 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiameseDuo++: Active Learning from Data Streams with Dual Augmented Siamese Networks
Apr 06, 2025



Data stream mining, also known as stream learning, is a growing area which deals with learning from high-speed arriving data. Its relevance has surged recently due to its wide range of applicability, such as, critical infrastructure monitoring, social media analysis, and recommender systems. The design of stream learning methods faces significant research challenges; from the nonstationary nature of the data (referred to as concept drift) and the fact that data streams are typically not annotated with the ground truth, to the requirement that such methods should process large amounts of data in real-time with limited memory. This work proposes the SiameseDuo++ method, which uses active learning to automatically select instances for a human expert to label according to a budget. Specifically, it incrementally trains two siamese neural networks which operate in synergy, augmented by generated examples. Both the proposed active learning strategy and augmentation operate in the latent space. SiameseDuo++ addresses the aforementioned challenges by operating with limited memory and limited labelling budget. Simulation experiments show that the proposed method outperforms strong baselines and state-of-the-art methods in terms of learning speed and/or performance. To promote open science we publicly release our code and datasets.
Data augmentation on-the-fly and active learning in data stream classification
Oct 13, 2022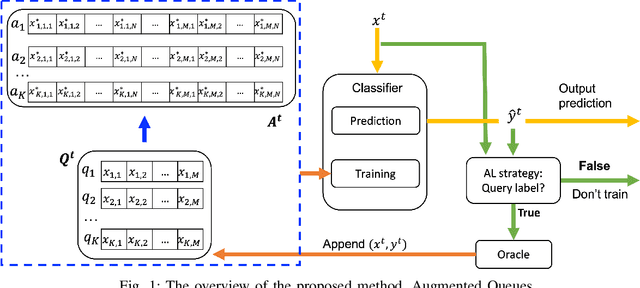

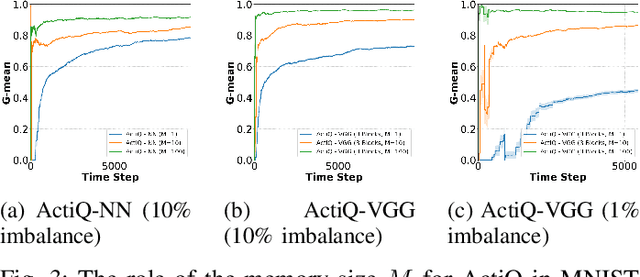

There is an emerging need for predictive models to be trained on-the-fly, since in numerous machine learning applications data are arriving in an online fashion. A critical challenge encountered is that of limited availability of ground truth information (e.g., labels in classification tasks) as new data are observed one-by-one online, while another significant challenge is that of class imbalance. This work introduces the novel Augmented Queues method, which addresses the dual-problem by combining in a synergistic manner online active learning, data augmentation, and a multi-queue memory to maintain separate and balanced queues for each class. We perform an extensive experimental study using image and time-series augmentations, in which we examine the roles of the active learning budget, memory size, imbalance level, and neural network type. We demonstrate two major advantages of Augmented Queues. First, it does not reserve additional memory space as the generation of synthetic data occurs only at training times. Second, learning models have access to more labelled data without the need to increase the active learning budget and / or the original memory size. Learning on-the-fly poses major challenges which, typically, hinder the deployment of learning models. Augmented Queues significantly improves the performance in terms of learning quality and speed. Our code is made publicly available.
* Keywords: incremental learning, active learning, data streams, class imbalance, neural networks