represented as a matrix where it is large and sparse. Most existing algorithms are used to calculate singular values, left and right singular vectors of a large-dense matrix but not large and sparse matrix. Even if they can find SVD of a large matrix, calculation of large-dense matrix has high time complexity due to sequential algorithms. Distributed approaches are proposed for computing SVD of large matrices. However, rank of the matrix is still being a problem when solving SVD with these distributed algorithms. In this paper we propose Ranky, set of methods to solve rank problem on large and sparse matrices in a distributed manner. Experimental results show that the Ranky approach recovers singular values, singular left and right vectors of a given large and sparse matrix with negligible error.
Demand Prediction Using Machine Learning Methods and Stacked Generalization
Sep 21, 2020
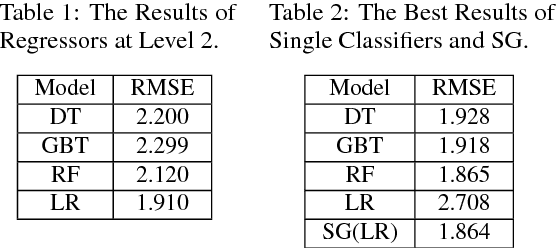


Supply and demand are two fundamental concepts of sellers and customers. Predicting demand accurately is critical for organizations in order to be able to make plans. In this paper, we propose a new approach for demand prediction on an e-commerce web site. The proposed model differs from earlier models in several ways. The business model used in the e-commerce web site, for which the model is implemented, includes many sellers that sell the same product at the same time at different prices where the company operates a market place model. The demand prediction for such a model should consider the price of the same product sold by competing sellers along the features of these sellers. In this study we first applied different regression algorithms for specific set of products of one department of a company that is one of the most popular online e-commerce companies in Turkey. Then we used stacked generalization or also known as stacking ensemble learning to predict demand. Finally, all the approaches are evaluated on a real world data set obtained from the e-commerce company. The experimental results show that some of the machine learning methods do produce almost as good results as the stacked generalization method.
Hotel Recommendation System Based on User Profiles and Collaborative Filtering
Sep 21, 2020Nowadays, people start to use online reservation systems to plan their vacations since they have vast amount of choices available. Selecting when and where to go from this large-scale options is getting harder. In addition, sometimes consumers can miss the better options due to the wealth of information to be found on the online reservation systems. In this sense, personalized services such as recommender systems play a crucial role in decision making. Two traditional recommendation techniques are content-based and collaborative filtering. While both methods have their advantages, they also have certain disadvantages, some of which can be solved by combining both techniques to improve the quality of the recommendation. The resulting system is known as a hybrid recommender system. This paper presents a new hybrid hotel recommendation system that has been developed by combining content-based and collaborative filtering approaches that recommends customer the hotel they need and save them from time loss.