 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Causal Inference with Incremental Observational Data
Mar 03, 2023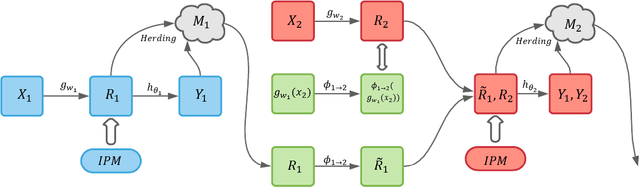
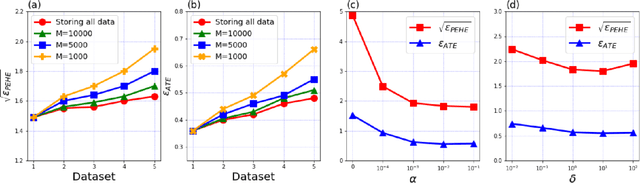
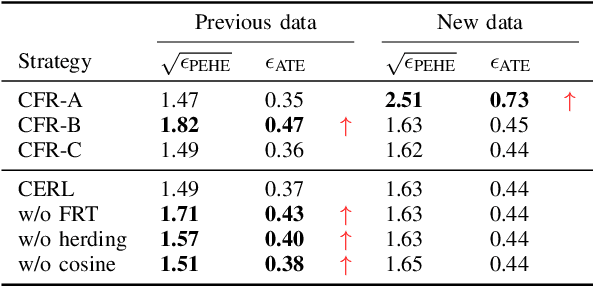
The era of big data has witnessed an increasing availability of observational data from mobile and social networking, online advertising, web mining, healthcare, education, public policy, marketing campaigns, and so on, which facilitates the development of causal effect estimation. Although significant advances have been made to overcome the challenges in the academic area, such as missing counterfactual outcomes and selection bias, they only focus on source-specific and stationary observational data, which is unrealistic in most industrial applications. In this paper, we investigate a new industrial problem of causal effect estimation from incrementally available observational data and present three new evaluation criteria accordingly, including extensibility, adaptability, and accessibility. We propose a Continual Causal Effect Representation Learning method for estimating causal effects with observational data, which are incrementally available from non-stationary data distributions. Instead of having access to all seen observational data, our method only stores a limited subset of feature representations learned from previous data. Combining selective and balanced representation learning, feature representation distillation, and feature transformation, our method achieves the continual causal effect estimation for new data without compromising the estimation capability for original data. Extensive experiments demonstrate the significance of continual causal effect estimation and the effectiveness of our method.
Learning Infomax and Domain-Independent Representations for Causal Effect Inference with Real-World Data
Feb 22, 2022
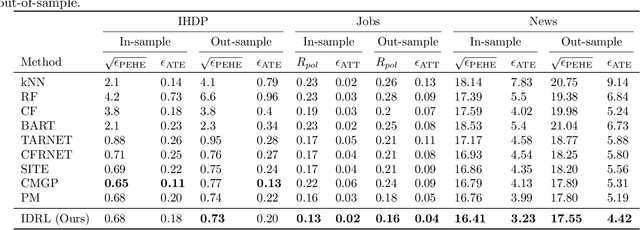

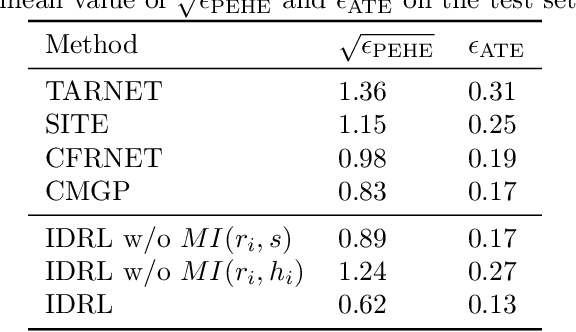
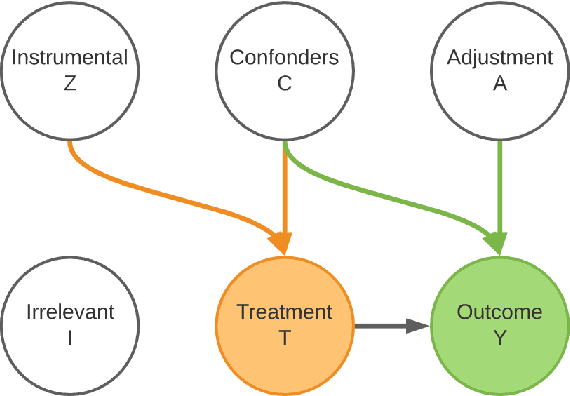
The foremost challenge to causal inference with real-world data is to handle the imbalance in the covariates with respect to different treatment options, caused by treatment selection bias. To address this issue, recent literature has explored domain-invariant representation learning based on different domain divergence metrics (e.g., Wasserstein distance, maximum mean discrepancy, position-dependent metric, and domain overlap). In this paper, we reveal the weaknesses of these strategies, i.e., they lead to the loss of predictive information when enforcing the domain invariance; and the treatment effect estimation performance is unstable, which heavily relies on the characteristics of the domain distributions and the choice of domain divergence metrics. Motivated by information theory, we propose to learn the Infomax and Domain-Independent Representations to solve the above puzzles. Our method utilizes the mutual information between the global feature representations and individual feature representations, and the mutual information between feature representations and treatment assignment predictions, in order to maximally capture the common predictive information for both treatment and control groups. Moreover, our method filters out the influence of instrumental and irrelevant variables, and thus it effectively increases the predictive ability of potential outcomes. Experimental results on both the synthetic and real-world datasets show that our method achieves state-of-the-art performance on causal effect inference. Moreover, our method exhibits reliable prediction performances when facing data with different characteristics of data distributions, complicated variable types, and severe covariate imbalance.