 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly detection in radio galaxy data with trainable COSFIRE filters
May 24, 2025

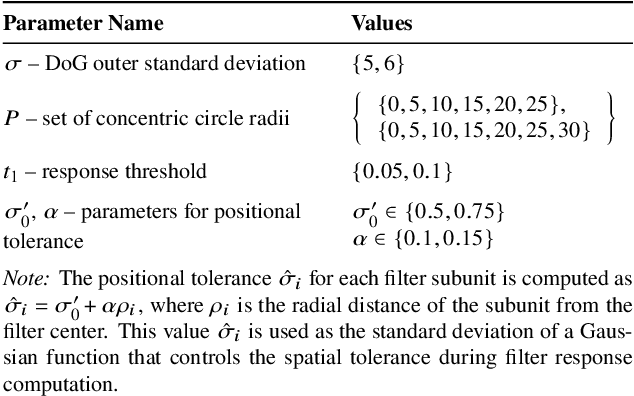

Detecting anomalies in radio astronomy is challenging due to the vast amounts of data and the rarity of labeled anomalous examples. Addressing this challenge requires efficient methods capable of identifying unusual radio galaxy morphologies without relying on extensive supervision. This work introduces an innovative approach to anomaly detection based on morphological characteristics of the radio sources using trainable COSFIRE (Combination of Shifted Filter Responses) filters as an efficient alternative to complex deep learning methods. The framework integrates COSFIRE descriptors with an unsupervised Local Outlier Factor (LOF) algorithm to identify unusual radio galaxy morphologies. Evaluations on a radio galaxy benchmark data set demonstrate strong performance, with the COSFIRE-based approach achieving a geometric mean (G-Mean) score of 79%, surpassing the 77% achieved by a computationally intensive deep learning autoencoder. By characterizing normal patterns and detecting deviations, this semi-supervised methodology overcomes the need for anomalous examples in the training set, a major limitation of traditional supervised methods. This approach shows promise for next-generation radio telescopes, where fast processing and the ability to discover unknown phenomena are crucial.
State of NLP in Kenya: A Survey
Oct 13, 2024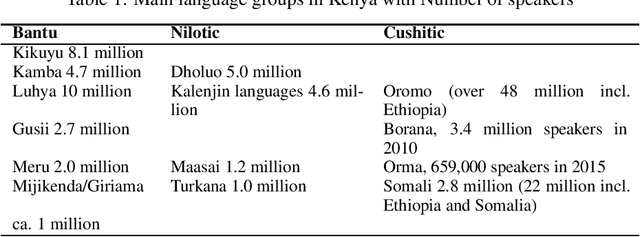
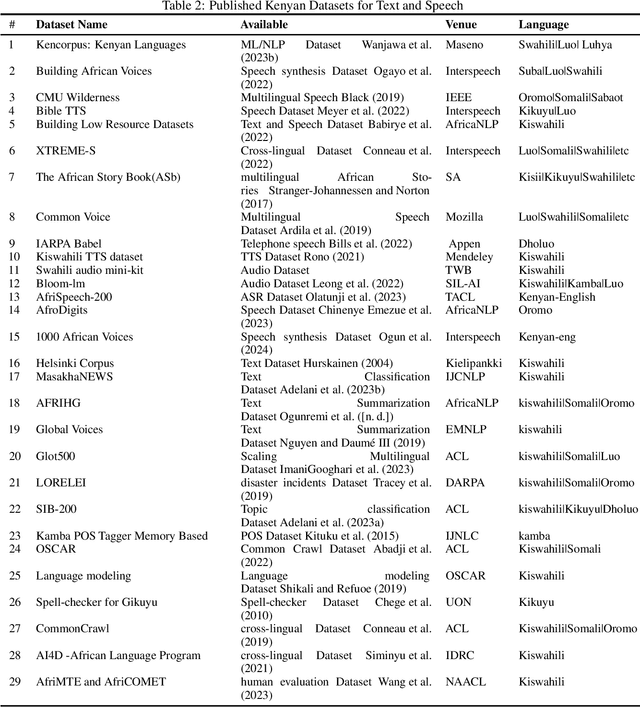
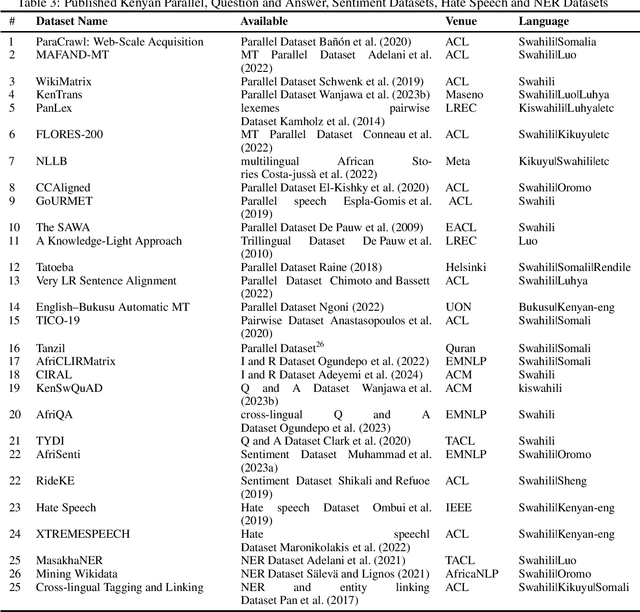
Kenya, known for its linguistic diversity, faces unique challenges and promising opportunities in advancing Natural Language Processing (NLP) technologies, particularly for its underrepresented indigenous languages. This survey provides a detailed assessment of the current state of NLP in Kenya, emphasizing ongoing efforts in dataset creation, machine translation, sentiment analysis, and speech recognition for local dialects such as Kiswahili, Dholuo, Kikuyu, and Luhya. Despite these advancements, the development of NLP in Kenya remains constrained by limited resources and tools, resulting in the underrepresentation of most indigenous languages in digital spaces. This paper uncovers significant gaps by critically evaluating the available datasets and existing NLP models, most notably the need for large-scale language models and the insufficient digital representation of Indigenous languages. We also analyze key NLP applications: machine translation, information retrieval, and sentiment analysis-examining how they are tailored to address local linguistic needs. Furthermore, the paper explores the governance, policies, and regulations shaping the future of AI and NLP in Kenya and proposes a strategic roadmap to guide future research and development efforts. Our goal is to provide a foundation for accelerating the growth of NLP technologies that meet Kenya's diverse linguistic demands.
Deep supervised hashing for fast retrieval of radio image cubes
Sep 02, 2023The shear number of sources that will be detected by next-generation radio surveys will be astronomical, which will result in serendipitous discoveries. Data-dependent deep hashing algorithms have been shown to be efficient at image retrieval tasks in the fields of computer vision and multimedia. However, there are limited applications of these methodologies in the field of astronomy. In this work, we utilize deep hashing to rapidly search for similar images in a large database. The experiment uses a balanced dataset of 2708 samples consisting of four classes: Compact, FRI, FRII, and Bent. The performance of the method was evaluated using the mean average precision (mAP) metric where a precision of 88.5\% was achieved. The experimental results demonstrate the capability to search and retrieve similar radio images efficiently and at scale. The retrieval is based on the Hamming distance between the binary hash of the query image and those of the reference images in the database.
Advances on the classification of radio image cubes
May 05, 2023



Modern radio telescopes will daily generate data sets on the scale of exabytes for systems like the Square Kilometre Array (SKA). Massive data sets are a source of unknown and rare astrophysical phenomena that lead to discoveries. Nonetheless, this is only plausible with the exploitation of intensive machine intelligence to complement human-aided and traditional statistical techniques. Recently, there has been a surge in scientific publications focusing on the use of artificial intelligence in radio astronomy, addressing challenges such as source extraction, morphological classification, and anomaly detection. This study presents a succinct, but comprehensive review of the application of machine intelligence techniques on radio images with emphasis on the morphological classification of radio galaxies. It aims to present a detailed synthesis of the relevant papers summarizing the literature based on data complexity, data pre-processing, and methodological novelty in radio astronomy. The rapid advancement and application of computer intelligence in radio astronomy has resulted in a revolution and a new paradigm shift in the automation of daunting data processes. However, the optimal exploitation of artificial intelligence in radio astronomy, calls for continued collaborative efforts in the creation of annotated data sets. Additionally, in order to quickly locate radio galaxies with similar or dissimilar physical characteristics, it is necessary to index the identified radio sources. Nonetheless, this issue has not been adequately addressed in the literature, making it an open area for further study.