 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Randomized Dimension Reduction on Massive Data
Apr 13, 2015
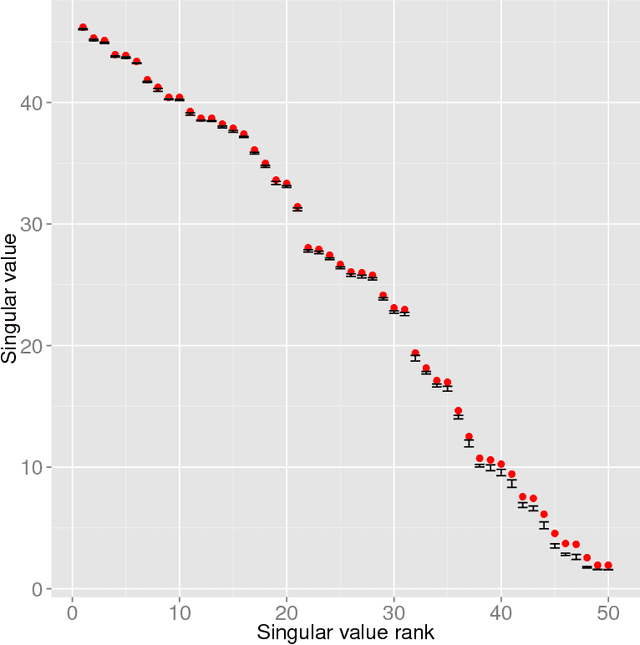

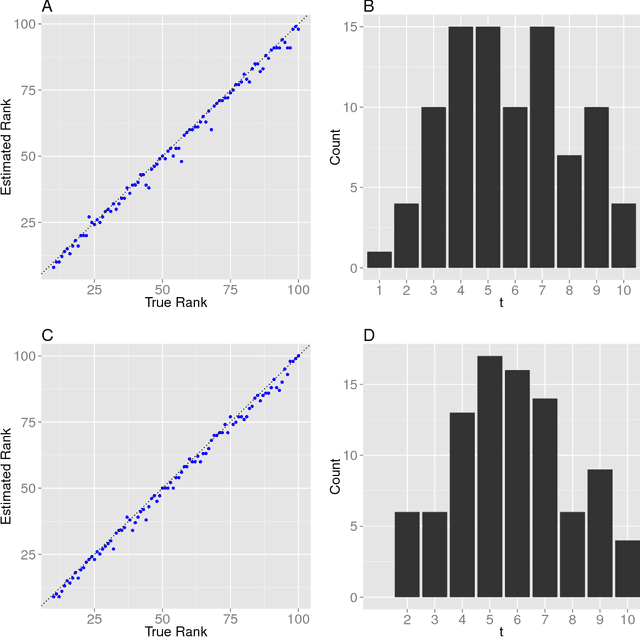
The scalability of statistical estimators is of increasing importance in modern applications. One approach to implementing scalable algorithms is to compress data into a low dimensional latent space using dimension reduction methods. In this paper we develop an approach for dimension reduction that exploits the assumption of low rank structure in high dimensional data to gain both computational and statistical advantages. We adapt recent randomized low-rank approximation algorithms to provide an efficient solution to principal component analysis (PCA), and we use this efficient solver to improve parameter estimation in large-scale linear mixed models (LMM) for association mapping in statistical and quantitative genomics. A key observation in this paper is that randomization serves a dual role, improving both computational and statistical performance by implicitly regularizing the covariance matrix estimate of the random effect in a LMM. These statistical and computational advantages are highlighted in our experiments on simulated data and large-scale genomic studies.
Randomized Dimension Reduction on Massive Data
Nov 05, 2013
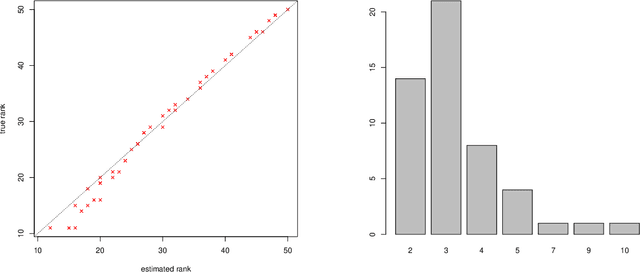


Scalability of statistical estimators is of increasing importance in modern applications and dimension reduction is often used to extract relevant information from data. A variety of popular dimension reduction approaches can be framed as symmetric generalized eigendecomposition problems. In this paper we outline how taking into account the low rank structure assumption implicit in these dimension reduction approaches provides both computational and statistical advantages. We adapt recent randomized low-rank approximation algorithms to provide efficient solutions to three dimension reduction methods: Principal Component Analysis (PCA), Sliced Inverse Regression (SIR), and Localized Sliced Inverse Regression (LSIR). A key observation in this paper is that randomization serves a dual role, improving both computational and statistical performance. This point is highlighted in our experiments on real and simulated data.