 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Time Pressure of Powered Two-Wheeler Riders for Proactive Safety Interventions
Jan 06, 2026Time pressure critically influences risky maneuvers and crash proneness among powered two-wheeler riders, yet its prediction remains underexplored in intelligent transportation systems. We present a large-scale dataset of 129,000+ labeled multivariate time-series sequences from 153 rides by 51 participants under No, Low, and High Time Pressure conditions. Each sequence captures 63 features spanning vehicle kinematics, control inputs, behavioral violations, and environmental context. Our empirical analysis shows High Time Pressure induces 48% higher speeds, 36.4% greater speed variability, 58% more risky turns at intersections, 36% more sudden braking, and 50% higher rear brake forces versus No Time Pressure. To benchmark this dataset, we propose MotoTimePressure, a deep learning model combining convolutional preprocessing, dual-stage temporal attention, and Squeeze-and-Excitation feature recalibration, achieving 91.53% accuracy and 98.93% ROC AUC, outperforming eight baselines. Since time pressure cannot be directly measured in real time, we demonstrate its utility in collision prediction and threshold determination. Using MTPS-predicted time pressure as features, improves Informer-based collision risk accuracy from 91.25% to 93.51%, approaching oracle performance (93.72%). Thresholded time pressure states capture rider cognitive stress and enable proactive ITS interventions, including adaptive alerts, haptic feedback, V2I signaling, and speed guidance, supporting safer two-wheeler mobility under the Safe System Approach.
WISE: Web Information Satire and Fakeness Evaluation
Dec 30, 2025Distinguishing fake or untrue news from satire or humor poses a unique challenge due to their overlapping linguistic features and divergent intent. This study develops WISE (Web Information Satire and Fakeness Evaluation) framework which benchmarks eight lightweight transformer models alongside two baseline models on a balanced dataset of 20,000 samples from Fakeddit, annotated as either fake news or satire. Using stratified 5-fold cross-validation, we evaluate models across comprehensive metrics including accuracy, precision, recall, F1-score, ROC-AUC, PR-AUC, MCC, Brier score, and Expected Calibration Error. Our evaluation reveals that MiniLM, a lightweight model, achieves the highest accuracy (87.58%) among all models, while RoBERTa-base achieves the highest ROC-AUC (95.42%) and strong accuracy (87.36%). DistilBERT offers an excellent efficiency-accuracy trade-off with 86.28\% accuracy and 93.90\% ROC-AUC. Statistical tests confirm significant performance differences between models, with paired t-tests and McNemar tests providing rigorous comparisons. Our findings highlight that lightweight models can match or exceed baseline performance, offering actionable insights for deploying misinformation detection systems in real-world, resource-constrained settings.
SPARK: Search Personalization via Agent-Driven Retrieval and Knowledge-sharing
Dec 30, 2025Personalized search demands the ability to model users' evolving, multi-dimensional information needs; a challenge for systems constrained by static profiles or monolithic retrieval pipelines. We present SPARK (Search Personalization via Agent-Driven Retrieval and Knowledge-sharing), a framework in which coordinated persona-based large language model (LLM) agents deliver task-specific retrieval and emergent personalization. SPARK formalizes a persona space defined by role, expertise, task context, and domain, and introduces a Persona Coordinator that dynamically interprets incoming queries to activate the most relevant specialized agents. Each agent executes an independent retrieval-augmented generation process, supported by dedicated long- and short-term memory stores and context-aware reasoning modules. Inter-agent collaboration is facilitated through structured communication protocols, including shared memory repositories, iterative debate, and relay-style knowledge transfer. Drawing on principles from cognitive architectures, multi-agent coordination theory, and information retrieval, SPARK models how emergent personalization properties arise from distributed agent behaviors governed by minimal coordination rules. The framework yields testable predictions regarding coordination efficiency, personalization quality, and cognitive load distribution, while incorporating adaptive learning mechanisms for continuous persona refinement. By integrating fine-grained agent specialization with cooperative retrieval, SPARK provides insights for next-generation search systems capable of capturing the complexity, fluidity, and context sensitivity of human information-seeking behavior.
A Dimensionality-Reduced XAI Framework for Roundabout Crash Severity Insights
Sep 15, 2025Roundabouts reduce severe crashes, yet risk patterns vary by conditions. This study analyzes 2017-2021 Ohio roundabout crashes using a two-step, explainable workflow. Cluster Correspondence Analysis (CCA) identifies co-occurring factors and yields four crash patterns. A tree-based severity model is then interpreted with SHAP to quantify drivers of injury within and across patterns. Results show higher severity when darkness, wet surfaces, and higher posted speeds coincide with fixed-object or angle events, and lower severity in clear, low-speed settings. Pattern-specific explanations highlight mechanisms at entries (fail-to-yield, gap acceptance), within multi-lane circulation (improper maneuvers), and during slow-downs (rear-end). The workflow links pattern discovery with case-level explanations, supporting site screening, countermeasure selection, and audit-ready reporting. The contribution to Information Systems is a practical template for usable XAI in public safety analytics.
Model Context Protocols in Adaptive Transport Systems: A Survey
Aug 26, 2025The rapid expansion of interconnected devices, autonomous systems, and AI applications has created severe fragmentation in adaptive transport systems, where diverse protocols and context sources remain isolated. This survey provides the first systematic investigation of the Model Context Protocol (MCP) as a unifying paradigm, highlighting its ability to bridge protocol-level adaptation with context-aware decision making. Analyzing established literature, we show that existing efforts have implicitly converged toward MCP-like architectures, signaling a natural evolution from fragmented solutions to standardized integration frameworks. We propose a five-category taxonomy covering adaptive mechanisms, context-aware frameworks, unification models, integration strategies, and MCP-enabled architectures. Our findings reveal three key insights: traditional transport protocols have reached the limits of isolated adaptation, MCP's client-server and JSON-RPC structure enables semantic interoperability, and AI-driven transport demands integration paradigms uniquely suited to MCP. Finally, we present a research roadmap positioning MCP as a foundation for next-generation adaptive, context-aware, and intelligent transport infrastructures.
ST-GraphNet: A Spatio-Temporal Graph Neural Network for Understanding and Predicting Automated Vehicle Crash Severity
Jun 09, 2025Understanding the spatial and temporal dynamics of automated vehicle (AV) crash severity is critical for advancing urban mobility safety and infrastructure planning. In this work, we introduce ST-GraphNet, a spatio-temporal graph neural network framework designed to model and predict AV crash severity by using both fine-grained and region-aggregated spatial graphs. Using a balanced dataset of 2,352 real-world AV-related crash reports from Texas (2024), including geospatial coordinates, crash timestamps, SAE automation levels, and narrative descriptions, we construct two complementary graph representations: (1) a fine-grained graph with individual crash events as nodes, where edges are defined via spatio-temporal proximity; and (2) a coarse-grained graph where crashes are aggregated into Hexagonal Hierarchical Spatial Indexing (H3)-based spatial cells, connected through hexagonal adjacency. Each node in the graph is enriched with multimodal data, including semantic, spatial, and temporal attributes, including textual embeddings from crash narratives using a pretrained Sentence-BERT model. We evaluate various graph neural network (GNN) architectures, such as Graph Convolutional Networks (GCN), Graph Attention Networks (GAT), and Dynamic Spatio-Temporal GCN (DSTGCN), to classify crash severity and predict high-risk regions. Our proposed ST-GraphNet, which utilizes a DSTGCN backbone on the coarse-grained H3 graph, achieves a test accuracy of 97.74\%, substantially outperforming the best fine-grained model (64.7\% test accuracy). These findings highlight the effectiveness of spatial aggregation, dynamic message passing, and multi-modal feature integration in capturing the complex spatio-temporal patterns underlying AV crash severity.
Comparative Analysis of Advanced AI-based Object Detection Models for Pavement Marking Quality Assessment during Daytime
Mar 17, 2025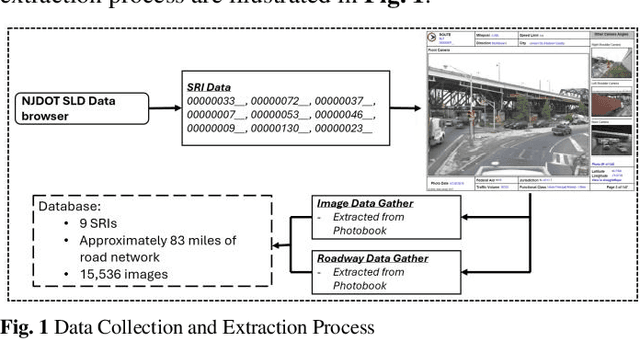
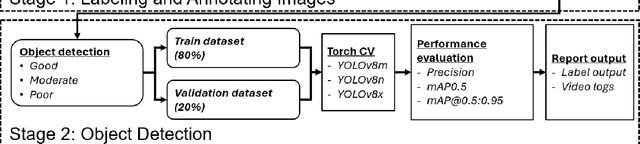
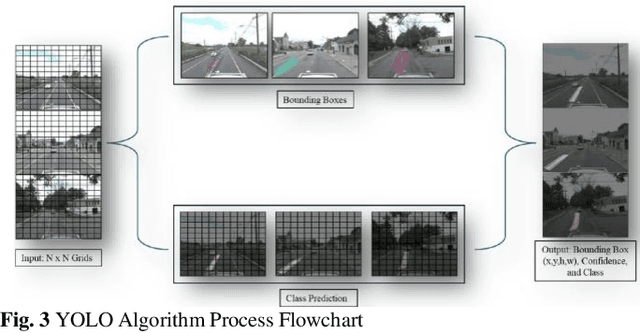

Visual object detection utilizing deep learning plays a vital role in computer vision and has extensive applications in transportation engineering. This paper focuses on detecting pavement marking quality during daytime using the You Only Look Once (YOLO) model, leveraging its advanced architectural features to enhance road safety through precise and real-time assessments. Utilizing image data from New Jersey, this study employed three YOLOv8 variants: YOLOv8m, YOLOv8n, and YOLOv8x. The models were evaluated based on their prediction accuracy for classifying pavement markings into good, moderate, and poor visibility categories. The results demonstrated that YOLOv8n provides the best balance between accuracy and computational efficiency, achieving the highest mean Average Precision (mAP) for objects with good visibility and demonstrating robust performance across various Intersections over Union (IoU) thresholds. This research enhances transportation safety by offering an automated and accurate method for evaluating the quality of pavement markings.
Crash Severity Analysis of Child Bicyclists using Arm-Net and MambaNet
Mar 14, 2025Child bicyclists (14 years and younger) are among the most vulnerable road users, often experiencing severe injuries or fatalities in crashes. This study analyzed 2,394 child bicyclist crashes in Texas from 2017 to 2022 using two deep tabular learning models (ARM-Net and MambaNet). To address the issue of data imbalance, the SMOTEENN technique was applied, resulting in balanced datasets that facilitated accurate crash severity predictions across three categories: Fatal/Severe (KA), Moderate/Minor (BC), and No Injury (O). The findings revealed that MambaNet outperformed ARM-Net, achieving higher precision, recall, F1-scores, and accuracy, particularly in the KA and O categories. Both models highlighted challenges in distinguishing BC crashes due to overlapping characteristics. These insights underscored the value of advanced tabular deep learning methods and balanced datasets in understanding crash severity. While limitations such as reliance on categorical data exist, future research could explore continuous variables and real-time behavioral data to enhance predictive modeling and crash mitigation strategies.
Applying Tabular Deep Learning Models to Estimate Crash Injury Types of Young Motorcyclists
Mar 13, 2025Young motorcyclists, particularly those aged 15 to 24 years old, face a heightened risk of severe crashes due to factors such as speeding, traffic violations, and helmet usage. This study aims to identify key factors influencing crash severity by analyzing 10,726 young motorcyclist crashes in Texas from 2017 to 2022. Two advanced tabular deep learning models, ARMNet and MambaNet, were employed, using an advanced resampling technique to address class imbalance. The models were trained to classify crashes into three severity levels, Fatal or Severe, Moderate or Minor, and No Injury. ARMNet achieved an accuracy of 87 percent, outperforming 86 percent of Mambanet, with both models excelling in predicting severe and no injury crashes while facing challenges in moderate crash classification. Key findings highlight the significant influence of demographic, environmental, and behavioral factors on crash outcomes. The study underscores the need for targeted interventions, including stricter helmet enforcement and educational programs customized to young motorcyclists. These insights provide valuable guidance for policymakers in developing evidence-based strategies to enhance motorcyclist safety and reduce crash severity.
A Survey on Kolmogorov-Arnold Network
Nov 09, 2024This systematic review explores the theoretical foundations, evolution, applications, and future potential of Kolmogorov-Arnold Networks (KAN), a neural network model inspired by the Kolmogorov-Arnold representation theorem. KANs distinguish themselves from traditional neural networks by using learnable, spline-parameterized functions instead of fixed activation functions, allowing for flexible and interpretable representations of high-dimensional functions. This review details KAN's architectural strengths, including adaptive edge-based activation functions that improve parameter efficiency and scalability in applications such as time series forecasting, computational biomedicine, and graph learning. Key advancements, including Temporal-KAN, FastKAN, and Partial Differential Equation (PDE) KAN, illustrate KAN's growing applicability in dynamic environments, enhancing interpretability, computational efficiency, and adaptability for complex function approximation tasks. Additionally, this paper discusses KAN's integration with other architectures, such as convolutional, recurrent, and transformer-based models, showcasing its versatility in complementing established neural networks for tasks requiring hybrid approaches. Despite its strengths, KAN faces computational challenges in high-dimensional and noisy data settings, motivating ongoing research into optimization strategies, regularization techniques, and hybrid models. This paper highlights KAN's role in modern neural architectures and outlines future directions to improve its computational efficiency, interpretability, and scalability in data-intensive applications.