 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Knowledge Graphs Towards a Global Food Systems Datahub
Feb 26, 2025Sustainable agricultural production aligns with several sustainability goals established by the United Nations (UN). However, there is a lack of studies that comprehensively examine sustainable agricultural practices across various products and production methods. Such research could provide valuable insights into the diverse factors influencing the sustainability of specific crops and produce while also identifying practices and conditions that are universally applicable to all forms of agricultural production. While this research might help us better understand sustainability, the community would still need a consistent set of vocabularies. These consistent vocabularies, which represent the underlying datasets, can then be stored in a global food systems datahub. The standardized vocabularies might help encode important information for further statistical analyses and AI/ML approaches in the datasets, resulting in the research targeting sustainable agricultural production. A structured method of representing information in sustainability, especially for wheat production, is currently unavailable. In an attempt to address this gap, we are building a set of ontologies and Knowledge Graphs (KGs) that encode knowledge associated with sustainable wheat production using formal logic. The data for this set of knowledge graphs are collected from public data sources, experimental results collected at our experiments at Kansas State University, and a Sustainability Workshop that we organized earlier in the year, which helped us collect input from different stakeholders throughout the value chain of wheat. The modeling of the ontology (i.e., the schema) for the Knowledge Graph has been in progress with the help of our domain experts, following a modular structure using KNARM methodology. In this paper, we will present our preliminary results and schemas of our Knowledge Graph and ontologies.
PANDORA: The Open-Source, Structurally Elastic Humanoid Robot
Jul 26, 2024
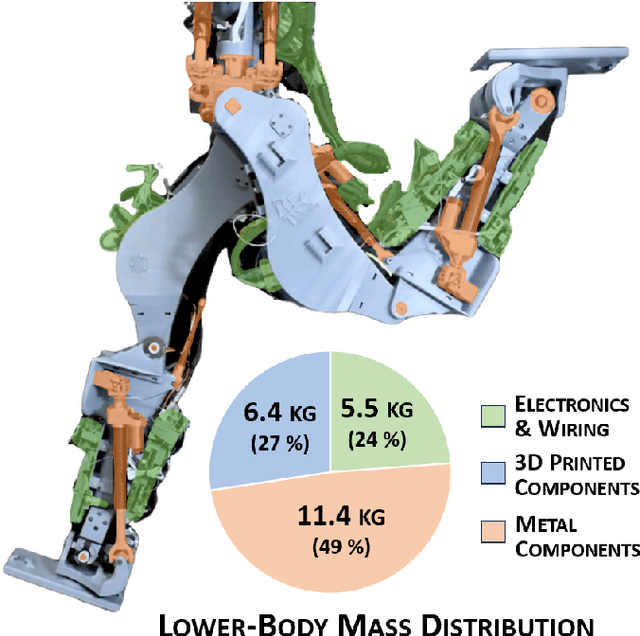
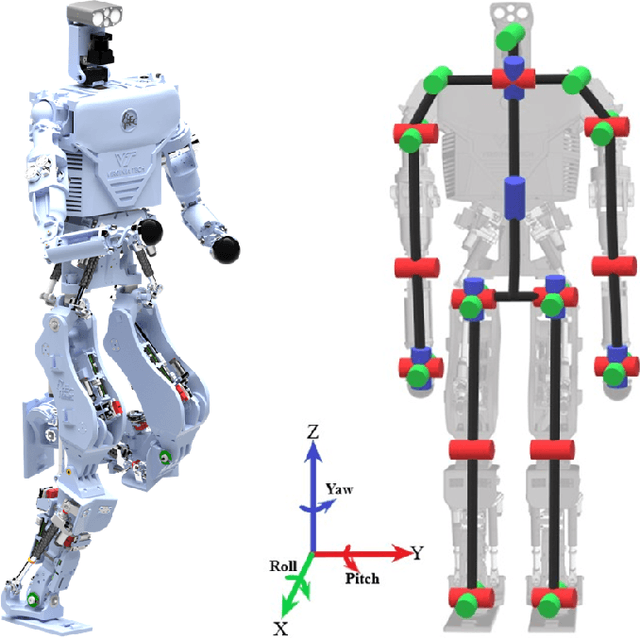
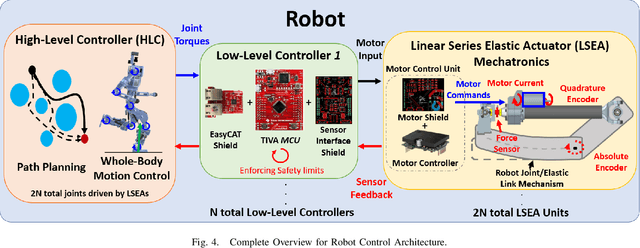
In this work, the novel, open-source humanoid robot, PANDORA, is presented where a majority of the structural elements are manufactured using 3D-printed compliant materials. As opposed to contemporary approaches that incorporate the elastic element into the actuator mechanisms, PANDORA is designed to be compliant under load, or in other words, structurally elastic. This design approach lowers manufacturing cost and time, design complexity, and assembly time while introducing controls challenges in state estimation, joint and whole-body control. This work features an in-depth description on the mechanical and electrical subsystems including details regarding additive manufacturing benefits and drawbacks, usage and placement of sensors, and networking between devices. In addition, the design of structural elastic components and their effects on overall performance from an estimation and control perspective are discussed. Finally, results are presented which demonstrate the robot completing a robust balancing objective in the presence of disturbances and stepping behaviors.
Real-Time Model-Free Deep Reinforcement Learning for Force Control of a Series Elastic Actuator
Apr 11, 2023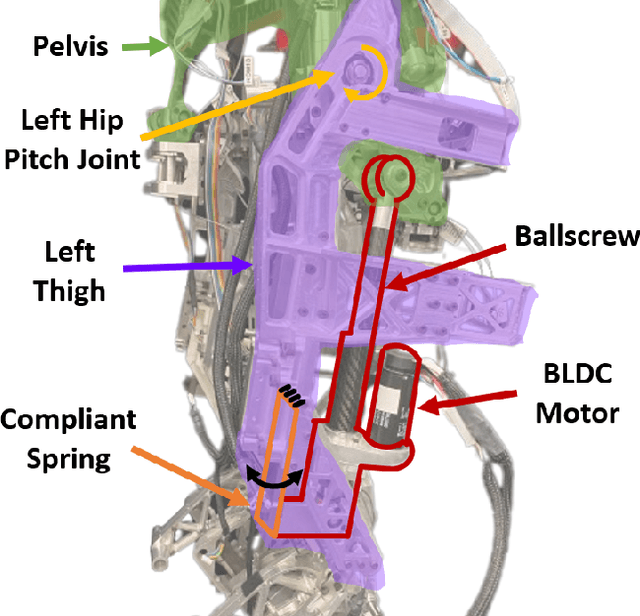
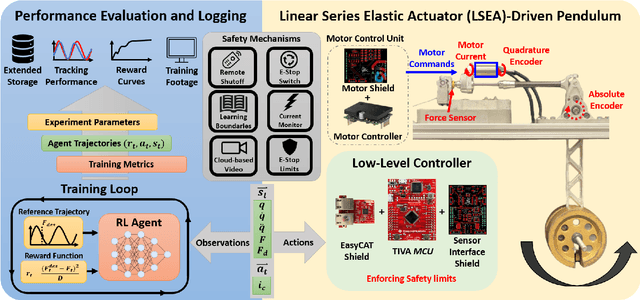
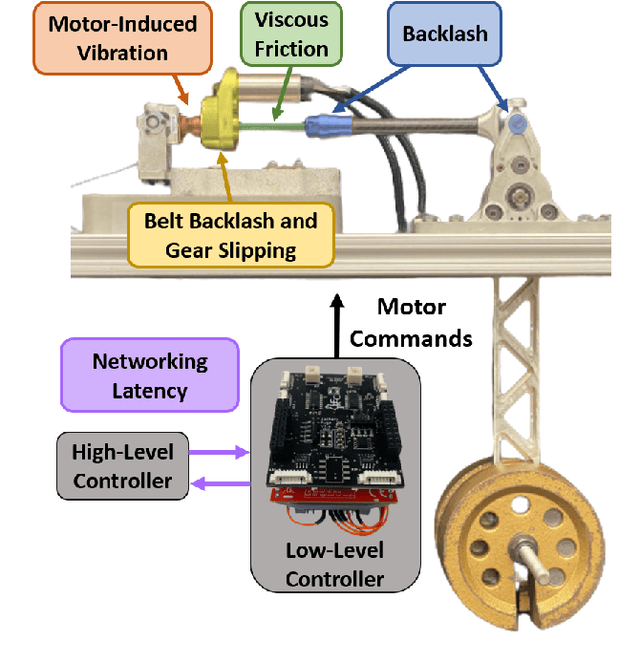
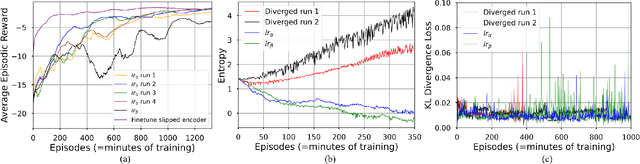
Many state-of-the art robotic applications utilize series elastic actuators (SEAs) with closed-loop force control to achieve complex tasks such as walking, lifting, and manipulation. Model-free PID control methods are more prone to instability due to nonlinearities in the SEA where cascaded model-based robust controllers can remove these effects to achieve stable force control. However, these model-based methods require detailed investigations to characterize the system accurately. Deep reinforcement learning (DRL) has proved to be an effective model-free method for continuous control tasks, where few works deal with hardware learning. This paper describes the training process of a DRL policy on hardware of an SEA pendulum system for tracking force control trajectories from 0.05 - 0.35 Hz at 50 N amplitude using the Proximal Policy Optimization (PPO) algorithm. Safety mechanisms are developed and utilized for training the policy for 12 hours (overnight) without an operator present within the full 21 hours training period. The tracking performance is evaluated showing improvements of $25$ N in mean absolute error when comparing the first 18 min. of training to the full 21 hours for a 50 N amplitude, 0.1 Hz sinusoid desired force trajectory. Finally, the DRL policy exhibits better tracking and stability margins when compared to a model-free PID controller for a 50 N chirp force trajectory.