 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Deep Tabular Learning
Paper and Code
Oct 15, 2024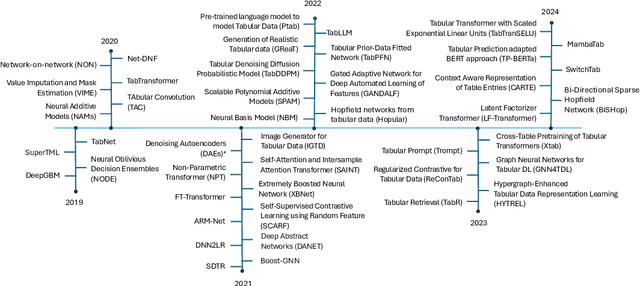
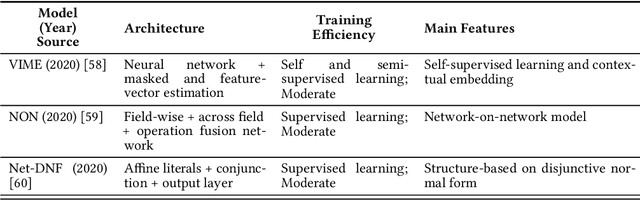
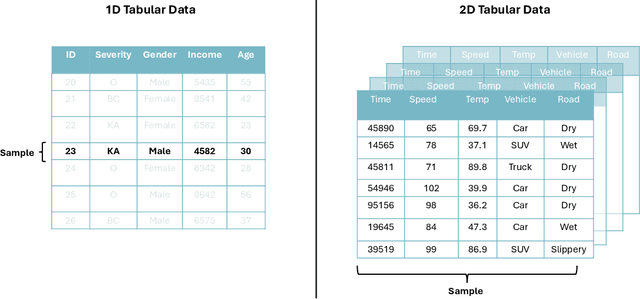
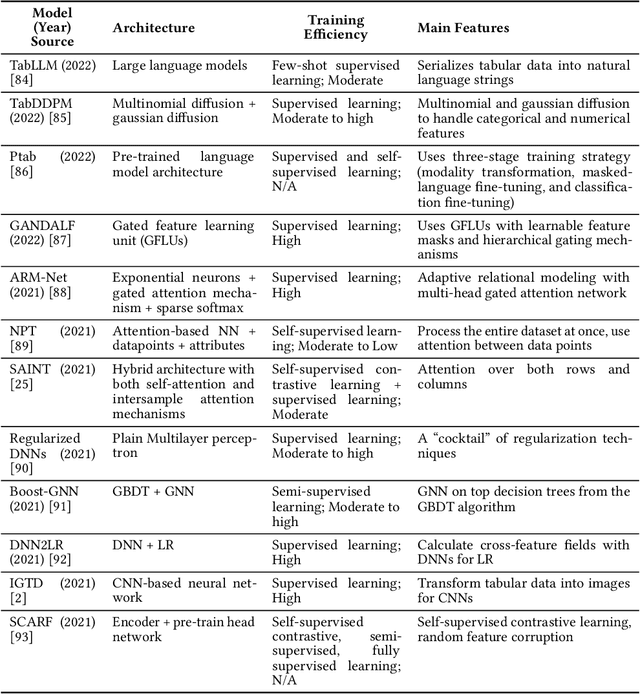
Tabular data, widely used in industries like healthcare, finance, and transportation, presents unique challenges for deep learning due to its heterogeneous nature and lack of spatial structure. This survey reviews the evolution of deep learning models for tabular data, from early fully connected networks (FCNs) to advanced architectures like TabNet, SAINT, TabTranSELU, and MambaNet. These models incorporate attention mechanisms, feature embeddings, and hybrid architectures to address tabular data complexities. TabNet uses sequential attention for instance-wise feature selection, improving interpretability, while SAINT combines self-attention and intersample attention to capture complex interactions across features and data points, both advancing scalability and reducing computational overhead. Hybrid architectures such as TabTransformer and FT-Transformer integrate attention mechanisms with multi-layer perceptrons (MLPs) to handle categorical and numerical data, with FT-Transformer adapting transformers for tabular datasets. Research continues to balance performance and efficiency for large datasets. Graph-based models like GNN4TDL and GANDALF combine neural networks with decision trees or graph structures, enhancing feature representation and mitigating overfitting in small datasets through advanced regularization techniques. Diffusion-based models like the Tabular Denoising Diffusion Probabilistic Model (TabDDPM) generate synthetic data to address data scarcity, improving model robustness. Similarly, models like TabPFN and Ptab leverage pre-trained language models, incorporating transfer learning and self-supervised techniques into tabular tasks. This survey highlights key advancements and outlines future research directions on scalability, generalization, and interpretability in diverse tabular data applications.